Public Docs
【模型量化】深度学习模型量化 & 量化理论 & 各平台的量化过程 & 硬件加速
【TVM】TI关于TVM的使用测试与分析
【LLM&LVM】大模型开源工程思维导图
SmartSip
【北航卓越工程师】《汽车前沿技术导论:智能驾驶》讲义
【工具链】Yocto使用介绍——使用Yocto创建一个树莓派的系统镜像
【工具链】使用ssh+dialog指令设定服务器指定用户仅容器访问
【推理引擎】一篇关于模型推理的详细对比与学习
【推理引擎】关于TVM中的Schedule优化详解(On going)
【LLM微调】使用litgpt进行私有数据集模型微调的测试总结
【TVM】在TVM Relay中创建一个自定义操作符
【STT+LLM+TTS】如何使用语音转文字模型+大预言模型+语音生成模型完成一个类人的语音交互机器人
【RAG】 通过RAG构建垂直领域的LLM Agent的方法探索
【RAG】GraphRAG精读与测试(On going)
【AI Agent】MetaGPT精读与学习
【AI Base】Ilya Sutskever 27篇必读论文分享清单
【Nvidia】Jetson AGX Orin/ Jetson Orin nano 硬件测试调试内容(On going)
【BI/DI】LLM Using in BI Testing Scenario (On going)
【Nvidia】How to Activate a Camera on Nvidia Platform in Details
【RAS-PI】树莓派驱动开发
【行业咨询阅读】关注实时咨询和分析
【mobileye】2024 Driving AI
【mobileye】SDS_Safety_Architecture
【yolo】yolov8测试
【nvidia】Triton server实践
【alibaba】MNN(on updating)
【OpenAI】Triton(on updating)
【CAIS】关于Compound AI Systems的思考
【Nvidia】关于Cuda+Cudnn+TensorRT推理环境
【BEV】BEVDet在各个平台上的执行效率及优化(On Updating)
【Chip】AI在芯片设计和电路设计中的应用
【Chip】ChiPFormer
【Chip】关于布线的学习
【Chip】MaskPlace论文精读与工程复现优化
【gynasium】强化学习初体验
【Cadence】X AI
【transformer】MinGPT开源工程学习
【中间件】针对apollo 10.0中关于cyberRT性能优化的深度解读和思考
【Robotics】调研了解当前机器人开发者套件(on updating)
【Robotics】ROS CON China 2024 文档技术整理与感想总结(上2024.12.7,中2024.12.8,下场外产品)
【algorithm】关于模型、数据与标注规范的平衡问题
【nvidia】DLA的学习了解与使用
【nvidia】构建nvidia嵌入式平台的交叉编译环境(其他环境平台可借鉴)
【2025AI生成式大会】2025大会个人总结
【Robotics】 Create Quadruped Robot RL FootStep Training Environment In IsaacLab
【Robotics】如何一个人较为完整的完成一个机器人系统软件算法层面的设计与开发
【VLM】读懂多模态大模型评价指标
【VLM】大模型部署的端侧部署性能与精度评估方法与分析
【Nvidia】Jetson Orin 平台VLM部署方法与指标评测
【Database】向量数据库
【SoC】性能与功耗评估
【MCP】MCP探索
【InnoFrance】一个“关于声音”的有趣项目
【Robotics】写给那些想要快速了解机器人或者具身智能的工程师们
【Robotics】open X Embodiment RT-X 数据集下载与使用和分析
【SKILLS】股票分析skill
【Robotics】当 AI + 强化学习重来时,那些"老机械结构"值得再做一遍
【LLM&VLM】国产CPU+国产NPU+国产操作系统搭建一个持续不断给AI喂资料的系统
文档发布于【Feng's Docs】
-
+
首页
【Nvidia】关于Cuda+Cudnn+TensorRT推理环境
# 1.Brief 如果要使用CPP进行基于TensorRT的相关深度学习推理应用的开发,首先需要搭建具备满足条件的环境,这里面如果是初次使用会遇到一系列的问题,本文将对Nvidia各个平台上如果搭建并确认做一个详细的说明,以确保环境问题不会成为部署的卡点。 # 2.Jetson系列平台 关于Jetson平台相关的操作其实比较简单,可以直接使用SDKManager,勾选相关版本的程序进行并安装即可。关于如何验证成功安装在`服务器安装的环节`一并说明。 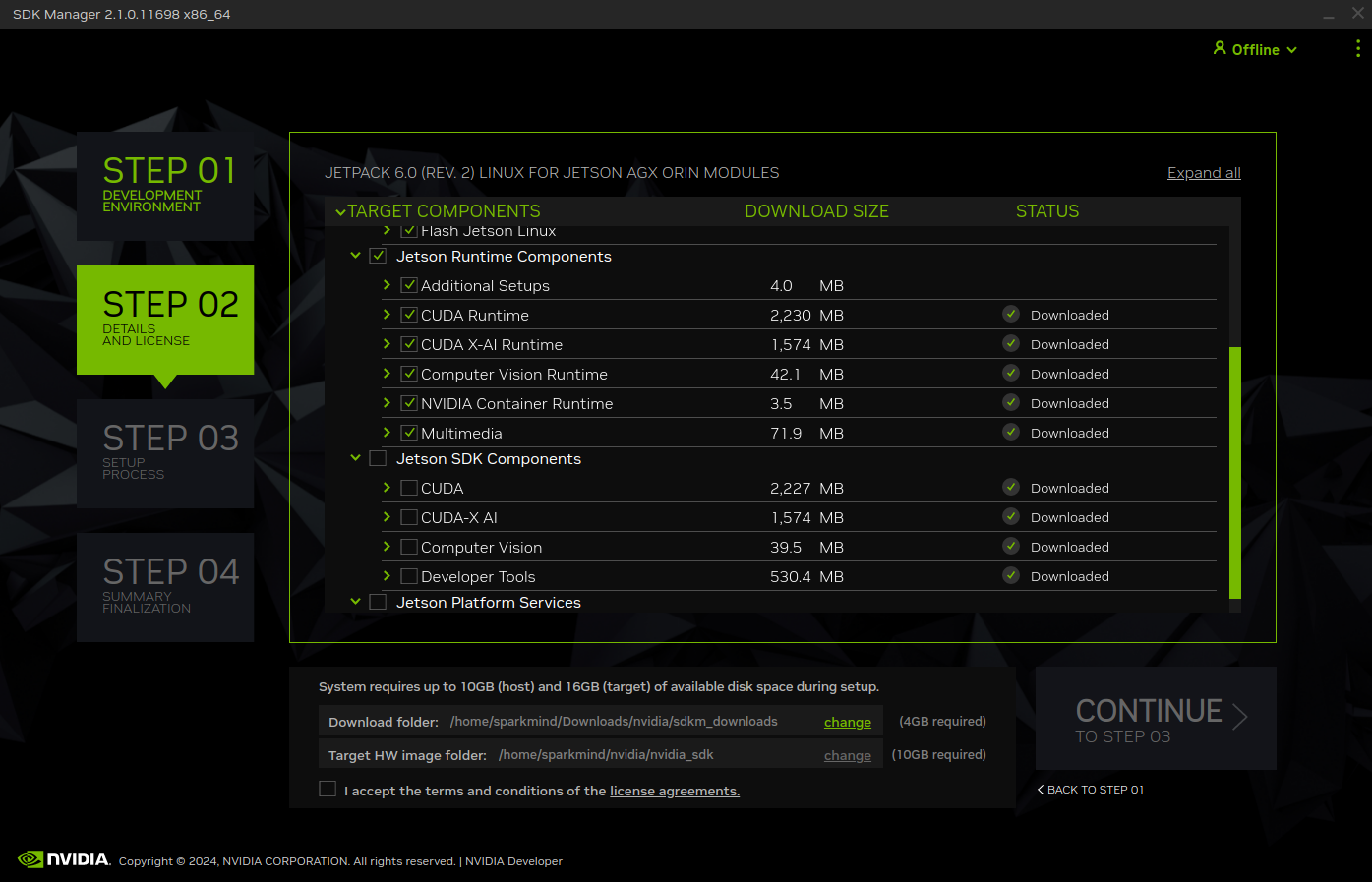 # 3.服务器上安装 ## 3.1. CUDA安装 通常可以使用ppa的方式安装显卡驱动,当完成安装后可以使用nvidia-smi进行查看。注意CUDA Version就表示驱动版本所对应要安装的CUDA版本,这个显示并不意味着你已经安装了cuda。 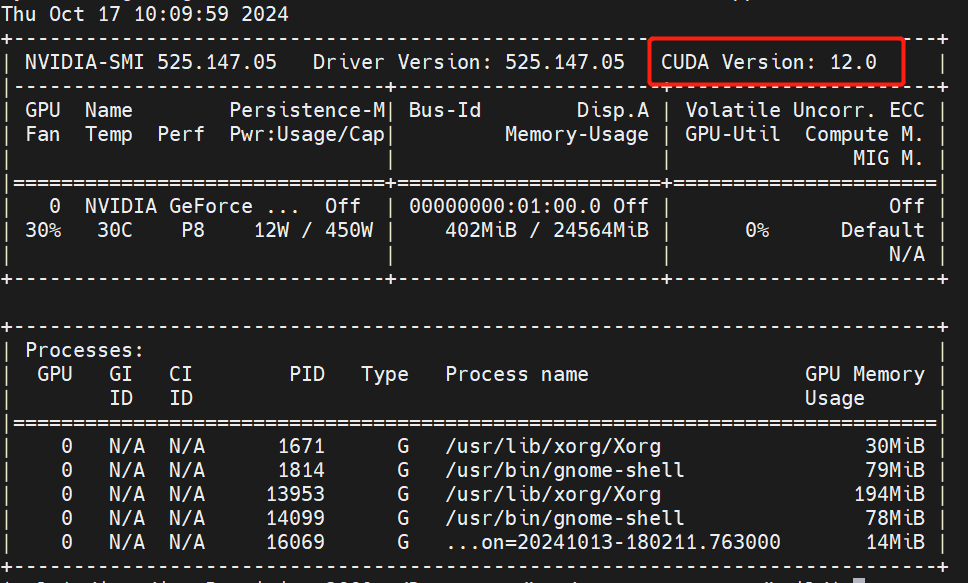 * 1. 可以使用dpkg -l|grep cuda进行检查, `dpkg -l|grep cuda` * 2. 如果直接使用apt install nvidia-cuda-toolkit可能并不一定能够安装到指定版本,甚至还可能因为添加了不当的镜像源出现,depends循环依赖的问题。可以看到这边默认安装的就是9.1.85的版本而非目标版本。 ``` bash # output # ii nvidia-cuda-dev 9.1.85-3ubuntu1 amd64 NVIDIA CUDA development files # ii nvidia-cuda-doc 9.1.85-3ubuntu1 all NVIDIA CUDA and OpenCL documentation # ii nvidia-cuda-gdb 9.1.85-3ubuntu1 amd64 NVIDIA CUDA Debugger (GDB) # ii nvidia-cuda-toolkit 9.1.85-3ubuntu1 ``` * 3. 推荐使用nvidia官方提供的方式进行网页端下载并安装,我这边是12.0的版本,直接官网搜索即可。https://developer.nvidia.com/cuda-12-0-0-download-archive?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=18.04&target_type=deb_local 。注意下载因为需要登录nvidia账户,所以可能并不一定能够使用wget 或者 curl进行命令行下载。下载完成后根据官方提供的指令进行安装即可。注意黄框种的指令有可能会因为之前有过其他版本从而出现gpg加载不正确无法执行下面一行apt install的情况。所以可以直接按照完整名称进行复制,而非使用通配符的方式。或者直接去指定目录进行`sudo dpkg -i *.deb`  4. 修改环境变量 ``` # Add the related bin and lib for cuda toolkit export PATH="/usr/local/cuda-12.0/bin:$PATH" export LD_LIBRARY_PATH="/usr/local/cuda-12.0/lib64:$LD_LIBRARY_PATH" ``` 然后使用`nvcc -V`检查版本是否正确 ``` nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2022 NVIDIA Corporation Built on Mon_Oct_24_19:12:58_PDT_2022 Cuda compilation tools, release 12.0, V12.0.76 Build cuda_12.0.r12.0/compiler.31968024_0 ``` ## 3.2. CuDNN安装 * 官网下载CUDA版本对应的CuDNN https://developer.nvidia.com/rdp/cudnn-archive 。选择CUDA版本对应的一个CuDNN就可以,==注意更高版本可以没有了对部分版本的支持入ubuntu18.04,所以一定确认你的操作系统版本+cuda版本和对应的CuDNN版本匹配==。 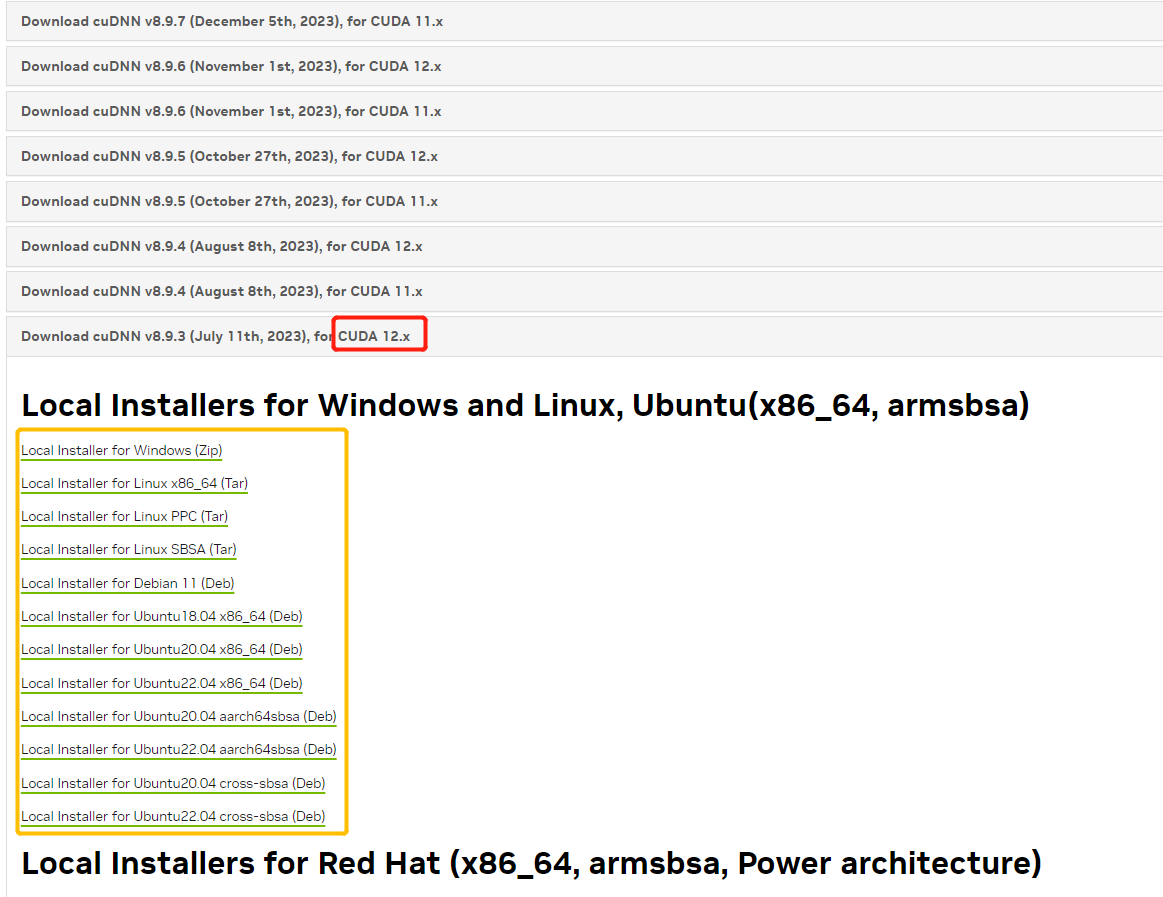 `deb文件安装后会弹出指令,解压后的所有deb文件库都出现在了指定目录,用CUDA种一样的gpg方式,或者直接去指定目录sudo dpkg -i *.deb,安装所有都可以` * `dpkg -l |grep cudnn`可以看到相关cudnn都已经安装 ``` ii cudnn-local-repo-ubuntu1804-8.9.3.28 1.0-1 amd64 cudnn-local repository configuration files ii libcudnn8 8.9.3.28-1+cuda12.1 amd64 cuDNN runtime libraries ii libcudnn8-dev 8.9.3.28-1+cuda12.1 amd64 cuDNN development libraries and headers ii libcudnn8-samples 8.9.3.28-1+cuda12.1 amd64 cuDNN samples ``` * 可以直接使用`mnist`样例确认cudnn是否正常,jetson平台相同。MNIST(Modified National Institute of Standards and Technology database)是一个广泛用于机器学习和深度学习的基准数据集。它包含了 60000 张手写数字(0-9)的训练图像和 10000 张测试图像,每张图像是 28x28 像素的灰度图像。 ``` cd /usr/src/cudnn_samples_v8/mnistCUDNN sudo make clean sudo make ./mnistCUDNN #输出出现Test passed!表示成功 ``` 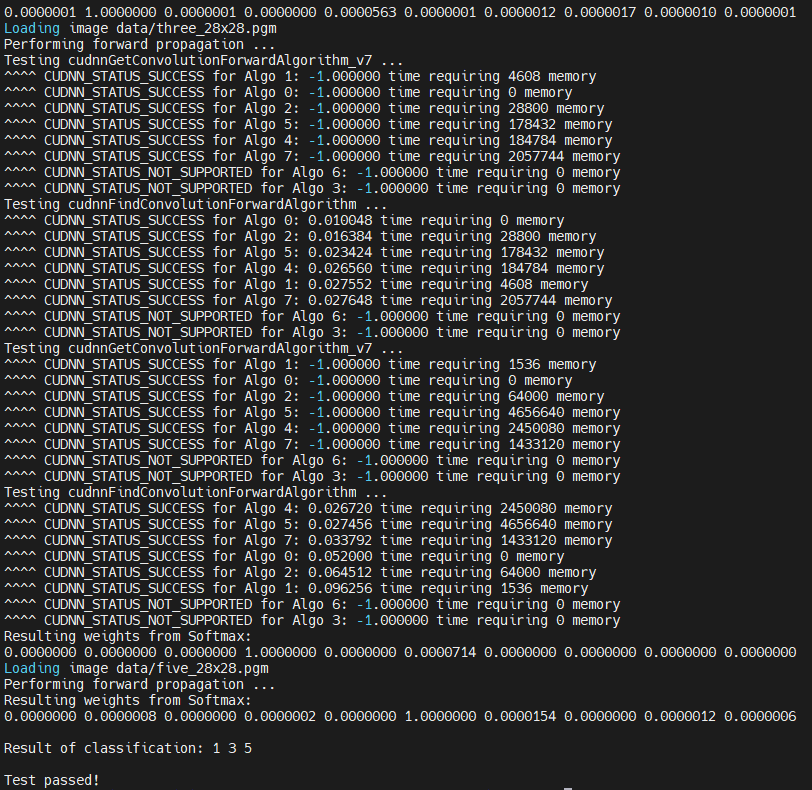 ## 3.3. TensorRT安装 * 官网下载指定版本 https://developer.nvidia.com/nvidia-tensorrt-8x-download 。注意GA(稳定版本)和EA(预发版本)的区别。 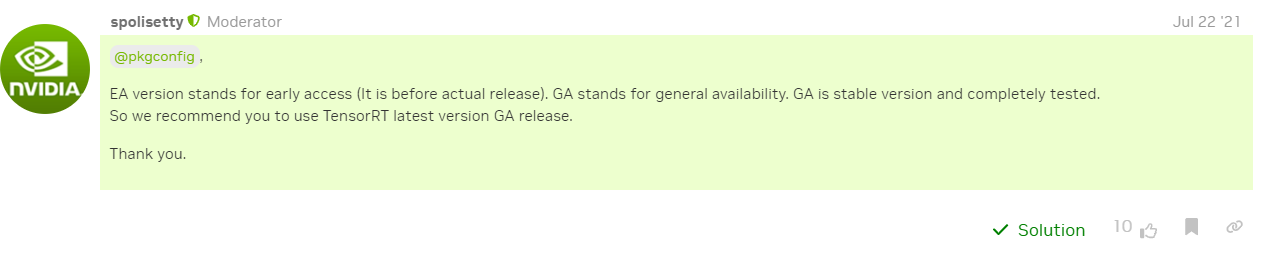 * deb安装会直接安装在如下位置,使用时指定路径即可。 ``` set(TENSORRT_INCLUDE_DIRS /usr/include/x86_64-linux-gnu/) set(TENSORRT_LIBRARY_DIRS /usr/lib/x86_64-linux-gnu/) # Jetson系列会在aarch64下 set(TENSORRT_INCLUDE_DIRS /usr/include/aarch64-linux-gnu/) set(TENSORRT_LIBRARY_DIRS /usr/lib/aarch64-linux-gnu/) ``` * 也可使用`dpkg -l |grep tensor`查看,或者直接搜所核心头文件和库确认 ``` sudo find / -name libnvinfer.so sudo find / -name NvInfer.h ``` * 也可以使用mnist进行验证 # 4. TensorRT代码样例分析 在nvidia平台上使用TensorRT时,模型加载阶段有两种思路,一种是直接加载通用onnx文件,在初始化阶段进行onnx to engine的序列化引擎操作,一种是通过手动通过trtexec完成序列化引擎操作,然后在代码执行时直接加载engine。下面是详细说明过程和对比,已经应用场景对比。 * 先说对比: |方面|第一种|第二种| |--|--|--| |主要功能|构建并序列化 TensorRT 引擎|加载已序列化的 TensorRT 引擎并进行推理| |流程步骤|创建构建器 → 定义网络 → 配置构建器 → 解析模型 → 构建引擎 → 序列化 → 反序列化|创建运行时 → 加载引擎 → 创建上下文 → 预处理输入 → 获取绑定索引| |适用阶段|引擎构建和优化阶段|引擎加载和推理部署阶段| |灵活性与控制|更高,适合需要详细控制和自定义构建流程的场景|简单快捷,适合直接加载和使用预构建引擎的场景| |依赖组件|依赖 ONNX 解析器和构建配置|依赖已存在的引擎文件| * 相关总结: * 引擎构建与序列化: 构建引擎过程耗时较长,建议在开发阶段完成,并将序列化的引擎文件保存下来,以便在部署时快速加载。 使用智能指针管理资源,避免内存泄漏和手动释放的复杂性。 * 引擎加载与推理: 在部署应用中,优先使用已序列化的引擎文件进行加载,提升启动速度和推理效率。 确保引擎文件与运行时环境(如 TensorRT 版本)兼容,避免反序列化失败。 * 性能优化: 在构建引擎时,合理配置优化选项(如 IBuilderConfig),根据硬件和应用需求选择合适的优化级别和精度(FP32、FP16、INT8)。 使用 CUDA 流和异步推理提升推理性能,尤其是在多线程或高并发场景下。 ## 4.1. 详细说明 * 对于第一种情况的代码样例 ``` c++ // 1. 创建构建器 auto builder = SampleUniquePtr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger())); if (!builder) { return false; } // 2. 定义网络 auto network = SampleUniquePtr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(0)); if (!network) { return false; } // 3. 配置构建器(如果要做精细化配置可以更改config的参数) auto config = SampleUniquePtr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig()); if (!config) { return false; } // 4. 解析ONNX模型 auto parser = SampleUniquePtr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, sample::gLogger.getTRTLogger())); if (!parser) { return false; } // 5. 构建网络(以构建器,网络定义,构建器配置和onnx解析器作为参数,构建整个网络,包括onnx文件解析,位宽设定,设定量化区间,设定dla使用等精细化参数配置) /* bool SampleOnnxMNIST::constructNetwork(SampleUniquePtr<nvinfer1::IBuilder>& builder, SampleUniquePtr<nvinfer1::INetworkDefinition>& network, SampleUniquePtr<nvinfer1::IBuilderConfig>& config, SampleUniquePtr<nvonnxparser::IParser>& parser) { auto parsed = parser->parseFromFile(locateFile(mParams.onnxFileName, mParams.dataDirs).c_str(), static_cast<int>(sample::gLogger.getReportableSeverity())); if (!parsed) { return false; } if (mParams.fp16) { config->setFlag(BuilderFlag::kFP16); } if (mParams.bf16) { config->setFlag(BuilderFlag::kBF16); } if (mParams.int8) { config->setFlag(BuilderFlag::kINT8); samplesCommon::setAllDynamicRanges(network.get(), 127.0F, 127.0F); } samplesCommon::enableDLA(builder.get(), config.get(), mParams.dlaCore); return true; } */ auto constructed = constructNetwork(builder, network, config, parser); if (!constructed) { return false; } // 6. CUDA流配置 // CUDA stream used for profiling by the builder. auto profileStream = samplesCommon::makeCudaStream(); if (!profileStream) { return false; } // 将cuda流加入配置 config->setProfileStream(*profileStream); // 7. 序列化网络 SampleUniquePtr<IHostMemory> plan{builder->buildSerializedNetwork(*network, *config)}; if (!plan) { return false; } // 8. 创建运行时 mRuntime = std::shared_ptr<nvinfer1::IRuntime>(createInferRuntime(sample::gLogger.getTRTLogger())); if (!mRuntime) { return false; } // 9. 反序列化引擎(用于加载推理使用) mEngine = std::shared_ptr<nvinfer1::ICudaEngine>( mRuntime->deserializeCudaEngine(plan->data(), plan->size()), samplesCommon::InferDeleter()); if (!mEngine) { return false; } // 校验网络输入输出是否复合要求 ASSERT(network->getNbInputs() == 1); mInputDims = network->getInput(0)->getDimensions(); ASSERT(mInputDims.nbDims == 4); ASSERT(network->getNbOutputs() == 1); mOutputDims = network->getOutput(0)->getDimensions(); ASSERT(mOutputDims.nbDims == 2); ``` * 如果是第二种情况则相对简单 ``` c++ // 1. 创建运行时 IRuntime* runtime = createInferRuntime(logger); if (!runtime) { cerr << "create Runtime fail" << endl; return -1; } // 2. 创建引擎(加载序列化好的引擎文件) ICudaEngine* engine = loadEngine(engineFile, runtime); if (!engine) { cerr << "create engine fail" << endl; runtime->destroy(); return -1; } ``` ## 4.2. 推理 完成运行时和引擎创建后,就是创建上下文,绑定输入输出,开辟显存空间,创建cuda流,喂数据,完成推理,获得结果。样例代码如下: ``` c++ // 1. 创建上下文 IExecutionContext* context = engine->createExecutionContext(); if (!context) { cerr << "create context fail" << endl; engine->destroy(); runtime->destroy(); return -1; } // 创建数据输入 float* input = preprocessImage(imageFile, inputH, inputW); // 2. 获取引擎(网络)的输入输出对应的内存起始地址(测试的是一个resnet50的分类网络) int inputIndex = engine->getBindingIndex("data"); // model input int outputIndex = engine->getBindingIndex("resnetv24_dense0_fwd"); // model output // 3. 在device上开辟对应空间cuda allocate void* buffers[2]; size_t inputSize = 3 * inputH * inputW * sizeof(float); size_t outputSize = 1000 * sizeof(float); // 1000 class cudaMalloc(&buffers[inputIndex], inputSize); cudaMalloc(&buffers[outputIndex], outputSize); // 4. 创建cuda流,create cuda stream cudaStream_t stream; cudaStreamCreate(&stream); // 创建输出 float* output = new float[1000]; // 5. 将输入从host copy到device, cudaMemcpyAsync(buffers[inputIndex], input, inputSize, cudaMemcpyHostToDevice, stream); // 6. 通过上下文将数据送入执行管道 context->enqueueV2(buffers, stream, nullptr); // 等待执行结束 cudaStreamSynchronize(stream); // 7. 从device取回output,copy output data from device to host cudaMemcpyAsync(output, buffers[outputIndex], outputSize, cudaMemcpyDeviceToHost, stream); // 等待执行结束 cudaStreamSynchronize(stream); ```
dingfeng
2024年12月31日 15:03
3939
0 条评论
转发文档
收藏文档
上一篇
下一篇
评论
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码