Public Docs
【模型量化】深度学习模型量化 & 量化理论 & 各平台的量化过程 & 硬件加速
【TVM】TI关于TVM的使用测试与分析
【LLM&LVM】大模型开源工程思维导图
SmartSip
【北航卓越工程师】《汽车前沿技术导论:智能驾驶》讲义
【工具链】Yocto使用介绍——使用Yocto创建一个树莓派的系统镜像
【工具链】使用ssh+dialog指令设定服务器指定用户仅容器访问
【推理引擎】一篇关于模型推理的详细对比与学习
【推理引擎】关于TVM中的Schedule优化详解(On going)
【LLM微调】使用litgpt进行私有数据集模型微调的测试总结
【TVM】在TVM Relay中创建一个自定义操作符
【STT+LLM+TTS】如何使用语音转文字模型+大预言模型+语音生成模型完成一个类人的语音交互机器人
【RAG】 通过RAG构建垂直领域的LLM Agent的方法探索
【RAG】GraphRAG精读与测试(On going)
【AI Agent】MetaGPT精读与学习
【AI Base】Ilya Sutskever 27篇必读论文分享清单
【Nvidia】Jetson AGX Orin/ Jetson Orin nano 硬件测试调试内容(On going)
【BI/DI】LLM Using in BI Testing Scenario (On going)
【Nvidia】How to Activate a Camera on Nvidia Platform in Details
【RAS-PI】树莓派驱动开发
【行业咨询阅读】关注实时咨询和分析
【mobileye】2024 Driving AI
【mobileye】SDS_Safety_Architecture
【yolo】yolov8测试
【nvidia】Triton server实践
【alibaba】MNN(on updating)
【OpenAI】Triton(on updating)
【CAIS】关于Compound AI Systems的思考
【Nvidia】关于Cuda+Cudnn+TensorRT推理环境
【BEV】BEVDet在各个平台上的执行效率及优化(On Updating)
【Chip】AI在芯片设计和电路设计中的应用
【Chip】ChiPFormer
【Chip】关于布线的学习
【Chip】MaskPlace论文精读与工程复现优化
【gynasium】强化学习初体验
【Cadence】X AI
【transformer】MinGPT开源工程学习
【中间件】针对apollo 10.0中关于cyberRT性能优化的深度解读和思考
【Robotics】调研了解当前机器人开发者套件(on updating)
【Robotics】ROS CON China 2024 文档技术整理与感想总结(上2024.12.7,中2024.12.8,下场外产品)
【algorithm】关于模型、数据与标注规范的平衡问题
【nvidia】DLA的学习了解与使用
【nvidia】构建nvidia嵌入式平台的交叉编译环境(其他环境平台可借鉴)
【2025AI生成式大会】2025大会个人总结
【Robotics】 Create Quadruped Robot RL FootStep Training Environment In IsaacLab
【Robotics】如何一个人较为完整的完成一个机器人系统软件算法层面的设计与开发
【VLM】读懂多模态大模型评价指标
【VLM】大模型部署的端侧部署性能与精度评估方法与分析
【Nvidia】Jetson Orin 平台VLM部署方法与指标评测
【Database】向量数据库
【SoC】性能与功耗评估
【MCP】MCP探索
【InnoFrance】一个“关于声音”的有趣项目
【Robotics】写给那些想要快速了解机器人或者具身智能的工程师们
【Robotics】open X Embodiment RT-X 数据集下载与使用和分析
文档发布于【Feng's Docs】
-
+
首页
【Chip】AI在芯片设计和电路设计中的应用
# Brief * 最近开始了一项全新的工作领域,那就是AI在芯片和电路设计中的应用,如何通过AI算法提高placement和布线的效率。对于从零开始接触一个新的领域,自然是快速学习。找到开源项目快速测试。针对应用场景修改核心代码这个过程。同时我也将同步记录在这项新工作开始的一些列学习过程和成果。 # Learning * https://sites.google.com/view/chipformer/home 讲述了整个硬件和芯片设计的过程,`理解问题`。 * https://icml.cc/virtual/2023/poster/25027 ICML 2023 的一个亮眼的工作 ChiPFormer。同时`明确重要会议ICML&NeurIPS`。 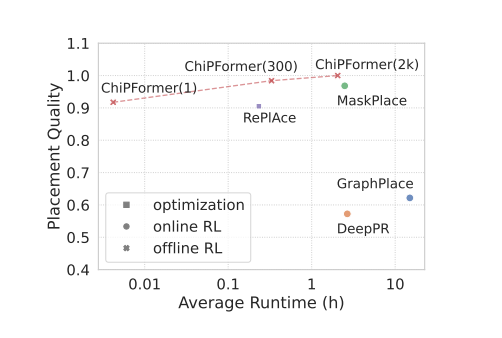 * 从ChiPFormer的benchmark中找到了,之前基于OnlineRL的方法DeepPR,GraphPlace,MaskPlace `形成学习路线`。 * MaskPlace,ChiPFormer的一作都是laiyao 一个港中文的学生和他所在的相关团队和实验室,`确认核心人物` * 根据核心任务,找到github的相关代码仓库和googledrive上的一些测试数据所在位置https://drive.google.com/drive/folders/1F7075SvjccYk97i2UWhahN_9krBvDCmr ,明确`测试前置条件`。 # 论文走读 chip design的任务就是完成macros module 和 standard cells module的放置任务。 * Chip Placement with Deep Reinforcement Learning https://arxiv.org/abs/2004.10746 * google提出的一个基于强化学习的方法,针对芯片设计环节中的chip placement进行优化和自动化。使用自己的TPU集群进行训练,消除硬件专家在环节中的人工参与,将原本数周乃至数月的工作只需要6个小时就能完成。并且方法针对各种芯片都有效。  方法通过使用强化学习作为agent,逐次进行macro的放置,并通过force directed( https://web.eecs.umich.edu/~mazum/PAPERS-MAZUM/cellplacement.pdf 介绍了在VLSI“超大规模集成电路”中采用的包括force directed在内的五种放置算法,simulated annealing模拟退火算法,force-directed placement力导向放置,placement by partitionning重切放置,numerical optimization techniques数值优化技术,placement by the genetic algorithm基于遗传算法的放置)方法进行基础单元的放置,同时通过HPWL和Congestion作为奖励。 ( https://research.google/blog/chip-design-with-deep-reinforcement-learning/ )文章指出,在大中小三个数据集上,fine-tune的时间越长,placement cost都越低。 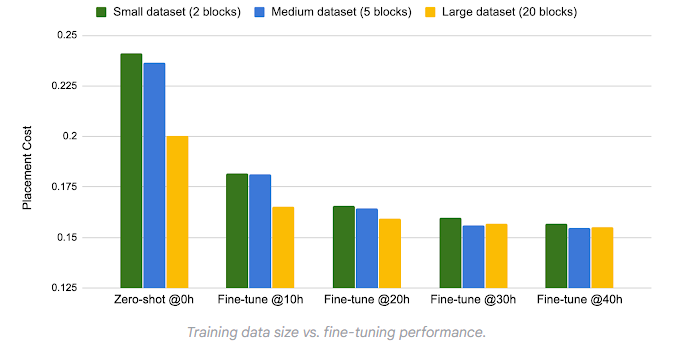 * DeepPR ( https://arxiv.org/pdf/1904.11533 ) * DeepPlace ( https://arxiv.org/abs/2111.00234 ) https://github.com/SP-FA/DeepPlace 论文提出了一种端到端的学习方法,名为DeepPlace,用于宏单元(macros)和标准单元(standard cells)的放置。论文提出了一个联合学习方法,通过整合强化学习和基于梯度的优化方案,来解决宏单元和标准单元的放置问题。 为了进一步连接放置和后续的布线任务,论文开发了DeepPR方法,通过强化学习同时完成放置和布线任务。论文设计了一个多视图嵌入模型,结合了卷积神经网络(CNN)和图神经网络(GNN),以编码输入宏单元的全局图级别和局部节点级别信息。此外,论文采用了随机网络蒸馏(RND)来鼓励探索。 论文在公共芯片设计基准测试集ISPD-2005上进行了实验,展示了该方法的有效性。当前模型受限于GNN的可扩展性和强化学习中的大型动作空间,因此仅限于中等数量的宏单元进行放置。 * ChiPFormer ( https://arxiv.org/abs/2306.14744 ) 第一个使用transformer和离线强化学习用来做chip placement的研究成果。从对标图来看超越了之前所有基于online强化学习的方案,其中maskplace为同一作的文章。 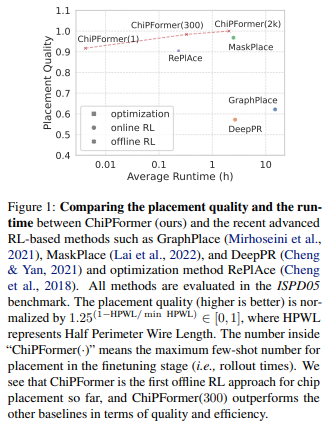 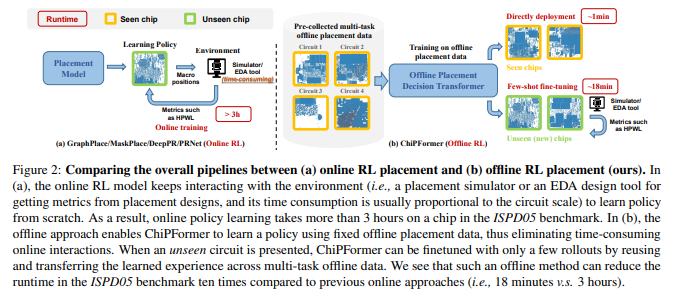 整体方案使用causal transformer也就是 transformer结构中的causal attention,mask self attention作为骨干网,主要是为了同next token prediction一样,放置未来信息影响。是用图网络将circuit 进行token化,弥补state token和action token的缺失信息,一同送入causal transformer进行学习。 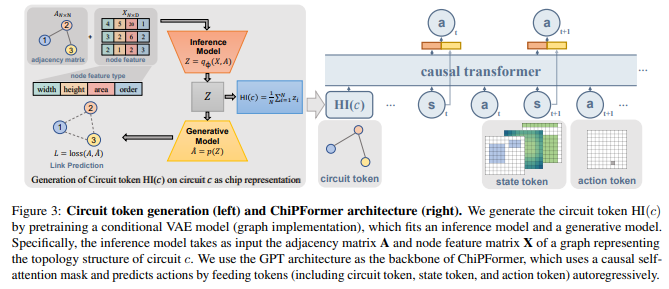 * ChiPBench 有了这套标准,布局指标与最终的端到端性能不一致、得分高而PPA性能却偏低的问题,就有望得到解决了。 paper:https://arxiv.org/abs/2407.15026 github: https://github.com/MIRALab-USTC/ChiPBench dataset:https://huggingface.co/datasets/ZhaojieTu/ChiPBench-D * MaskPlace 1. 相比较于其他方案maskplace能够在大分辨率(224*224)上取得较好的效果; 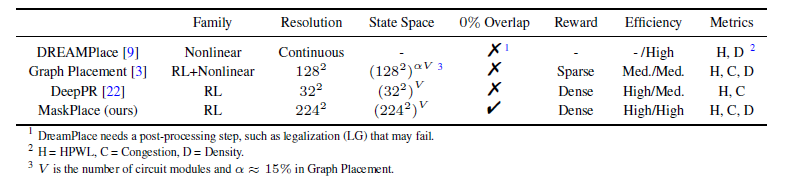 2. 问题被抽象为拥塞小于阈值,没有重叠的情况下HPWL最小  3. 使用RUDY计算代表布线的密集程度,通过对positionmask和wiremask进行融合确定最佳放置位置。最佳位置通过对融合后的位置进行1*1卷积最终输出的位置确认; 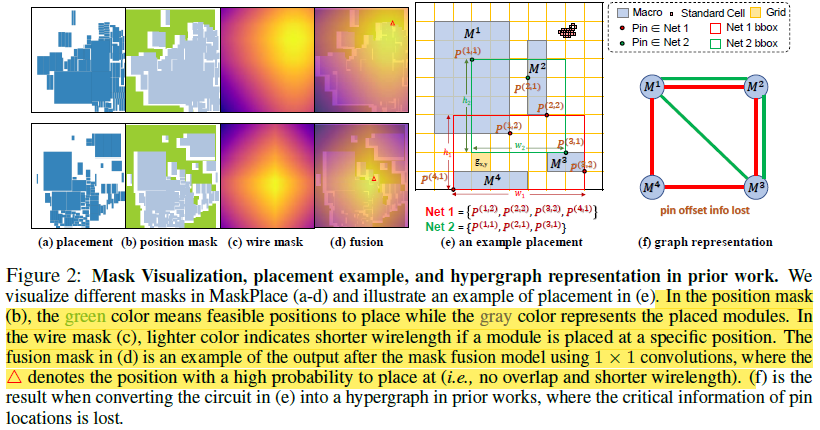 4. 整个芯片的放置过程被建模为一个马尔可夫过程,即当前step放置的cell只与上一时刻有关而与再之前的时刻无关;通过一个编解码网络,输入是上一个时刻的观测量和动作,输出是下一个时刻的动作。
dingfeng
2024年11月7日 17:42
2869
0 条评论
转发文档
收藏文档
上一篇
下一篇
评论
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码