Public Docs
【模型量化】深度学习模型量化 & 量化理论 & 各平台的量化过程 & 硬件加速
【TVM】TI关于TVM的使用测试与分析
【LLM&LVM】大模型开源工程思维导图
SmartSip
【北航卓越工程师】《汽车前沿技术导论:智能驾驶》讲义
【工具链】Yocto使用介绍——使用Yocto创建一个树莓派的系统镜像
【工具链】使用ssh+dialog指令设定服务器指定用户仅容器访问
【推理引擎】一篇关于模型推理的详细对比与学习
【推理引擎】关于TVM中的Schedule优化详解(On going)
【LLM微调】使用litgpt进行私有数据集模型微调的测试总结
【TVM】在TVM Relay中创建一个自定义操作符
【STT+LLM+TTS】如何使用语音转文字模型+大预言模型+语音生成模型完成一个类人的语音交互机器人
【RAG】 通过RAG构建垂直领域的LLM Agent的方法探索
【RAG】GraphRAG精读与测试(On going)
【AI Agent】MetaGPT精读与学习
【AI Base】Ilya Sutskever 27篇必读论文分享清单
【Nvidia】Jetson AGX Orin/ Jetson Orin nano 硬件测试调试内容(On going)
【BI/DI】LLM Using in BI Testing Scenario (On going)
【Nvidia】How to Activate a Camera on Nvidia Platform in Details
【RAS-PI】树莓派驱动开发
【行业咨询阅读】关注实时咨询和分析
【mobileye】2024 Driving AI
【mobileye】SDS_Safety_Architecture
【yolo】yolov8测试
【nvidia】Triton server实践
【alibaba】MNN(on updating)
【OpenAI】Triton(on updating)
【CAIS】关于Compound AI Systems的思考
【Nvidia】关于Cuda+Cudnn+TensorRT推理环境
【BEV】BEVDet在各个平台上的执行效率及优化(On Updating)
【Chip】AI在芯片设计和电路设计中的应用
【Chip】ChiPFormer
【Chip】关于布线的学习
【Chip】MaskPlace论文精读与工程复现优化
【gynasium】强化学习初体验
【Cadence】X AI
【transformer】MinGPT开源工程学习
【中间件】针对apollo 10.0中关于cyberRT性能优化的深度解读和思考
【Robotics】调研了解当前机器人开发者套件(on updating)
【Robotics】ROS CON China 2024 文档技术整理与感想总结(上2024.12.7,中2024.12.8,下场外产品)
【algorithm】关于模型、数据与标注规范的平衡问题
【nvidia】DLA的学习了解与使用
【nvidia】构建nvidia嵌入式平台的交叉编译环境(其他环境平台可借鉴)
【2025AI生成式大会】2025大会个人总结
【Robotics】 Create Quadruped Robot RL FootStep Training Environment In IsaacLab
【Robotics】如何一个人较为完整的完成一个机器人系统软件算法层面的设计与开发
【VLM】读懂多模态大模型评价指标
【VLM】大模型部署的端侧部署性能与精度评估方法与分析
【Nvidia】Jetson Orin 平台VLM部署方法与指标评测
【Database】向量数据库
【SoC】性能与功耗评估
【MCP】MCP探索
【InnoFrance】一个“关于声音”的有趣项目
【Robotics】写给那些想要快速了解机器人或者具身智能的工程师们
【Robotics】open X Embodiment RT-X 数据集下载与使用和分析
文档发布于【Feng's Docs】
-
+
首页
【模型量化】深度学习模型量化 & 量化理论 & 各平台的量化过程 & 硬件加速
# 1. 全文思维导图 ``` mindmap # 模型量化 ## 量化基础 ### 原理 ### 分类 ## 量化理论 ### 论文 ## 量化部署 ### TensorRT(NVIDIA) ### TIDL(TDA4) ### TVM(嵌入式) ### PPL(商汤) ### NCNN(手机) ### OpenVINO(Intel) ### SNPE(Qualcomm) ### Vitis(AMD/Xilinx) ### 量化加速 ``` # 2. 前言 在运算资源有限制的机器上部署“深度学习模型”,需要了解模型大小和模型推理速度的关系,设计出能够发挥硬件计算能力的模型结构。而衡量模型大小和推理速度的关系,往往跟计算量、参数量、访存量和内存占用等指标密切相关。而处理对模型各种算子和方式方法进行深度了解的同时,使用`模型量化`方法,也能对以上密切相关模型部署性能的指标进行有效的潜在提升。 # 2. 量化基础 ## 2.1. 定义和背景 ### 2.1.1. 什么是量化(Quantization) 以下是wikipedia中对于量化Quantization一词的解释,从数学含义中不难看出,量化过程实际是一个化繁为简的过程,英文解释为`many-to-few mapping`。 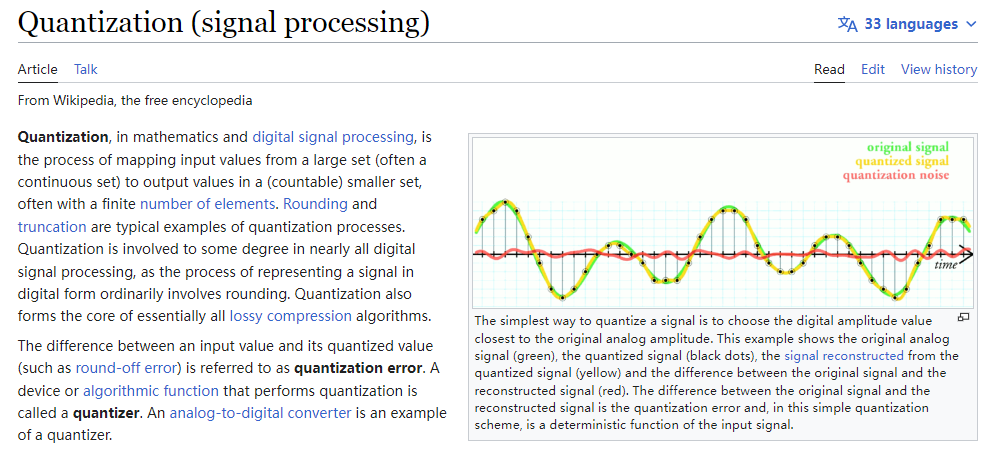 --- 借用量化一词的思想和原理,深度学习中的模型量化从原理上来说也是类似的一个概念和方式。深度学习中的模型量化就是把高位宽(Float32)表示的`权值`或`激活值`用比较低位宽来近似表示(INT16,INT8,INT4,INT2 ... etc.),在数值上的体现就是将连续化的值离散化==(这也符合wikipedia中关于量化的英文解释the process of mapping input values from a large set (often a continuous set) to output values in a (countable) smaller set, often with a finite number of elements)==。  而从位宽减小这个过程不难理解,通过量化过程会使得`参数量下降`(部分量化工具带来的参数量下降还包含对于模型结构的修改,例如合并,删除,替换等)、`计算速度的提升`、`内存占用的降低`。但是,同样带来一个副作用就是`精度的损失`。所以,简言之,量化的目标就是为了,提高模型推理速度的同时,降低模型精度的损失。这个也是模型量化研究,的主要问题点。 > `这里额外引入一个小插曲` > 1. 存储压缩比较好理解,为什么高位宽变成低位宽,浮点数变为定点数会带来计算速度的提升,原理是什么? `Interger vs floating point arthmetic` > 在计算机理论中,也就是我们通常知道的那样,我们要想把数字保存在内存中一定需要通过0,1对数据进行编码。而浮点数(floating point numbers)和定点数(integers)就是两种方式。 > 所谓定点格式,即约定机器中所有数据的小数点位置是固定不变的。通常将定点数据表示成纯小数或纯整数,为了将数表示成纯小数,通常把小数点固定在数值部分的最高位之前;而为了将数表示成纯整数,则把小数点固定在数值部分的最后面,如下图所示: >  > 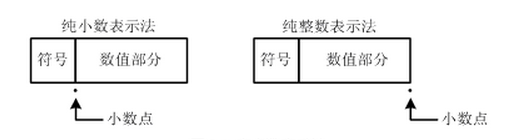 >  >  >  > 所以,如果尝试以科学格式将两个数字相加和相乘,就会发现浮点运算比整数运算稍微复杂一些。实际上,每次计算的速度很大程度上取决于实际的硬件。例如,台式机中的现代 CPU 执行浮点运算与整数运算一样快。另一方面,GPU 针对单精度浮点计算进行了更多优化。 (因为这是计算机图形学中最普遍的类型。)所以,不完全精确的说,使用 int8 通常比 float32 更快。 > 2. 而对于量化产生的损失,这里也有一个例子. > 假设我们有一层网络的输出为 [−a,a),其中a是一个实数。如果需要量化到 [−128,128) 并向下取整。 我们只需要做一次转化 > 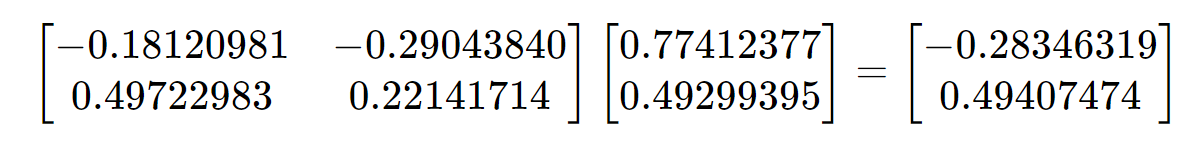 > 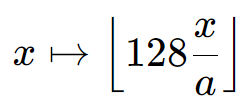 > 如果我们将range定义为(-1, 1) 我们对矩阵和输入进行量化得到下式: >  > 因为两个int8相乘是一个int16 所以我们对最终输出的结果还原回浮点数 > 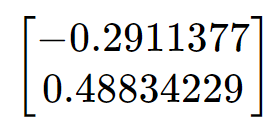 > 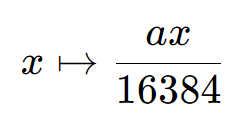 > 以此我们就知道量化误差的来源。所以模型量化的同时,减小量化误差就有了不少门道。 > `我们接着看回正文`。 ### 2.1.2. 量化的过程 量化其实就是将训练好的深度神经网络的权值,激活值等从高精度转化成低精度的操作过程,并保证精度不下降的过程。如何从高精度转到低精度呢?在定点与浮点等数据之间建立一种数据映射关系,将信号的连续取值 近似为 有限多个离散值,并使得以较小的精度损失代价获得了较好的收益。这个映射过程一般用下面的公式来表示: Q = round(scale factor * clip(x,α,β))+ zero point 这个公式中:x 代表需要量化的数,也就是量化对象,是个浮点型数据。Q代表量化后的数,是个整型数据。公式涉及到3个操作,round操作,clip操作和 scale factor 选取。以及需要确定的值α,β,是clip操作的上下界,称为clipping value。 zero point 代表的是原值域中的0在量化后的值。在weight或activation中会有不少0(比如padding,或者经过ReLU),因此我们在量化时需要让实数0在量化后可以被精确地表示。 round操作:其实就是一种映射关系,决定如何将原来的浮点值按照一定的规律映射到整型值上。举个例子,我们可以选用四舍五入「假设5.4 则取值为5,5.5 则取值为6」的原则,也可以选用最近左顶点「5.4 和 5.5 都取值为5」或者最近右顶点原则等。 clip操作:其实就是切片操作,如何来选择这个量化对象的范围。为什么要选这个范围呢,因为量化到n位数后,可以用来表示量化后的整型值就是固定的,只有 2^N 个,这么有限的数据,怎么才能更好去映射原来的浮点值分布呢?这个范围选的太大了(按照原来的最大最小值来选,如下图所示),此时如果在头尾的浮点值只有零星的几个,而且距离其他值非常远,(如果此时是均匀量化)那么这个对于图中 α-α,β-β的离散值可能就被浪费了,这样浮点值到整型值的映射后导致的误差可能就会很大。这个取值是门艺术,大了浪费比特位,小了把就把太多有用信息“切”掉。 `所以当前不同的量化算法和优化策略往往是寻找一个恰当的[α,β],使得 clip 和 round 操作导致的误差较小。`(这些策略既可以通过一些算法如KL散度等统计方法得到,也可以通过一些类似calibration data的方式获得) > 什么是KL散度,这里有一个很形象的例子: >  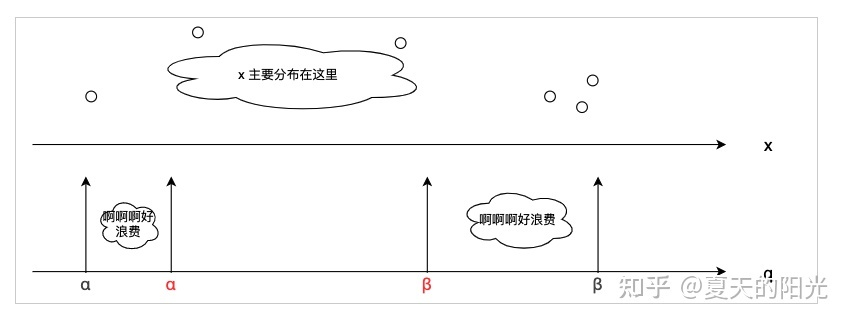 scale factor:是表述浮点数和整数之间的比例关系【不同的量化形式取不同的值】,如果是线性均匀量化,那么 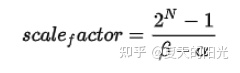 总结下,量化的过程就是选取合适量化参数(如scaling factor,zero point,clipping value)以及数据映射方式,让原来的浮点值映射到整型值后,尽量保持准确率不下降(或者在可控范围)。 ### 2.1.3. 量化的优点 1. 减小模型大小; 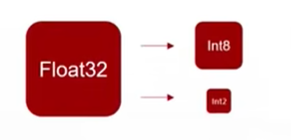 2. 降低访存 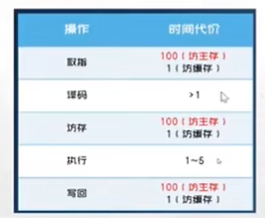 3. 加快速度(硬件指令集) 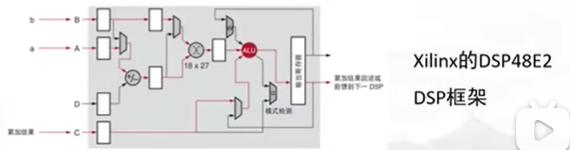 3  > 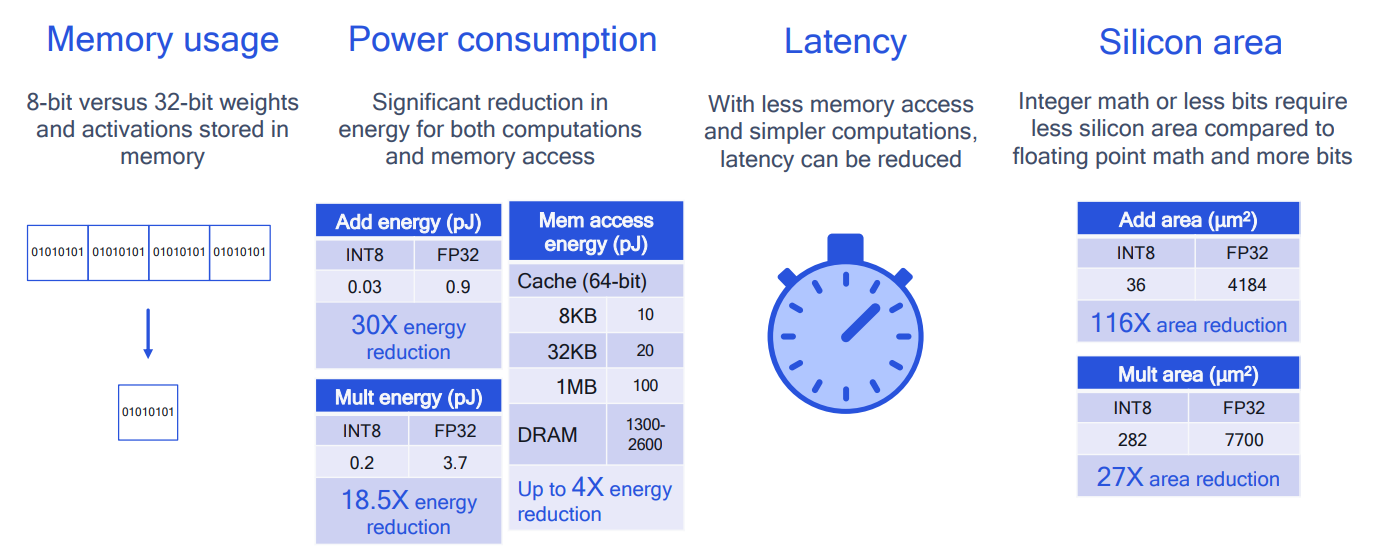 ### 2.1.4 量化的难点与挑战 * 1、多后端难点 不同芯片后端的量化算法实现具有不同的特点。对于不同的硬件,用户需要针对硬件研究不同的量化方案。这同时也会导致量化方案的硬件泛化 性受到限制。 所谓`硬件泛化性`,主要是指量化模型在泛硬件平台的迁移能力。 * 2、硬件黑盒难点 模型的量化部署往往伴随着复杂的模型精度修复工作,特别是在第三方硬件下,需要解决如何与第三方硬件对齐的问题。 但在实际服务过程中,硬件的比特级对齐方案又是部署服务的重中之重。可以通过提供量化算法的`模拟环境`(simulate quantization),使得精度修复算法能够在硬件上复现。常见的硬件差异主要源于`非计算算子(Concat, Eltwise)的量化处理、累加器的重采样和取整方式`的不同。 >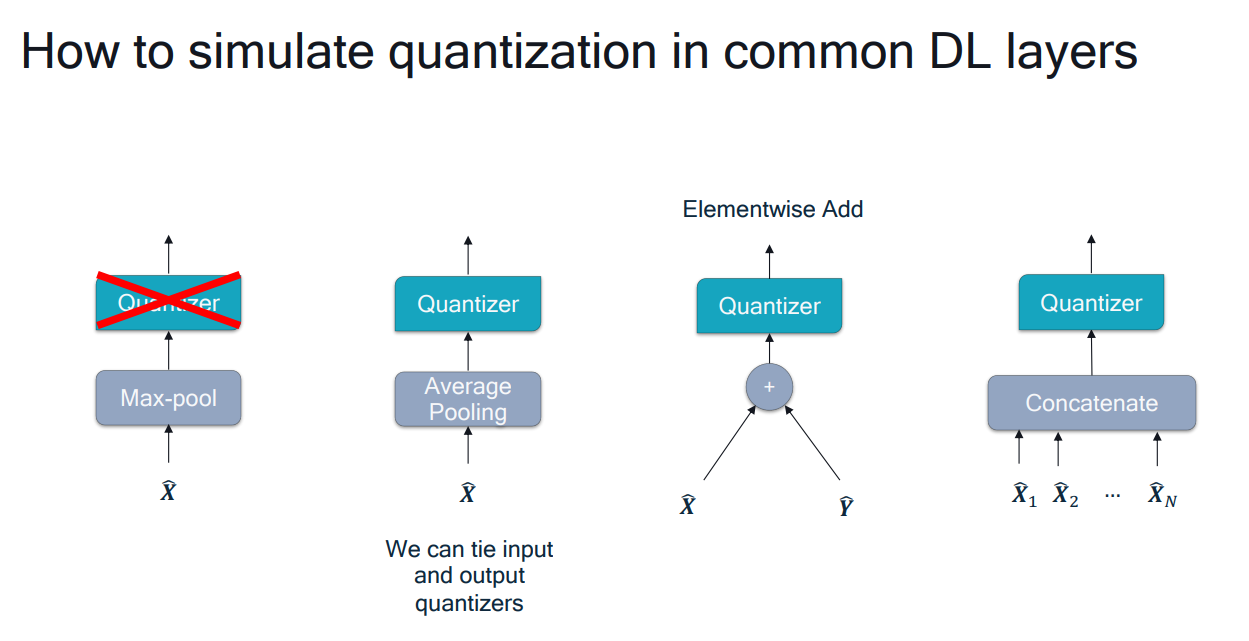 `Max pooling` Activation quantization is not required because the input and output values are on the same quantization grid. `Average pooling` The average of integers is not necessarily an integer. For this reason, a quantization step is required after average-pooling. However, we use the same quantizer for the inputs and outputs as the quantization range does not significantly change. `Element-wise addition` Despite its simple nature, this operation is difficult to simulate accurately. During addition, the quantization ranges of both inputs have to match exactly. If these ranges do not match, extra care is needed to make addition work as intended. There is no single accepted solution for this but adding a requantization step can simulate the added noise coarsely. Another approach is to optimize the network by tying the quantization grids of the inputs. This would prevent the requantization step but may require fine-tuning. `Concatenation` The two branches that are being concatenated generally do not share the same quantization parameters. This means that their quantization grids may not overlap making a requantization step necessary. As with element-wise addition, it is possible to optimize your network to have shared quantization parameters for the branches being concatenated. * 3、量化误差分析难点 量化在计算过程中会引入误差,导致网络部署精度相对于 FP32 会损失部分表达。 在实际业务中,部署的一大挑战在于,如何去保证量化模型的精度,通过降低误差,以保证模型速度和精度的收益平衡。 ## 2.2. 各种量化的分类 * 按照均匀性: 线性量化、非线性量化 * 量化范围:对称量化、非对称量化、饱和量化、不饱和量化  * bit范围:8-bit,4bit,2-bit,1-bit * 量化参数粒度:per-axi/per-channel、per-tensor/per-layer、Global * 通道量化(Per-axis/per-channel):对tensor的单个轴有单独的量化参数,如per-channel就是weight的每个channel使用单独的量化参数。通常情况下,per-channel 因为量化的粒度更细致,量化参数的自由度更高,往往更优于 per-tensor 的量化精度。 * 层量化(Per-tensor/per-layer):每个tensor有单独的量化参数。对于卷积或全连接层这些的话这也就意味着每层独立的量化参数。 * Global:即整个网络使用相同的量化参数。一般来说,对于8位量化,全局量化参数影响不明显,但到更低精度,就会对准确率有较大影响。 * 量化位宽:统一位宽、混合精度 * 量化方式:PTQ(Post-Training Quantization)、QAT(Quantization-Aware-Training)  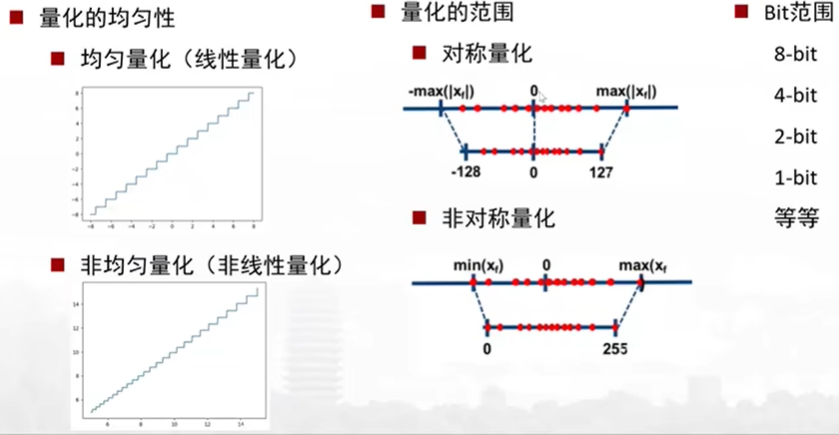   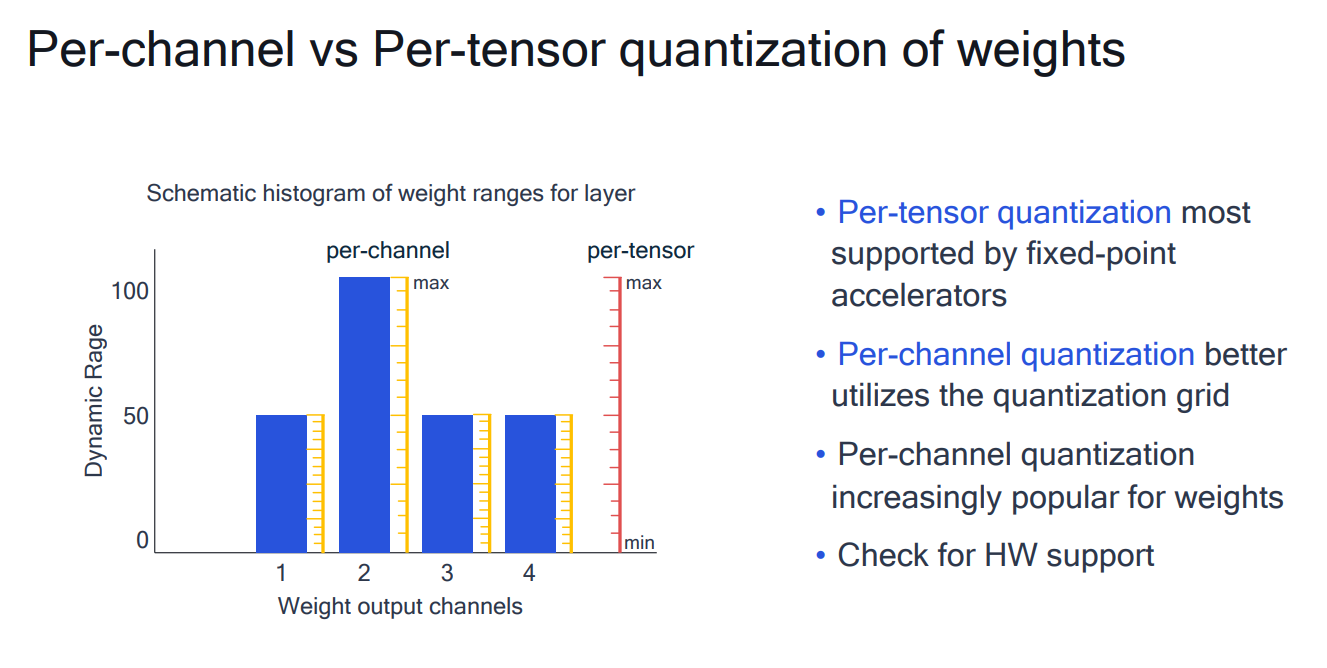  > 从整体分类过程不难看出,PTQ和QAT都可以进行一定的策略选择,以达到量化目的。 > PTQ的可操作性相对较少,但是难度和工程部署上仍有不少可以探索的方案,但是该能力基本与平台强绑定。而我们通常智能根据以下几种方式进行实验和组合: > 1. 根据模型特点,将模型拆解成多个部分,对于不同部分根据需要使用不同的量化位宽; > 2. 根据网络各个算子的特点,对运算密集型算子如卷积、反卷积、全连接等采样低位宽量化,而对于高访存的算子采样高位宽量化;当然这也要结合硬件平台的指令集运算特点进行;(`参考文献添加`) > 早期的量化方式中,由于每一层的output都会收到量化的weight和input的影响,产生误差。而这个output作为下一层的输入也会被量化为定点域,继续影响下一层的概率分布,如此下去就会导致整个网络的输出,相较于原来的浮点输出产生非常大的差距。但是反向传播更新的时候依然在浮点权重上更新,对于复杂网络的优化难度是非常大的。 > 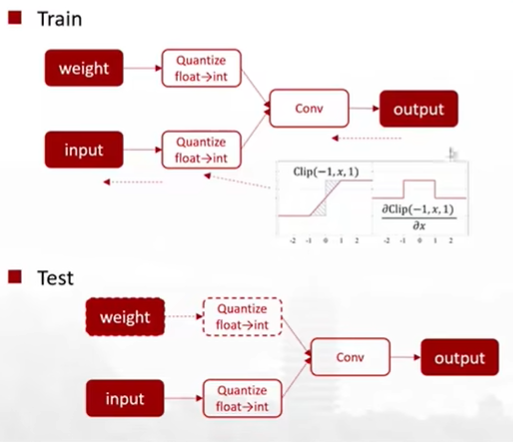 > Bi-Real Net: Enhancing the Performance of 1-bit CNNs With Improved Representational Capability and Advanced Training Algorithm (https://github.com/liuzechun/Bi-Real-net) >> 深度卷积神经网络(CNN)由于精度高在视觉任务中已经有非常广泛的应用,但是 CNN 的模型过大限制了它在移动端的部署。模型压缩也因此变得尤为重要。在模型压缩方法中,将网络中的权重和激活都只用 +1 或者 -1 来表示将可以达到理论上的 32 倍的存储空间的节省和 64 倍的加速效应。由于它的权重和激活都只需要用 1bit 表示,因此极其有利于硬件上的部署和实现。 >> 然而现有的二值化压缩方法在 ImageNet 这样的大数据集上会有较大的精度下降。本文认为,这种精度的下降主要是有两方面造成的。 >> 1-bit CNN 的表达能力本身很有限,不如实数值的网络。 >> 1-bit CNN 在训练过程中有导数不匹配的问题导致难以收敛到很好的精度 >> 下图能够很好的说明这个现象: >>  >> 为了针对性的解决以上两个问题提出了两点训练方法上的创新: >> 1. Approximation to the derivative of the sign function with respect to activations(短接嵌入实数值信息,从Conv层输出的是整数,经过BN层,输出的是实数,实数可以表示更多的 possible configurations) >> 2. Magnitude-aware gradient with respect to weights(二值参数与激活值更新策略) > Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference (Google 当时提出的一种新的量化范式,也就是比较朴素的,只针对推理过程使用定点结构,训练模拟量化,模拟折叠BN过程) >>  >>  >>  * 其他策略:BN折叠,RELU折叠,ADD折叠,CONCAT折叠 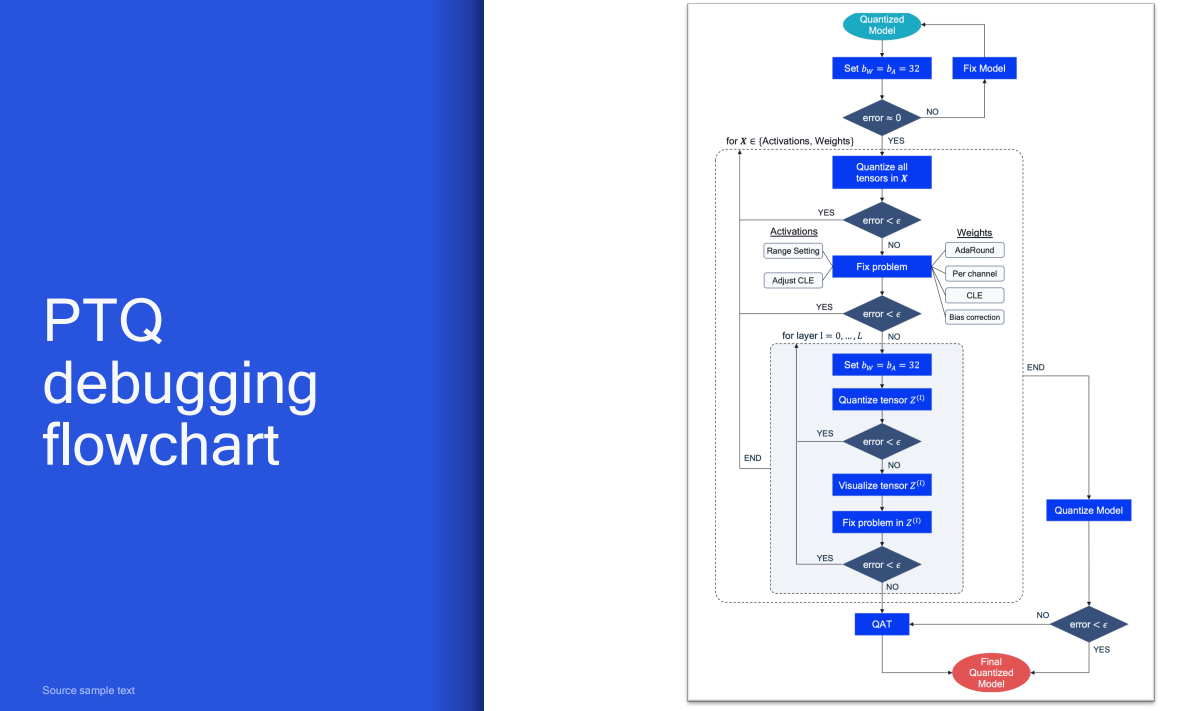  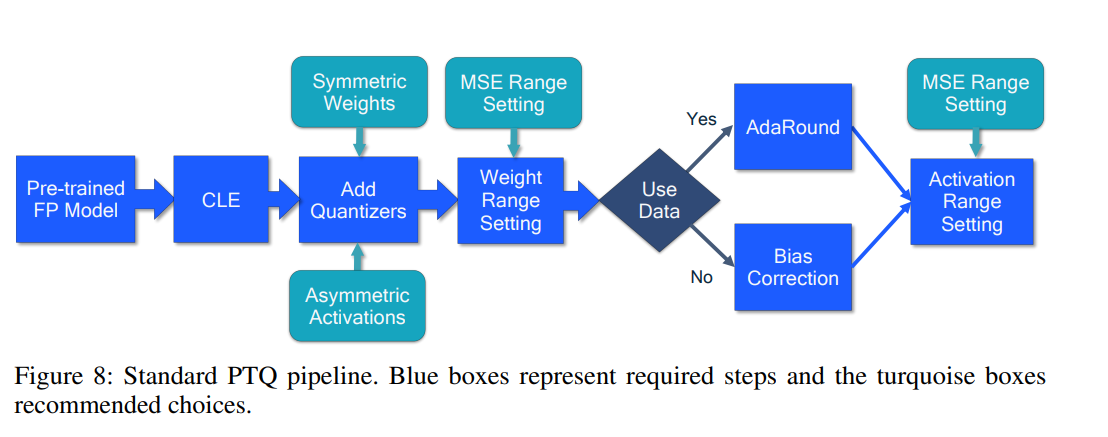  1. Cross-layer equalization 跨层均衡化(CLE):reference 28 对全精度模型的预处理 2. Add quantizers 使用量化模块: 对于常见的 AI 加速器,建议: 1. 权重使用对称量化器 2. 激活使用非对称量化器 如果硬件/软件堆栈支持,那么对权重使用按通道(per-channel)量化是有利的。 3. Range estimation 范围设置: 在训练之前,必须初始化所有的量化参数。 建议:使用基于层的MSE标准来设置所有量化参数。在按通道(per-channel)量化的特定情况下,使用最小-最大设置有时可能是更有利的。 4. Learnable Quantization Parameters 量化参数: 建议让量化器参数变得可学习。直接学习量化参数,而不是在每个epoch中更新它们,会带来更高的性能,特别是在处理低比特量化时。 设置优化器时,使用可学习的量化器需要特别小心: 1. 使用 SGD 类型的优化器时,与其他网络参数相比,量化参数的学习率需要降低 2. 使用具有自适应学习率的优化器(例如 Adam 或 RMSProp),则可以避免学习率调整 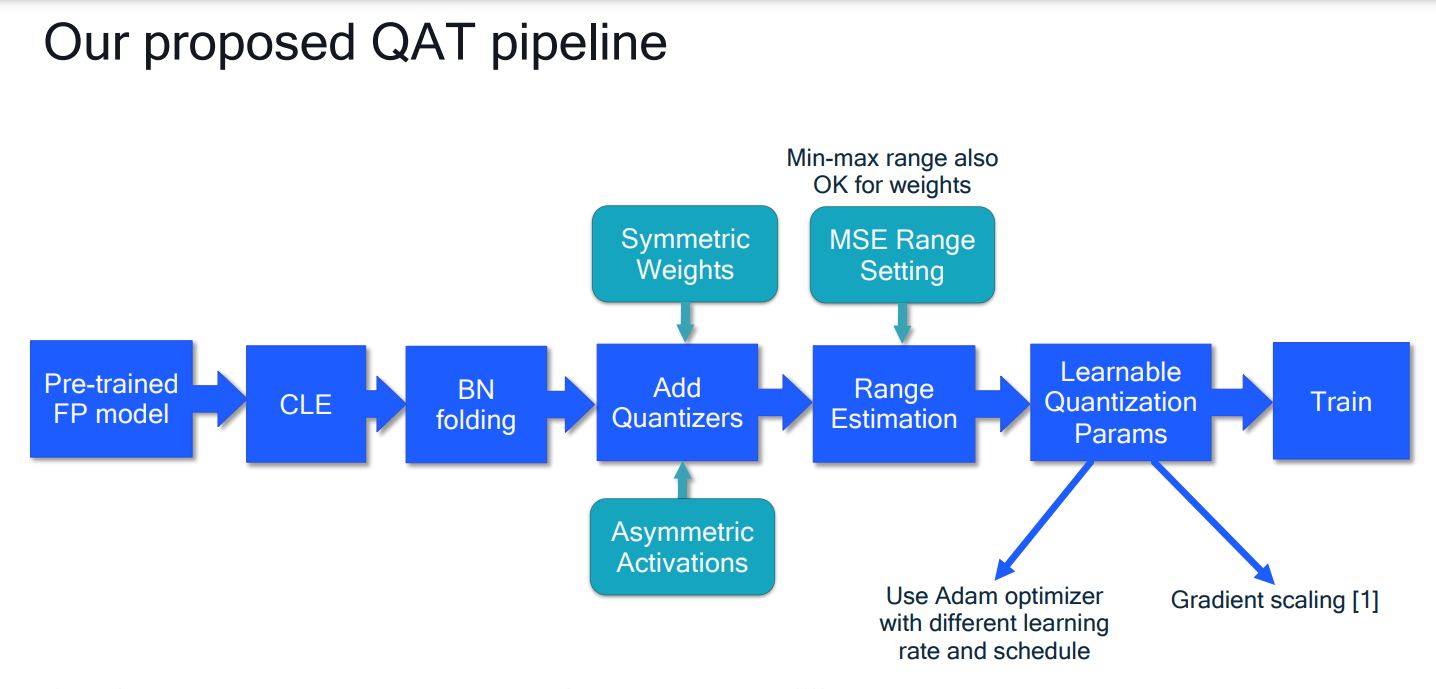 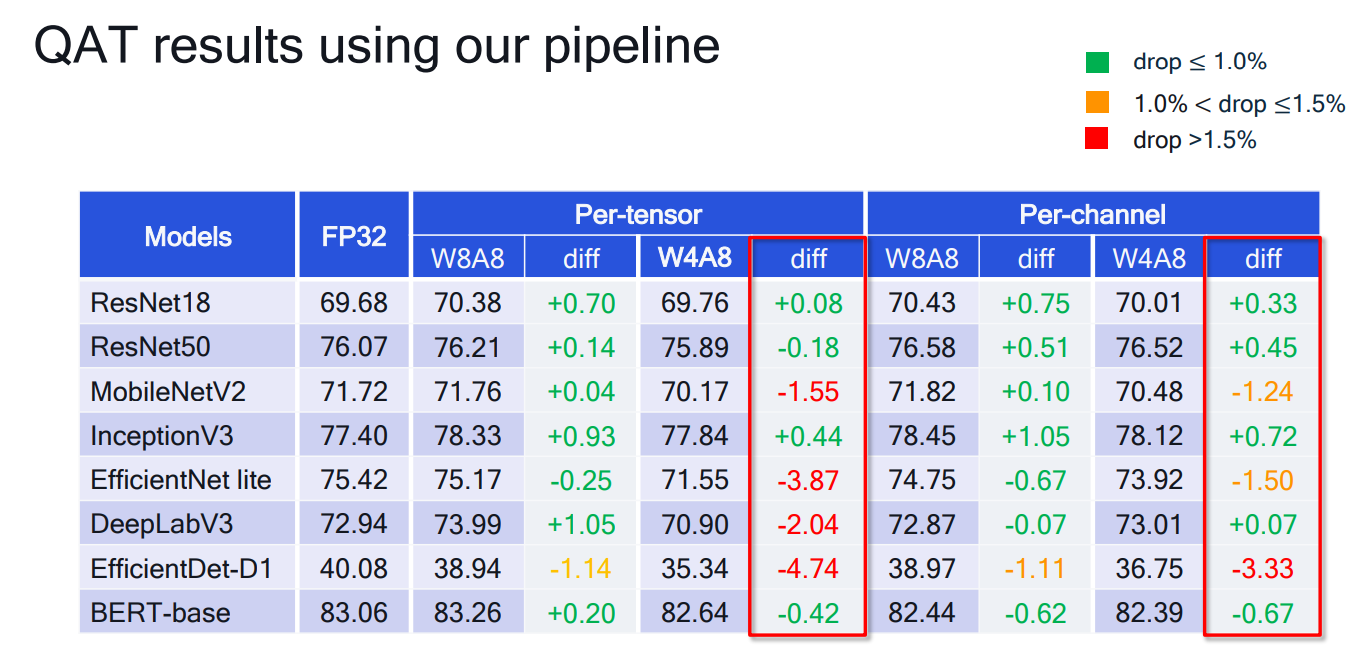 实验(Experiments) 1)对于没有深度可分离卷积的网络(Resnet18、Res net50、InceptionV3): W8A8和W4A8量化的表现与浮点模型相当 更激进的W4A4小幅性能下降 2)对具有深度可分离层的网络(MobileNetV2、EfficientNet lite、DeeplabV3、EfficientDet-D1): 进行量化更具挑战性 按通道(per-channel)量化可以显著提高性能,使DeepLabV3达到浮点精度,并将MobileNetV2和EfficientNet lite的差距缩小到1.5%以下。 3)对于 BERT-base: 具有范围学习的 QAT 可以有效地处理高动态范围 允许将所有激活保持在 8 位(与 PTQ 不同) 低bit权重量化对于 Transformer 模型来说不是问题 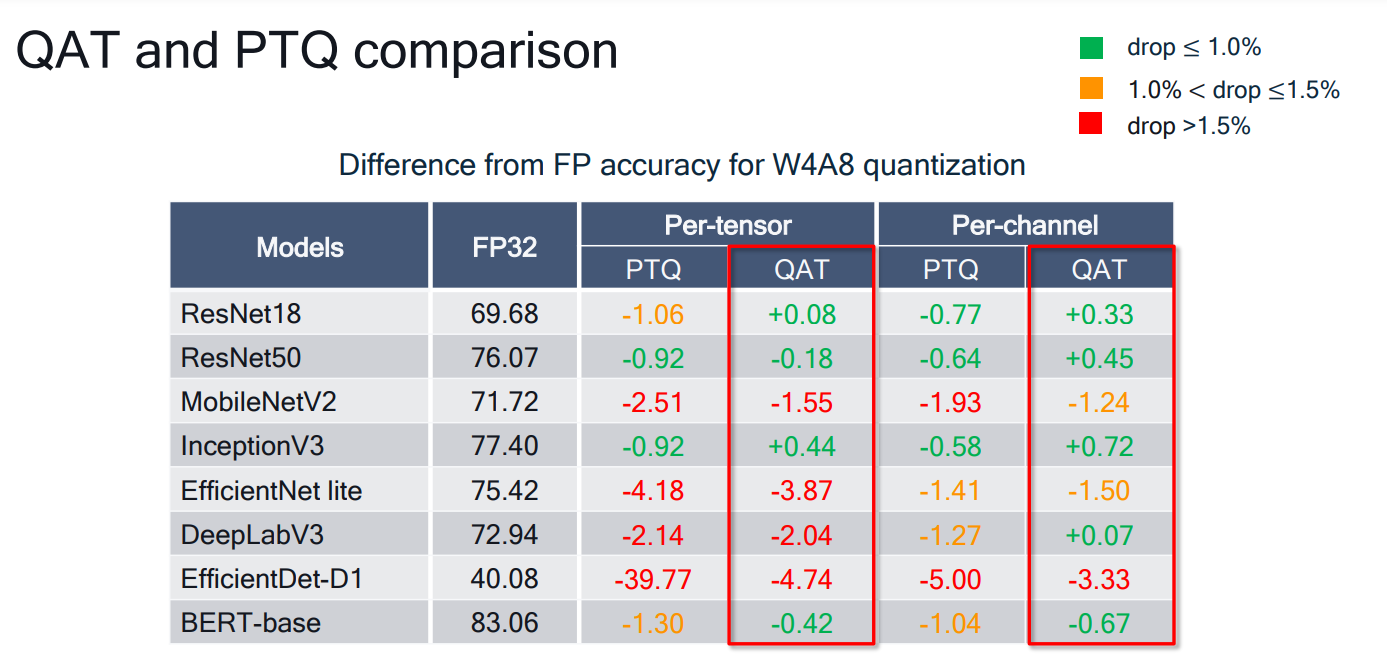 ==综上,各种量化方式的小总结== * 对称和非对称,激活用非对称,权重用对称 * per tensor常用,per channel一定会带来更大收益,不过通常需要确认硬件是否支持 * 如果对网络充分了解,混合精度能够平衡性能和精度 * 先使用PTQ方式充分逼近精度,如果无法获得最大收益,再考虑QAT ## 2.3. 量化的发展历程 之所以会出现如上诸多种量化方式,也是和量化工作的整个发展历程和各种方法在研究过程中的利弊息息相关的。感兴趣可以详细阅读高通一群研究员撰写的[量化白皮书](https://arxiv.org/pdf/2106.08295.pdf)一文,详细介绍了PTQ和QAT的SOTA成果。 >  量化方案的四种境界(reference 28 提出) * Level 1: 不需要额外的数据和训练操作。方法具有普适性,适合所有模型,只需要知道模型的结构和权重参数,直接离线量化就能得到很好的定点模型; * Level 2: 需要额外的数据,但不进行训练。方法具有普适性,适合所有模型,但是需要额外数据用于校正batch normalization的统计参数如moving mean和moving variance,或者用来逐层地计算量化误差,并且根据该误差采取相应策略(如重新选择缩放系数等)来提升性能; * Level 3: 需要额外的数据,并且用于finetune训练。方法具有普适性,适合所有模型。需要调节一些超参来寻找最优; * Level 4: 需要额外的数据,并且用于finetune训练,但方法针对特定模型使用。这种特定模型指的是用全浮点训练收敛之后的模型进行量化效果极差,并且必须从头开始加上量化操作进行训练,这种方法需要消耗极大的时间成本。 # 3. 量化理论  ## 3.1 如何找到一个更好的数据映射方式 量化最简单粗暴的做法的是rounding。将浮点转为定点的rounding方法:一种是Round-to-nearest,即就近取整;另一种是Stochastic rounding,即以一定概率(与向下取整点的距离成正比)确定向上还是向下取整。 > adaround算法 >>  >> 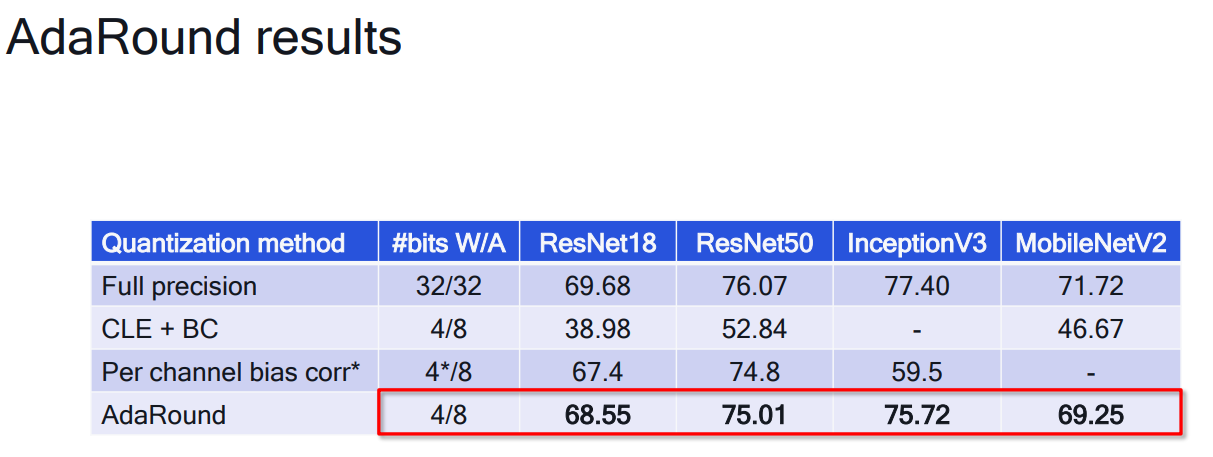 >> 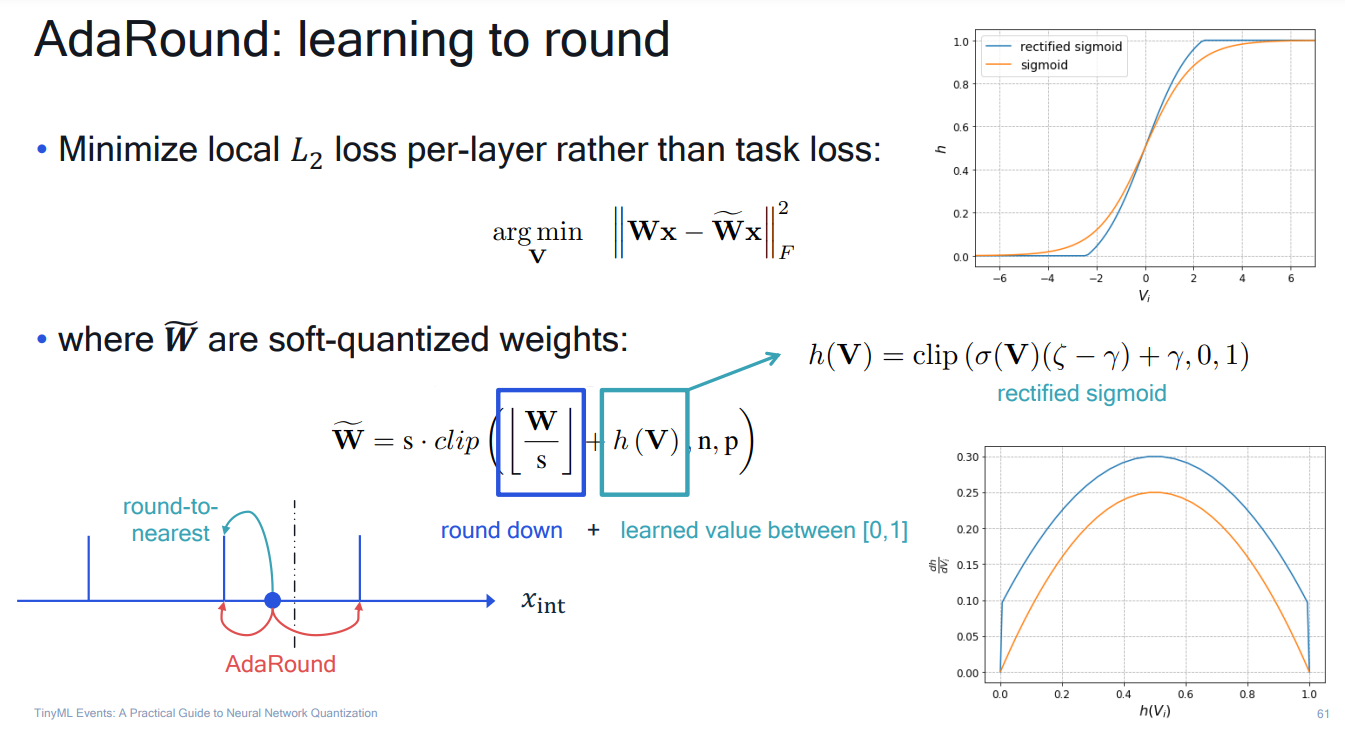 ## 3.2 给定一个训练好的量化模型,如何找到最优的量化超参数 `解决问题就是:给定一个 Tensor,寻找一个恰当的[α,β],使得 clip 和 round 操作导致的误差较小。` * ACIQ方法 * 基于MSE来找最优的clipping value * PACT(PArameterized Clipping acTivation)方法 * LSQ(Learned Step Size Quantization)等 > PACT: PARAMETERIZED CLIPPING ACTIVATION FOR QUANTIZED NEURAL NETWORKS >>  ## 3.3 如何让量化目标对象的分布变得更适合量化 > DFQ(Data-free quantization) >>  >> 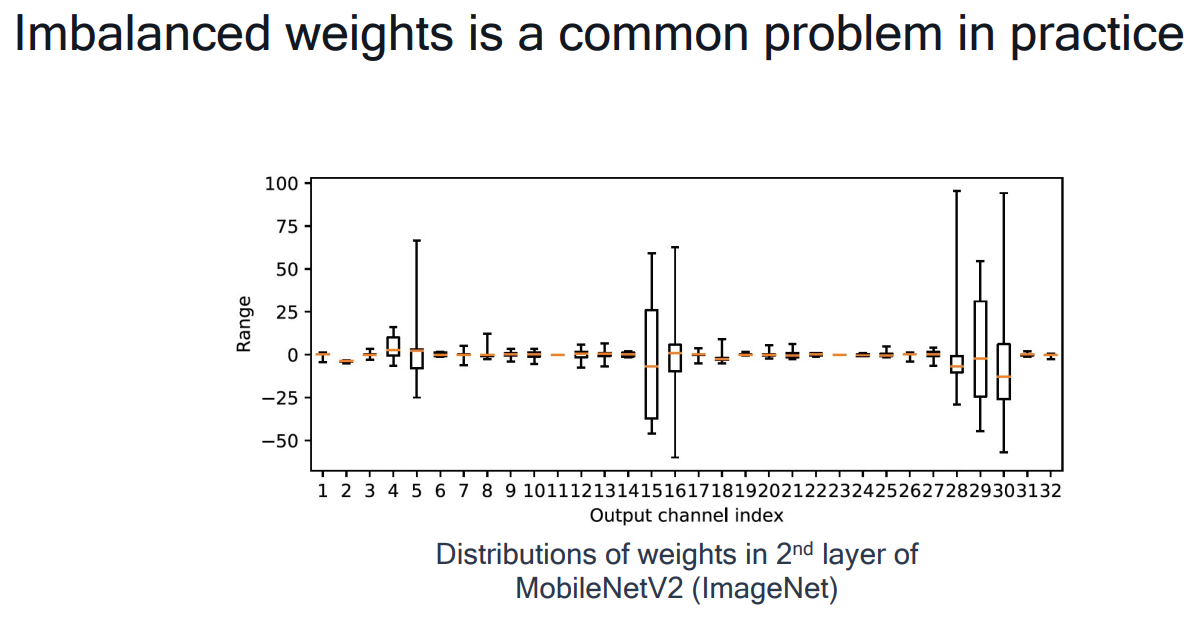 >> 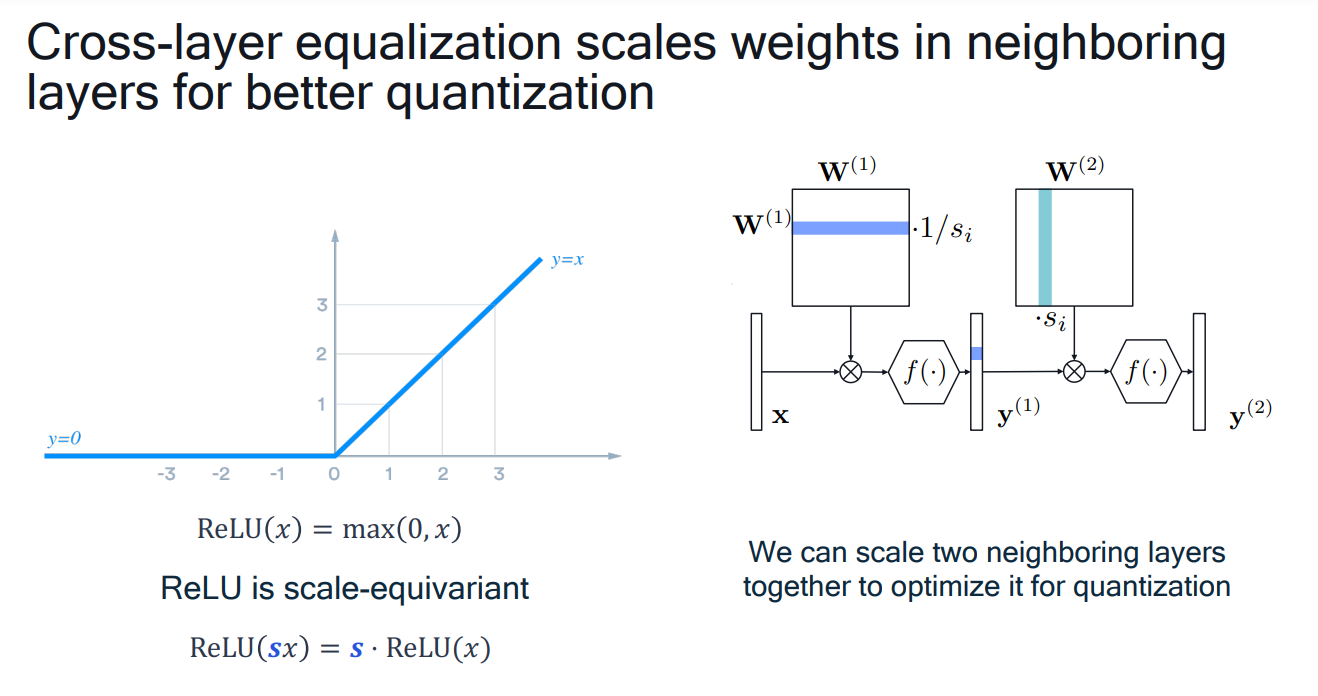 >> 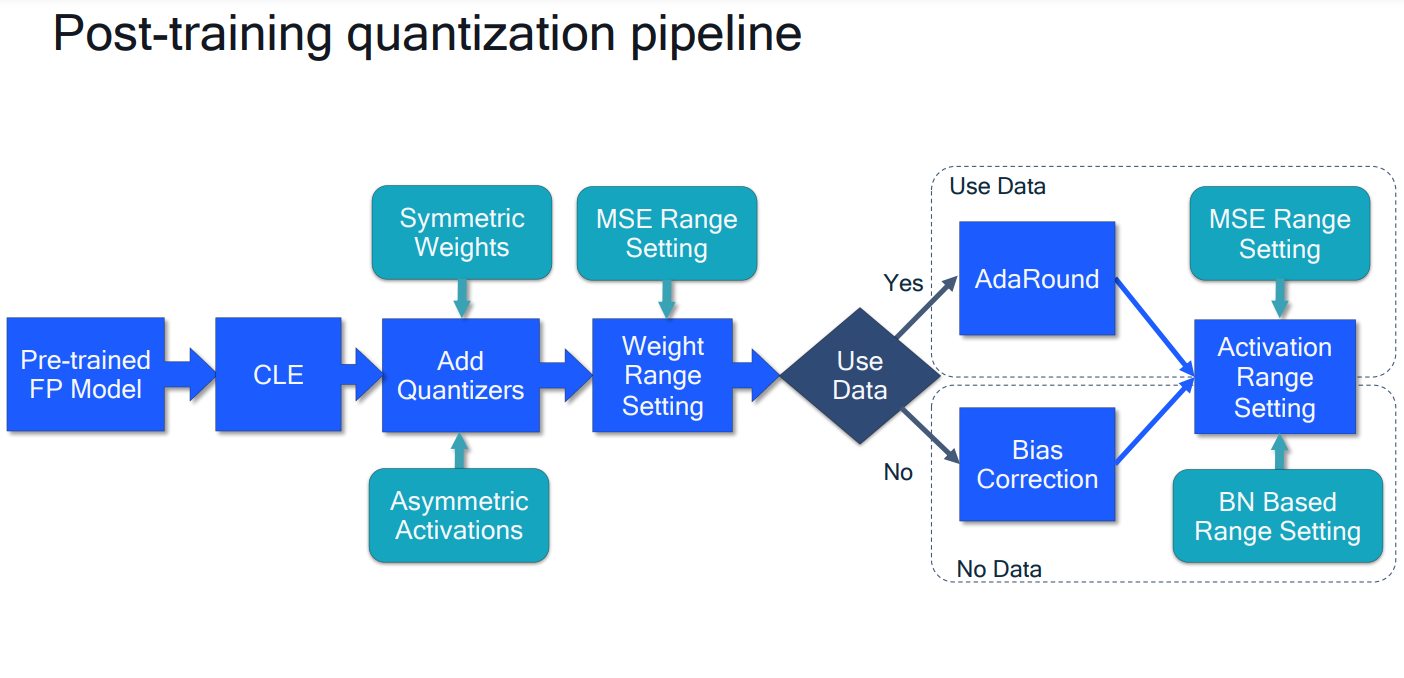 >> 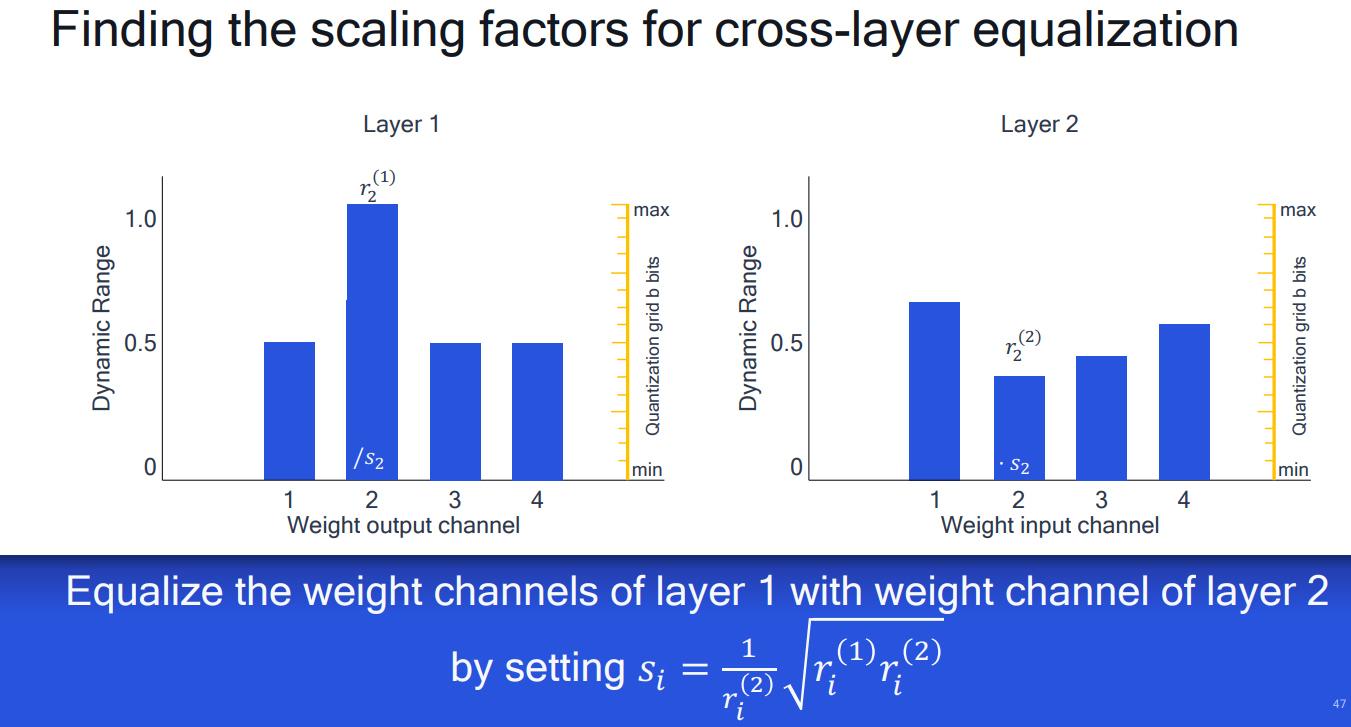 >>  # 4. 模型加速 # References 1. [A White Paper on Neural Network Quantization](https://arxiv.org/pdf/2106.08295.pdf) 2. https://cms.tinyml.org/wp-content/uploads/industry-news/tinyML_Talks-_Marios_Fournarakis_210929.pdf 3. https://www.cnblogs.com/kevinq/p/4480563.html 4. https://www.youtube.com/watch?v=cKdnFpDY_6A&t=375s 5. https://blog.csdn.net/u012655441/article/details/123125557 6. https://en.wikipedia.org/wiki/Quantization_(signal_processing) 7. [Quantization in practice](https://tivadardanka.com/blog/neural-networks-quantization) 8. [introduction-to-quantization-on-pytorch](https://pytorch.org/blog/introduction-to-quantization-on-pytorch/) 9. [TensorFlow Model Optimization Toolkit](https://www.tensorflow.org/lite/performance/model_optimization?hl=zh-cn) 10. [Visualizing the Loss Landscape of Neural Nets](https://arxiv.org/pdf/1712.09913.pdf) 11. https://www.bilibili.com/video/BV1xf4y1f7wn/?spm_id_from=333.337.search-card.all.click 12. [Knowledge Distillation: A Survey](https://arxiv.org/abs/2006.05525v1) 13. [Distilling the Knowledge in a Neural Network](https://arxiv.org/abs/1503.02531) 14. [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) 15. [Bi-Real Net: Enhancing the Performance of 1-bit CNNs With Improved Representational Capability and Advanced Training Algorithm](https://arxiv.org/abs/1808.00278) 16. [Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference](https://arxiv.org/pdf/1712.05877v1.pdf) 17. [PACT: PARAMETERIZED CLIPPING ACTIVATION FOR QUANTIZED NEURAL NETWORKS](https://openreview.net/pdf?id=By5ugjyCb) 18. [BiPointNet: Binary Neural Network for Point Clouds](https://arxiv.org/abs/2010.05501) 19. https://medium.com/@joel_34050/quantization-in-deep-learning-478417eab72b 20. https://zhuanlan.zhihu.com/p/462124806 21. https://zhuanlan.zhihu.com/p/449382101 22. https://blog.csdn.net/weixin_47160526/article/details/124008870 23. https://mp.weixin.qq.com/s?__biz=MzUyMDQzNDM3MQ==&mid=2247485418&idx=1&sn=d9c0426aa1cf095489ff7efb3e2b9baa&chksm=f9eb2046ce9ca950c91f3080afe48f240503621ce72d7a1d24fe4372deaa75ac3647c725f608&scene=27 24. [Data-Free Quantization Through Weight Equalization and Bias Correction](https://openaccess.thecvf.com/content_ICCV_2019/papers/Nagel_Data-Free_Quantization_Through_Weight_Equalization_and_Bias_Correction_ICCV_2019_paper.pdf) 25. https://github.com/quic/aimet 26. https://github.com/quic/aimet-model-zoo 27. https://github.com/jakc4103/DFQ 28. [Data-Free Quantization Through Weight Equalization and Bias Correction](https://openaccess.thecvf.com/content_ICCV_2019/papers/Nagel_Data-Free_Quantization_Through_Weight_Equalization_and_Bias_Correction_ICCV_2019_paper.pdf) # Organizitions * [tinyML](https://www.tinyml.org/)
dingfeng
2024年5月17日 15:12
4393
0 条评论
转发文档
收藏文档
上一篇
下一篇
评论
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码