Public Docs
【模型量化】深度学习模型量化 & 量化理论 & 各平台的量化过程 & 硬件加速
【TVM】TI关于TVM的使用测试与分析
【LLM&LVM】大模型开源工程思维导图
SmartSip
【北航卓越工程师】《汽车前沿技术导论:智能驾驶》讲义
【工具链】Yocto使用介绍——使用Yocto创建一个树莓派的系统镜像
【工具链】使用ssh+dialog指令设定服务器指定用户仅容器访问
【推理引擎】一篇关于模型推理的详细对比与学习
【推理引擎】关于TVM中的Schedule优化详解(On going)
【LLM微调】使用litgpt进行私有数据集模型微调的测试总结
【TVM】在TVM Relay中创建一个自定义操作符
【STT+LLM+TTS】如何使用语音转文字模型+大预言模型+语音生成模型完成一个类人的语音交互机器人
【RAG】 通过RAG构建垂直领域的LLM Agent的方法探索
【RAG】GraphRAG精读与测试(On going)
【AI Agent】MetaGPT精读与学习
【AI Base】Ilya Sutskever 27篇必读论文分享清单
【Nvidia】Jetson AGX Orin/ Jetson Orin nano 硬件测试调试内容(On going)
【BI/DI】LLM Using in BI Testing Scenario (On going)
【Nvidia】How to Activate a Camera on Nvidia Platform in Details
【RAS-PI】树莓派驱动开发
【行业咨询阅读】关注实时咨询和分析
【mobileye】2024 Driving AI
【mobileye】SDS_Safety_Architecture
【yolo】yolov8测试
【nvidia】Triton server实践
【alibaba】MNN(on updating)
【OpenAI】Triton(on updating)
【CAIS】关于Compound AI Systems的思考
【Nvidia】关于Cuda+Cudnn+TensorRT推理环境
【BEV】BEVDet在各个平台上的执行效率及优化(On Updating)
【Chip】AI在芯片设计和电路设计中的应用
【Chip】ChiPFormer
【Chip】关于布线的学习
【Chip】MaskPlace论文精读与工程复现优化
【gynasium】强化学习初体验
【Cadence】X AI
【transformer】MinGPT开源工程学习
【中间件】针对apollo 10.0中关于cyberRT性能优化的深度解读和思考
【Robotics】调研了解当前机器人开发者套件(on updating)
【Robotics】ROS CON China 2024 文档技术整理与感想总结(上2024.12.7,中2024.12.8,下场外产品)
【algorithm】关于模型、数据与标注规范的平衡问题
【nvidia】DLA的学习了解与使用
【nvidia】构建nvidia嵌入式平台的交叉编译环境(其他环境平台可借鉴)
【2025AI生成式大会】2025大会个人总结
【Robotics】 Create Quadruped Robot RL FootStep Training Environment In IsaacLab
【Robotics】如何一个人较为完整的完成一个机器人系统软件算法层面的设计与开发
【VLM】读懂多模态大模型评价指标
【VLM】大模型部署的端侧部署性能与精度评估方法与分析
【Nvidia】Jetson Orin 平台VLM部署方法与指标评测
【Database】向量数据库
【SoC】性能与功耗评估
【MCP】MCP探索
【InnoFrance】一个“关于声音”的有趣项目
【Robotics】写给那些想要快速了解机器人或者具身智能的工程师们
【Robotics】open X Embodiment RT-X 数据集下载与使用和分析
文档发布于【Feng's Docs】
-
+
首页
【yolo】yolov8测试
# 0. Breif 考虑到后续对于端上2D任务的检测,对yolov8系列的模型进行了测试。整体cli的易用性很高,测试过程也比较丝滑。核心是了解yolov8系列模型的能力和性能,并对不同配置下的检测能力和性能做一个数据测试量化。只测试检测模型,其他模型感兴趣可以技术官方参考进行测试整体都是一键式执行。 # 1. Introduction ## 1.1. 设备 * 主机设备cpu i9-12900K 4090显卡 * 端上设备: * Jetson AGX Orin 32GB版本 官方开发者套件  * Atlas 200i DK A2 华为官方开发者套件  * rk3588 野火鲁班猫5代开发板  * 软件版本 * ONNX: starting export with onnx 1.16.2 opset 19... * TensorRT: starting export with TensorRT 10.1.0... * Ultralytics YOLOv8.2.98 🚀 Python-3.8.19 torch-2.4.1+cu121 CUDA:0 (NVIDIA GeForce RTX 4090, 24195MiB) * Pytorch 2.4.1 * onnxRuntime cpu & gpu:1.19.2 ## 1.2. 官方model-zoo |模型|尺寸 (像素)|mAPval 50-95|CPU ONNX 速度(ms)|A100 TensorRT速度(ms)|参数(M)|FLOPs(B)| |---|---|---|---|---|---|---| |YOLOv8n|640|37.3|80.4|0.99|3.2|8.7| |YOLOv8s|640|44.9|128.4|1.20|11.2|28.6| |YOLOv8m|640|50.2|234.7|1.83|25.9|78.9| |YOLOv8l|640|52.9|375.2|2.39|43.7|165.2| |YOLOv8x|640|53.9|479.1|3.53|68.2|257.8| 检测模型参考:https://docs.ultralytics.com/tasks/detect 其他模型参考: * 分类: https://docs.ultralytics.com/tasks/classify * 分割:https://docs.ultralytics.com/tasks/segment * 关键点:https://docs.ultralytics.com/tasks/pose * 跟踪:https://docs.ultralytics.com/modes/track ## 1.3. 基于X86平台的测试与模型导出 |模型|输入像素|文件大小MB|位宽|推理引擎|GPU or CPU|推理速度ms|检测效果示意| |---|---|---|---|---|---|---|---| |YOLOv8x.pt| 640x384|131M|FP32|Pytorch|CPU|175ms|| |YOLOv8x.pt| 640x384|131M|FP32|Pytorch |GPU|6.1ms|| |YOLOv8x-FP32.onnx| 640x640|261M|FP32|onnxRuntime|CPU|250ms|| |YOLOv8x-FP32.onnx| 640x640|261M|FP32|onnxRuntime|GPU|13.0ms|| |YOLOv8x-FP16.onnx| 640x640|131M|FP16|onnxRuntime|GPU|-|| |YOLOv8x-FP32.engine|640x640|396M|FP32|TensorRT |GPU|6.0ms|| |YOLOv8x-FP16.engine|640x640|135M|FP16|TensorRT |GPU|2.4ms|| |YOLOv8x-INT8.engine|640x640|135M|INT8|TensorRT |GPU|1.5ms|| |YOLOv8l.pt| 640x384|84M |FP32|Pytorch |CPU|113ms|| |YOLOv8l.pt| 640x384|84M |FP32|Pytorch |GPU|3.9ms|| |YOLOv8l.onnx| 640x640|167M|FP32|onnxRuntime|GPU|9.9ms|| |YOLOv8l-FP32.engine|640x640|255M|FP32|TensorRT |GPU|4.0ms|| |YOLOv8l-FP16.engine|640x640|88M |FP16|TensorRT |GPU|1.7ms|| |YOLOv8l-INT8.engine|640x640|88M |INT8|TensorRT |GPU|1.3ms|| |YOLOv8n.pt| 640x384|6.3M|FP32|Pytorch |CPU|13.0ms|| |YOLOv8n.pt| 640x384|6.3M|FP32|Pytorch |GPU|1.7ms|| |YOLOv8n.onnx| 640x640|13M |FP32|onnxRuntime|GPU|3.8ms|| |YOLOv8n-FP32.engine|640x640|20M |FP32|TensorRT |GPU|0.9ms|| |YOLOv8n-FP16.engine|640x640|8.9M|FP16|TensorRT |GPU|0.5ms|| |YOLOv8n-INT8.engine|640x640|8.9M|INT8|TensorRT |GPU|0.5ms|| 完整x86 4090log: [【附件】infer-perf-4090.log](/media/attachment/2024/09/infer-perf-4090.log) predict result: [【附件】resultx86-4090.tar.gz](/media/attachment/2024/09/resultx86-4090.tar.gz) ## 1.4. Jetson AGX Orin 测试 == 如果是之前没有在Jetson 平台上执行过TensorRT这里做一个比较详细的说明,以免最终的测试结果出现偏差或者不符合预期 == 1.4.1 & 1.4.2 & 1.4.3 章节做一个详细的解释 ### 1.4.1 在Jetson AGX Orin上使用TensorRT * 不论是RTX的消费级显卡,还是Jetson系列的嵌入式平台都支持CUDA,但是整体硬件架构有所不同。处理一些基础的硬件架构、内存带宽、功耗等大家能够查到的data sheet基础差异外,不容易直观察觉到的差异就是优化与支持方面的差异。 * 应为硬件架构有所不同,所以基于硬件所作的加速,例如tensorRT针对硬件做优化所导出的engine文件并不通用,所以即使是tensorRT使用相同版本,也不能将X86平台基于消费显卡导出的engine文件放到嵌入式平台上使用。 * 兼容性报错 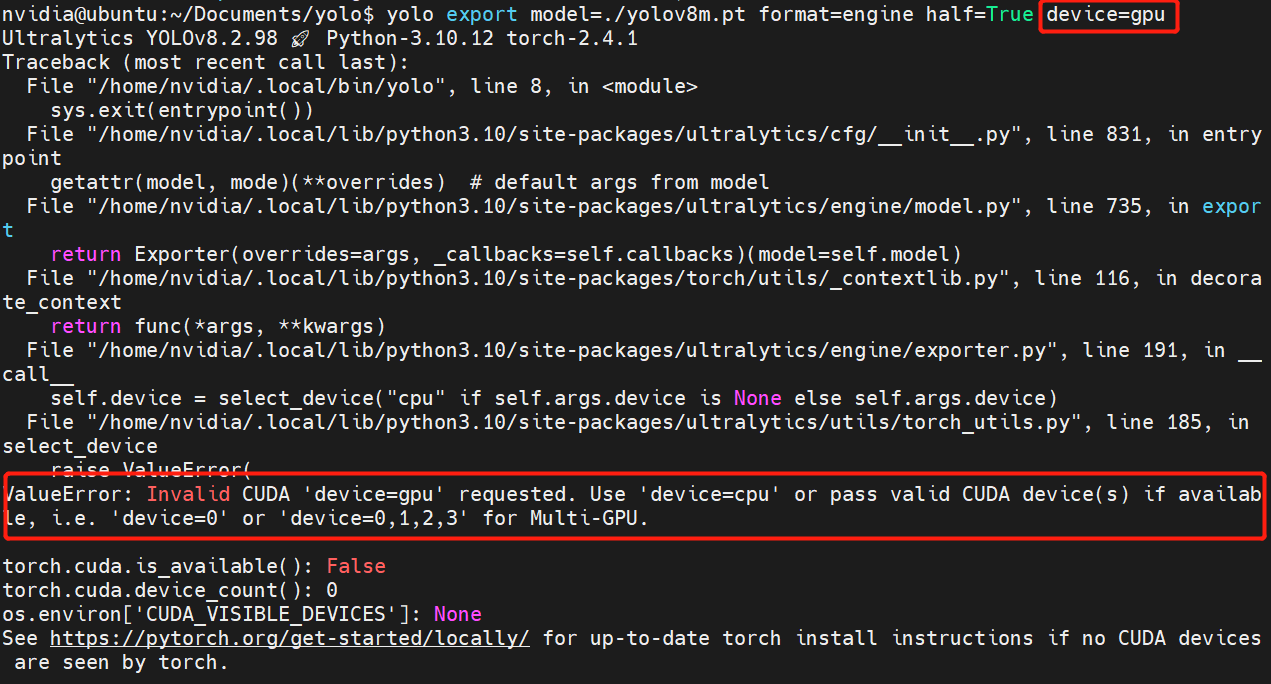 * TensorRT版本问题报错 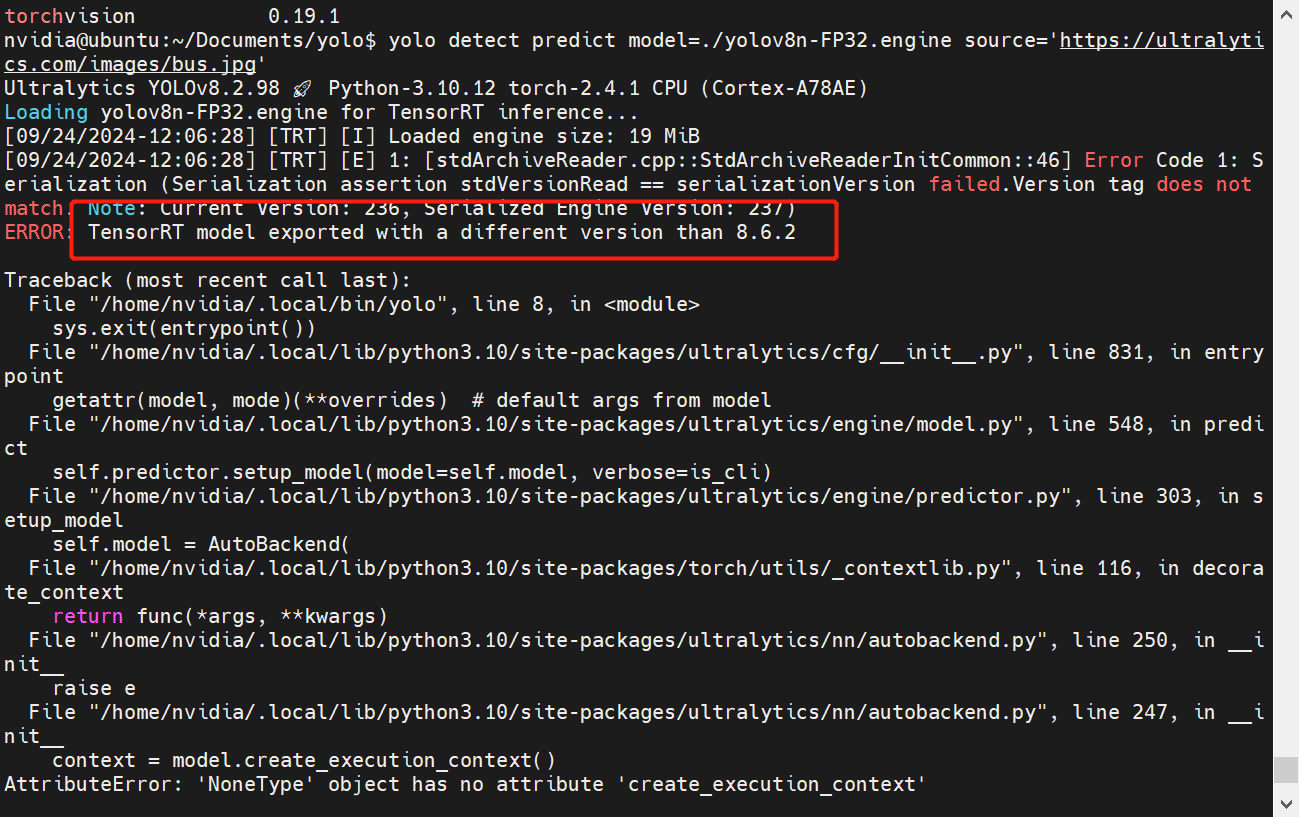 * Torch版本兼容性问题报错 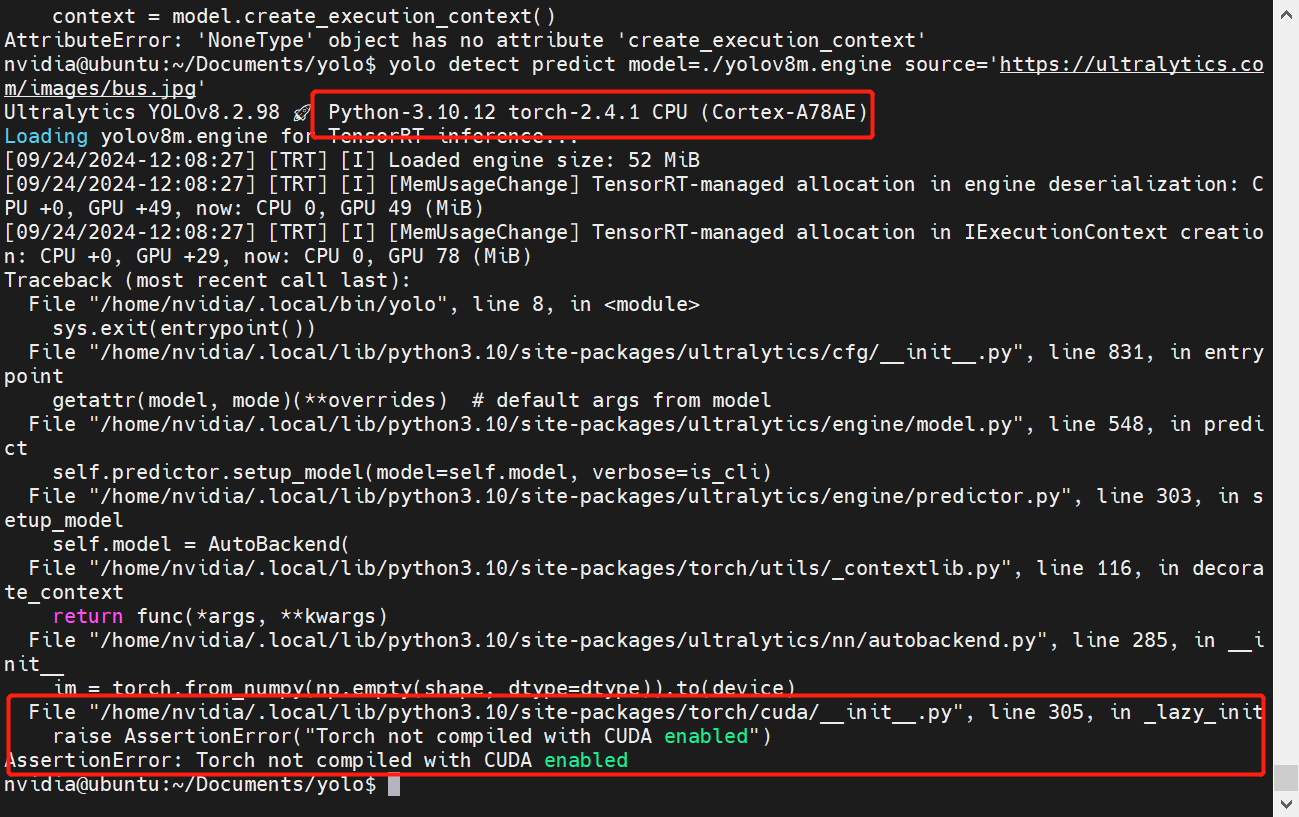 * 同时应该注意的是,如果你是使用Nvidia官方提供的SDK Manager或者docker版本的工具刷写的JetPack设备,默认安装的torch,torchvision版本也都是基于CPU的版本。如果需要在Jetson上使用Pytorch,请使用官方提供的针对于Jetson的Pytorch。下载连接为:https://developer.download.nvidia.cn/compute/redist/jp/ 。注意严格遵从Jetpack的版本下载。 同时选择合适的torchvision,https://github.com/pytorch/vision 否则会出现如下错误 * 默认pytorch为cpu  * 下载对应jetson torch版本  * torchvision版本  * 执行yolo是注意确认所使用的运算单元     ### 1.4.2 从X86端导出模型在Jetson平台上执行的方法 如果想要在X86上完成模型并在Jetson上执行有以下几种方法: * `ONNX模型`,作为一种通用的结构和标准可以将在X86上训练好的模型checkpoint转换为onnx。然后将onnx模型放到target device上去处理,不论是直接使用target端支持的onnxruntime还是基于tvm框架或者是tensorRT框架的优化,抑或是ncnn等都可以直接使用或者间接使用;如果是nv平台可以直接使用平台带的TensorRT的衍生工具`/usr/src/tensorrt/bin/trtexec`(工具能够支持onnx 模型转engine,int8,fp16量化,混合精度等等); * `NVIDIA TAO(Transformation,Adaptation, Optimization) Tookit`,Nvidia官方提供了TAO工具包,可以用于模型的迁移、平台适应和加速;NVIDIA TAO, is a python based AI toolkit that is built on TensorFlow and PyTorch for computer vision applications. It simplifies and accelerates the model training process by abstracting away the complexity of AI models and the underlying deep learning framework. You can use the power of transfer learning to fine-tune NVIDIA pretrained models with your own data and optimize the model for inference throughput — all without the need for AI expertise or large training datasets. * `Docker`,通过构建docker容器来实现在端上的过程。使用Jetson Build Containers。NVIDIA provides a way to remotely generate TensorRT engine files for Jetson devices using Docker containers specifically designed for Jetson platforms. ### 1.4.3 在Jetson AGX Orin平台上执行Yolov8的详细步骤 * 1. (precheck)如果是使用使用sdkmanager刷的新板子,例如Jetpack6.3,可以确认呢以下信息: * l4t  * linux kernal  * python version  * cuda version 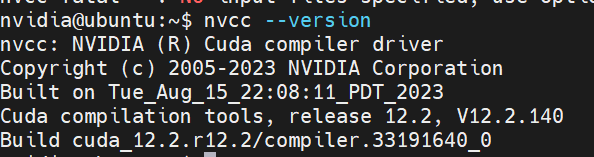 * pip version  * torch & tensorRT  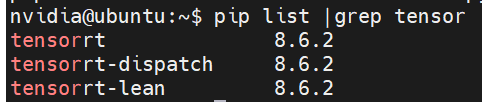 * 2. (install)上述版本信息确认无误后`pip install ultralytics`直接安装yolov8 whl模块 * 3. (cputest)使用`yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'` 确认是否能够正常执行。正常执行应该能看到如下信息,但是此时应该注意的是:此时使用的推理框架为torch,同时是使用cpu进行的推理。推理速度大概在550ms左右。注意此时使用的仅是nano的模型,模型大小差不多是xlarge的1/30, large的1/20,性能很难满足实时性要求。  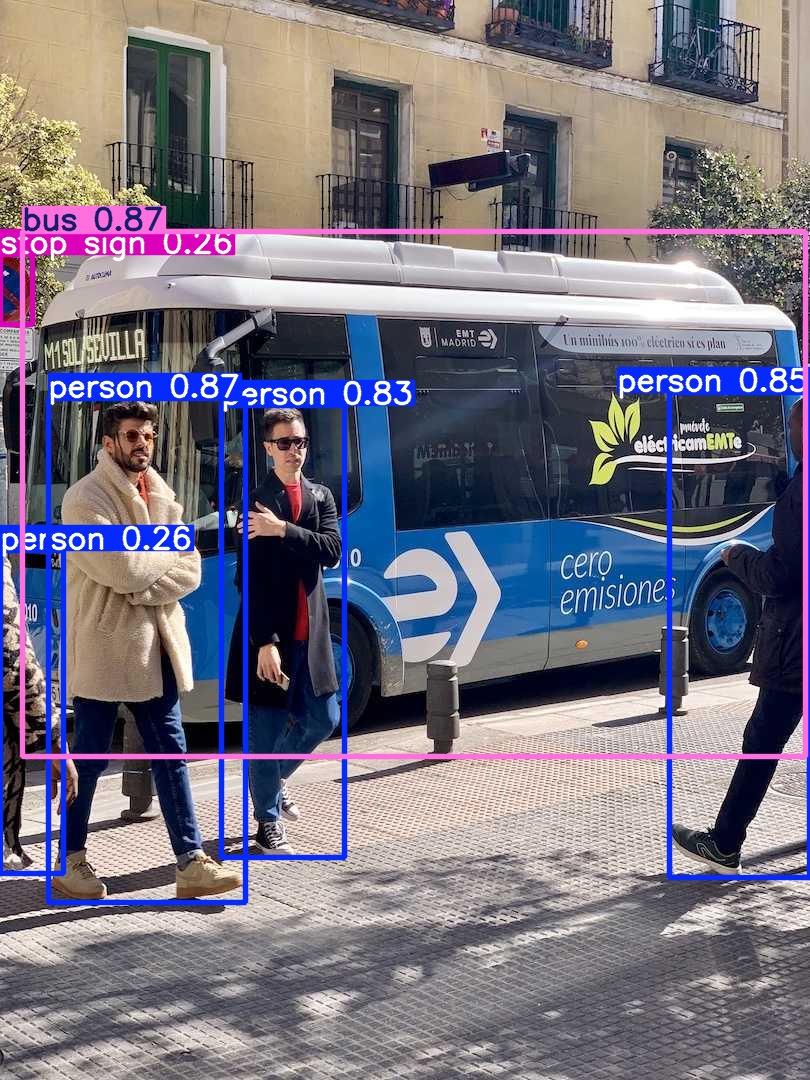 * 4. (gputest)切换torch的jetson版本以满足使用jetson gpu的需求,提高推理速度。 * 安装依赖 sudo apt-get install -y libopenblas-base libopenmpi-dev * https://developer.download.nvidia.cn/compute/redist/jp/ 在连接中下载对应版本的torch whl文件,`wget https://developer.download.nvidia.cn/compute/redist/jp/v60/pytorch/torch-2.4.0a0+3bcc3cddb5.nv24.07.16234504-cp310-cp310-linux_aarch64.whl` * `pip install torch-2.4.0a0+3bcc3cddb5.nv24.07.16234504-cp310-cp310-linux_aarch64.whl` 此时可能会遇到torchvision版本不兼容的问题  * 下载torchvision源码,2.4.0版本的torch对应v0.19.0版本的torchvision。`git clone --branch v0.19.0 https://github.com/pytorch/vision torchvision && cd torchvision && python3 setup.py install --user`。有可能会遇到缺少 libcusparseLt.so.0 库的情况(我的整个镜像都没有)  * https://developer.nvidia.com/cusparselt-downloads 在nvidia官方下载指定版本。并根据如下指令安装0.6.2版本的libcusparseLt库 ``` wget https://developer.download.nvidia.com/compute/cusparselt/0.6.2/local_installers/cusparselt-local-tegra-repo-ubuntu2204-0.6.2_1.0-1_arm64.deb sudo dpkg -i cusparselt-local-tegra-repo-ubuntu2204-0.6.2_1.0-1_arm64.deb sudo cp /var/cusparselt-local-tegra-repo-ubuntu2204-0.6.2/cusparselt-*-keyring.gpg /usr/share/keyrings/ sudo apt-get update sudo apt-get -y install libcusparselt0 libcusparselt-dev ``` 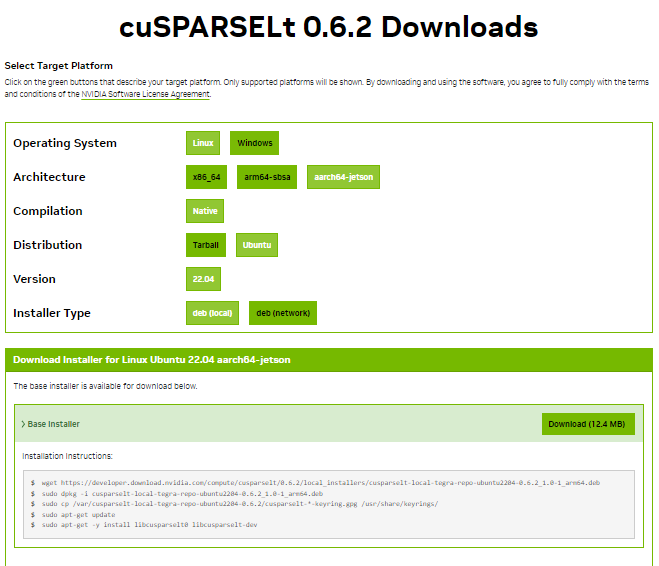 * 如果仍然出现一些nms的问题无法正常使用 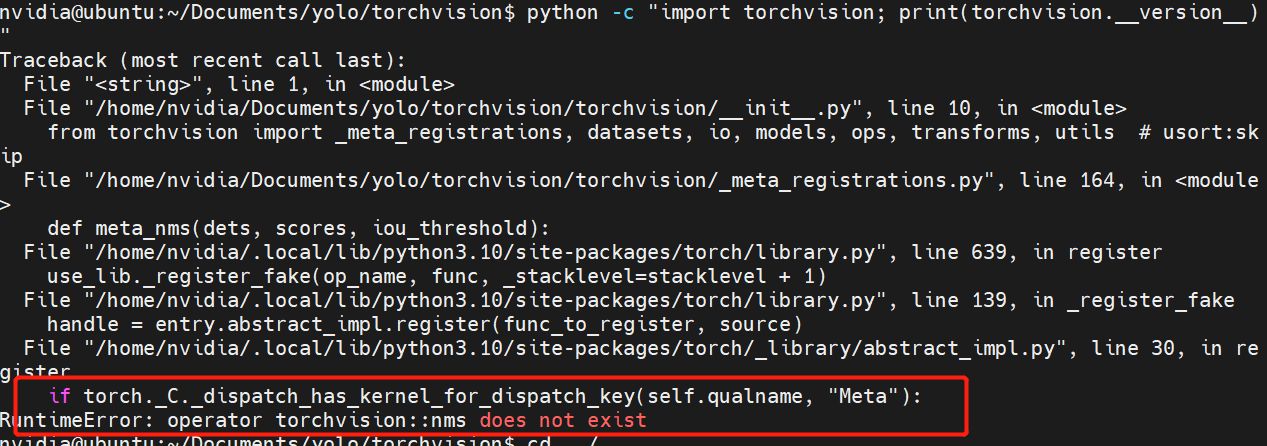可以尝试使用连接中的说明 https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048 切换其他版本的torch和torchvision  * 如果一切顺利,可以看到如下所示的结果。可以看到pytorch已经能够正常使用cuda,`推理速度提升到220ms左右`。并且从整体边框的贴合程度和置信度来看,基本没有差异。  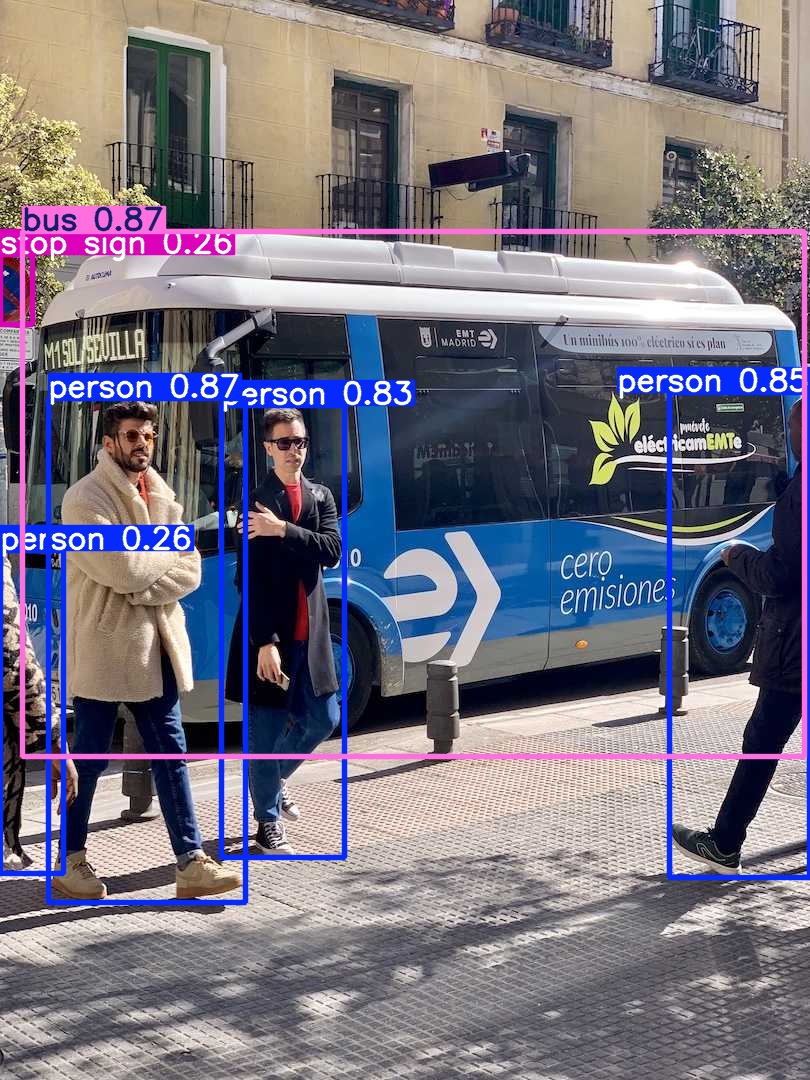 * 5. (tensorRTtest)既然是使用nvidia的平台想要获得更好的性能速度自然要使用TensorRT进行效率优化。这里不再针对TensorRT的基础概念做阐述和说明,直接进行针对TensorRT的使用过程测试,以及结果展示。 * 导出engine文件。`yolo export model=./yolov8n.pt format=engine half=True device=0` device=0表示使用GPU,half=True表示支持FP16(默认False)顺利得话大概十来分钟完成导出 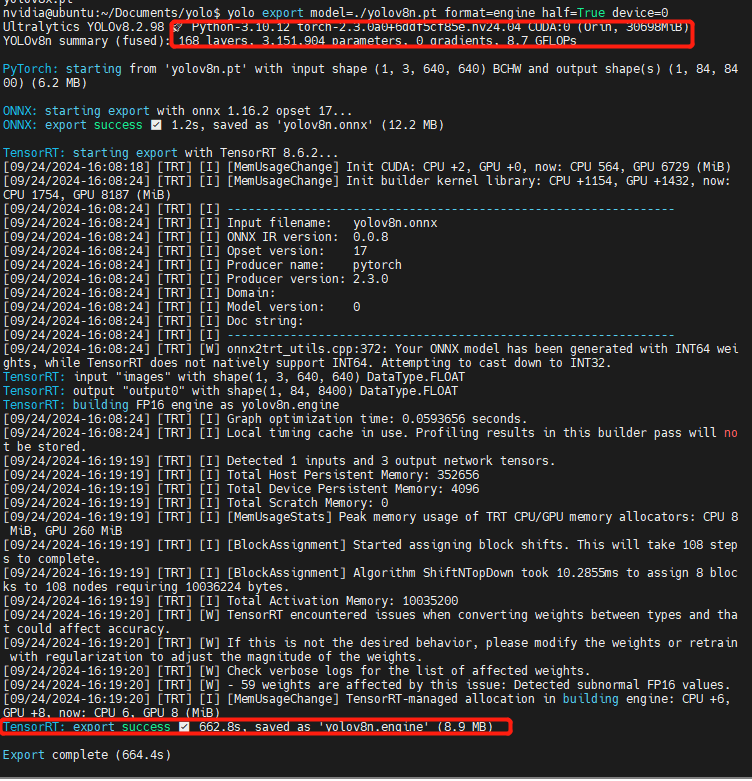 * 执行engine。`yolo predict detect model=./yolov8n-fp16.engine source='https://ultralytics.com/images/bus.jpg'` 可以看到推理速度提升到11.2ms左右。但是也能看到之前能够识别出来得路牌在同一测试数据中消失,部分物体的置信度有所提高,边界框差异不大。`根据以往在tda4等平台上的相关量化经验,fp16混合精度能够在保证精度的情况下,有效提高速度` 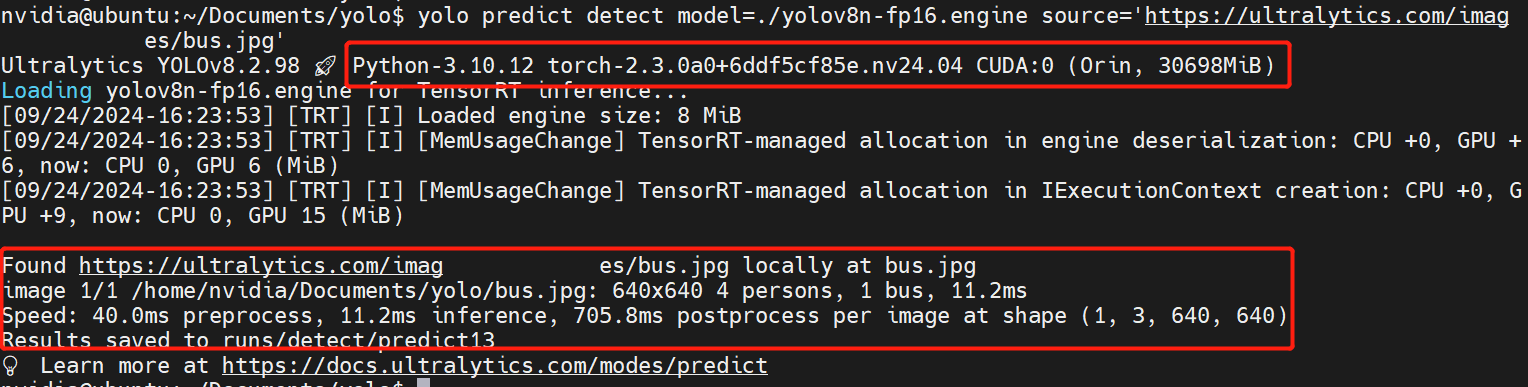 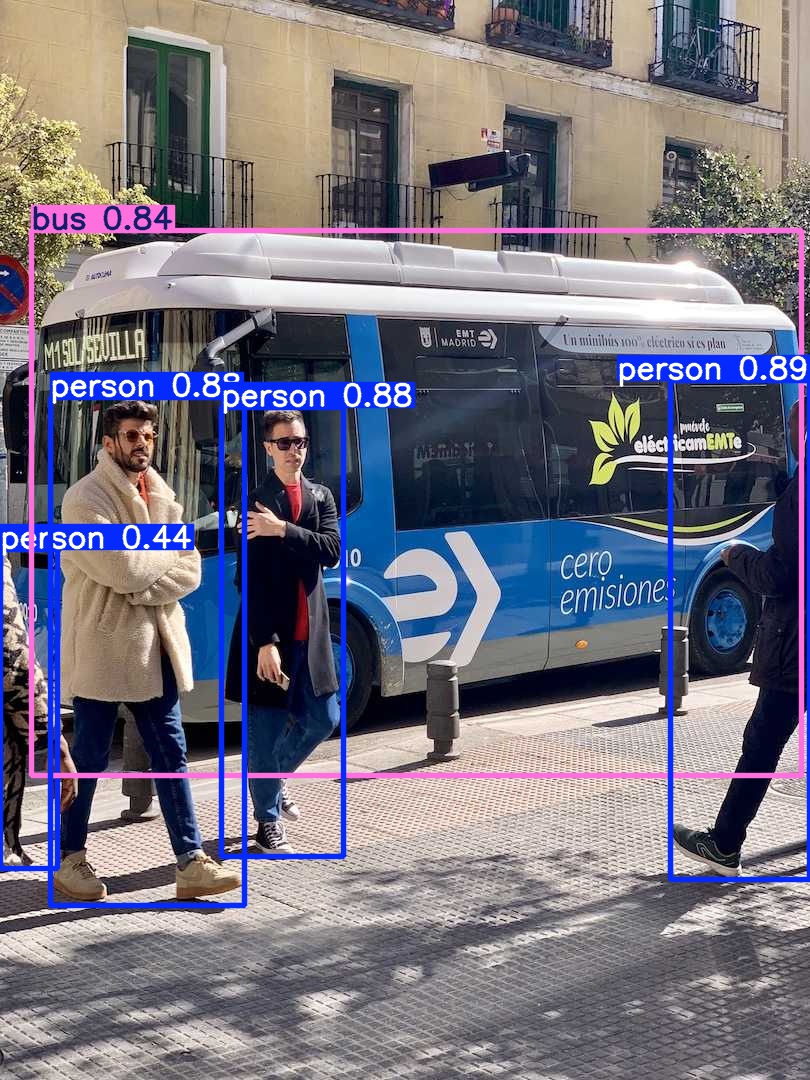 ### 1.4.4 yolov8模型在Jetson AGX Orin上执行的性能分析 通过以上步骤成功在Jetson AGX Orin上执行完yolov8后,我们详细评测以下各个模型的推理速度指标。采用和X86平台上相同的一段在高速场景下的视频。 ==TensorRT: WARNING ⚠️ >300 images recommended for INT8 calibration, found 4 images.== int8导出通常需要更多数据做calibrate,否则可能会因为数据分布不够导致,局部tensor数据分布不均而出现性能问题。所以只选择yolov8x做个速度测试。 |模型|输入像素|文件大小MB|位宽|推理引擎|GPU or CPU|推理速度ms|显存占用MBengine deserialization+IExecutionContext creation| |---|---|---|---|---|---|---|---| |YOLOv8x.pt| 640x640|131M|FP32|Pytorch |CPU|8360ms|| |YOLOv8x.pt| 640x640|131M|FP32|Pytorch |GPU|280ms|| |YOLOv8x-FP32.engine|640x640|265M|FP32|TensorRT |GPU|138ms|260+385| |YOLOv8x-FP16.engine|640x640|133M|FP16|TensorRT |GPU|73ms|130+187| |YOLOv8x-INT8.engine|640x640|70M |INT8|TensorRT |GPU|57ms|66+622| |YOLOv8l.pt| 640x640|84M |FP32|Pytorch |CPU|5559ms|| |YOLOv8l.pt| 640x640|84M |FP32|Pytorch |GPU|240ms| |YOLOv8l-FP32.engine|640x640|171M|FP32|TensorRT |GPU|91ms|166+258| |YOLOv8l-FP16.engine|640x640|86M |FP16|TensorRT |GPU|51ms|83+129| |YOLOv8l-INT8.engine|640x640|46M |INT8|TensorRT |GPU|39ms|42+495| |YOLOv8m.pt| 640x640|84M |FP32|Pytorch |CPU|2725ms|| |YOLOv8m.pt| 640x640|84M |FP32|Pytorch |GPU|232ms|| |YOLOv8m-FP32.engine|640x640|103M|FP32|TensorRT |GPU|74ms|98+160| |YOLOv8m-FP16.engine|640x640|52M |FP16|TensorRT |GPU|38ms|49+78| |YOLOv8m-INT8.engine|640x640|28M |INT8|TensorRT |GPU|28ms|25+432| |YOLOv8s.pt| 640x640|84M |FP32|Pytorch |CPU|1078ms|| |YOLOv8s.pt| 640x640|84M |FP32|Pytorch |GPU|225ms|| |YOLOv8s-FP32.engine|640x640|46M |FP32|TensorRT |GPU|33ms|42+79| |YOLOv8s-FP16.engine|640x640|23M |FP16|TensorRT |GPU|17ms|21+38| |YOLOv8s-INT8.engine|640x640|13M |INT8|TensorRT |GPU|12ms|10+203| |YOLOv8n.pt| 640x640|6.3M|FP32|Pytorch |CPU|390ms|| |YOLOv8n.pt| 640x640|6.3M|FP32|Pytorch |GPU|221ms|| |YOLOv8n-FP32.engine|640x640|16M |FP32|TensorRT |GPU|18ms|12+30| |YOLOv8n-FP16.engine|640x640|8M |FP16|TensorRT |GPU|11ms|6+16| |YOLOv8n-INT8.engine|640x640|5M |INT8|TensorRT |GPU|9.7ms|7+195| 完整的jetson AGX Orin log: [【附件】infer-perf-jetson-agx-orin.log](/media/attachment/2024/09/infer-perf-jetson-agx-orin.log) predict result: [【附件】result.tar.gz](/media/attachment/2024/09/result.tar.gz) ### 1.4.5. 其他找到的第三方测试结果 == 第三方测试时考虑了性能问题,将设备调整为最大功耗且关闭了图形界面。本文测试时均有图形界面。== 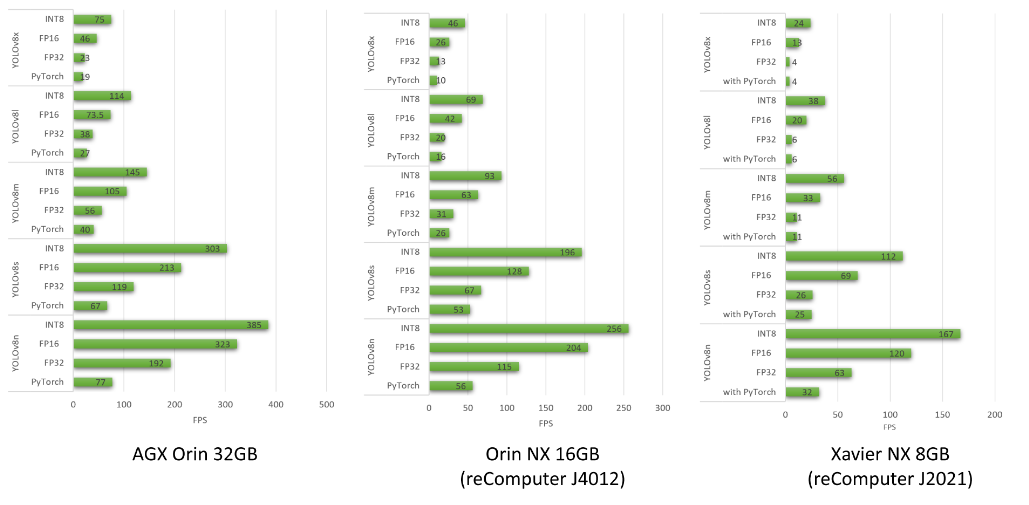 # 2. 瑞芯微rk3588平台测试 ## 2.1. 介绍 rk3588的详细性能不做过多介绍,这里主要展示和介绍以下如何在平台上运行yolov8的基本过程并且给出相关性能结果。这边因为使用的是集成了rk3588芯片的鲁班猫luban cat5平台,所以提到“硬件平台”一律指代该平台。这个过程分为两步,一部分是介绍在平台上执行yolov8 track的详细流程,一个是评测以下yolov8detect的性能。`因为rknn toolchian的example中默认只给了yolov5的demo,相关yolov8的部分需要结合rknn在yolov8仓库上fork的分支配合model_zoo和toolchain完成,并且处于推理速度考虑一律使用relu代替silu,同时因为考虑到检测狂角度需要使用obb模型,所以这边针对yolov8的详细评测还是比较有实际工程部署的参考价值,同时也能够针对rknn的工具链使用做一个基本了解,整个关于yolov8在平台上的改造放在Annexe 2. Optimization of Yolov8 on rk3588中做说明`。 ## 2.2. 评测目标 * 完成yolov8s tracker的rknn部署,跟踪后处理跑在A核上(选择核原版yolov8 一样的ByteTrack),如果性能不满足至少30帧的性能要求,需要进行进一步优化,`根据性能要求考虑选择n,s,m版本的yolo模型` * 评测yolov8n、s、m的推理速度和和FP16,INT8量化,混合精度后的结果对比 * 评测yolov8n、s、m,obb模块的效果 ## 2.3. 部署流程 1. 准备pt模型(默认执行yolov8命令行时就会下载,操作在orin章节已经做了介绍,不做赘述),导出onnx模型(`yolo export model=./yolov8n.pt format=onnx`); 2. 使用onnxsim工具包对onnx模型进行图优化简化,`python -m onnxsim yolov8.onnx yolov8_simplified.onnx`。整个过程:一个是对计算过程进行折叠和算子融合操作;一个是在使用netron等工具进行打开时可以看到详细的张量尺寸;还有一个总结结果可以针对工具链对算子的支持进行比较,确认是否存在不支持的算子要进行裁切等操作; * [【附件】yolov8n.onnx](/media/attachment/2024/10/yolov8n.onnx) * [【附件】yolov8n_simplified.onnx](/media/attachment/2024/10/yolov8n_simplified.onnx) * 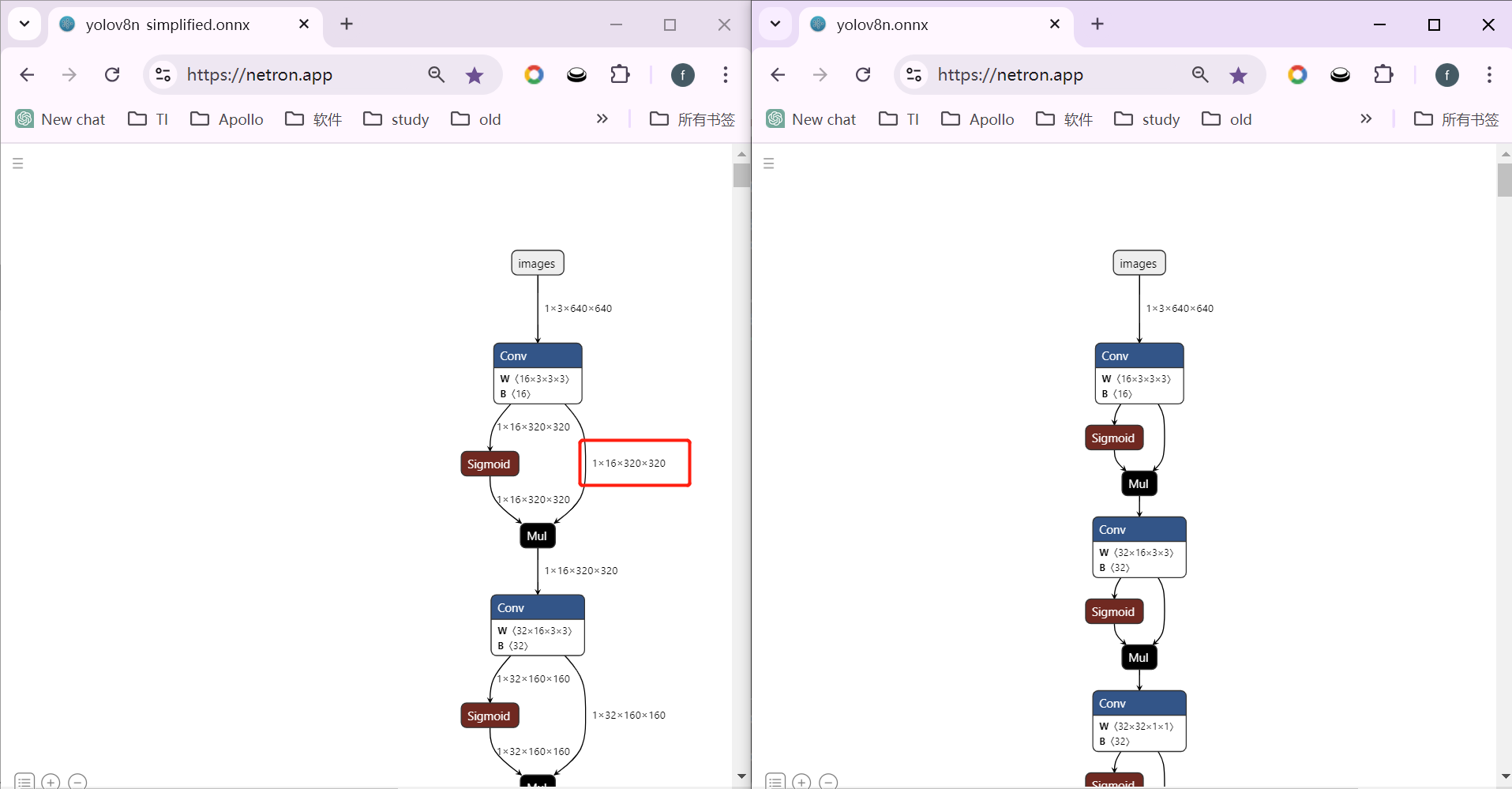 * 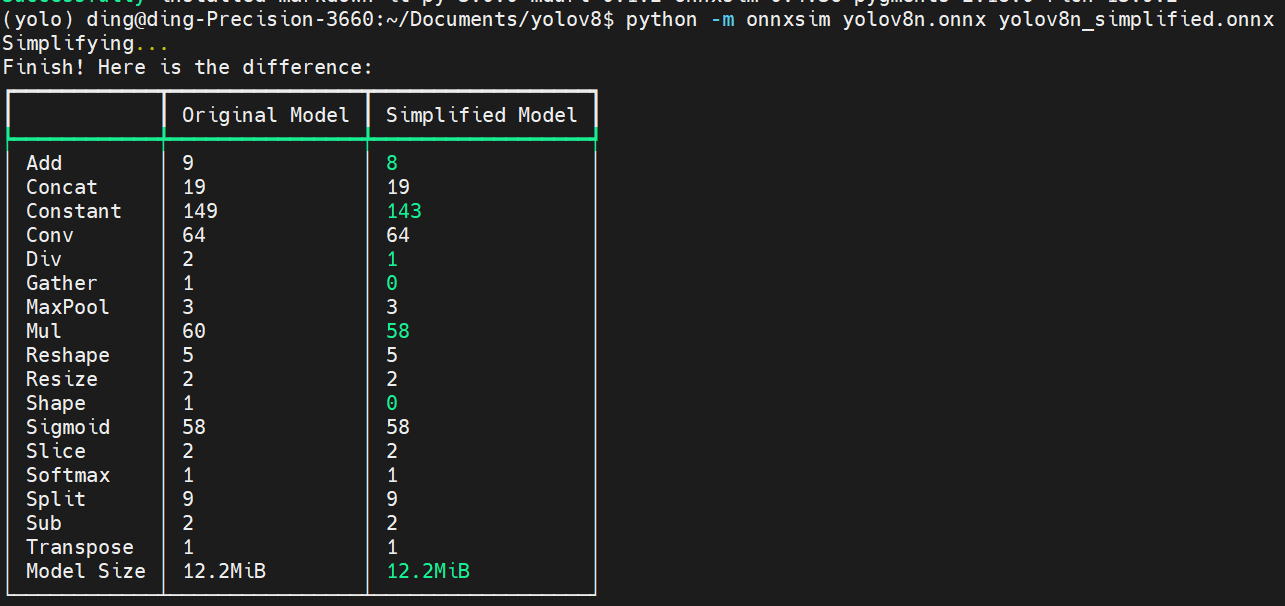 3. 使用rknn提供的工具链。文档虽多,但是猛的看起来感觉文档不是特别清楚,相比较昇腾整个的文档生态,这里使用一张图简单说明以下rknn提供的工具链。  4. 使用rknn-toolkit2提供的工具参考example中的内容进行模型转换`python3 -m rknn.api.rknn_convert -t rk3588 -i ./model_config.yml -o ./test/`  * `model_config.yml` 进行相关模型导出配置 ``` (rknn) ding@ding-Precision-3660:~/Documents/rockchip/rknn-toolkit2/rknn-toolkit2/examples/onnx/yolov8n$ cat model_config.yml models: name: yolov8n_simplified # 模型输出名称 platform: onnx # 原始模型使用的框架 model_file_path: yolov8n_simplified.onnx #原模型路径 quantize: true # 是否量化 dataset: ./dataset.txt # 量化dataset文件路径(相对yml路径) configs: quantized_dtype: asymmetric_quantized-8 # 量化类型 mean_values: [0, 0, 0] # rknn.config的mean_values参数 std_values: [255, 255, 255] # rknn.config的std_values参数 quant_img_RGB2BGR: false # 不进行RGB2BGR转换 quantized_algorithm: normal # 量化算法 quantized_method: channel # 量化方法 ``` * `dataset.txt` 配置data calibration PTQ用的数据 * `yolov8n_simplified.onnx` onnx模型 ## 2.4. 关于model_zoo * 由于相关结果操作对于npu的适配有一定改动所以直接使用yolov8原本的pretrain onnx无法得到较为理想的结果;所以这里就索性直接使用官方基于yolov8仓库的fork适配的结果;https://github.com/airockchip/ultralytics_yolov8/commit/4674fe6e003dfbc5f2250d3b39dd31faaf7a9877#diff-85438f455209dbcd572a74bf67c26270ab3c5fe4f32b98ea2de15e538c00f8d4R21 (相关修改该调整内容的解析见Annexe 2) * 目前yolov8有predict,obb和pose,seg的输出,其他暂不支持。obb输出效果不理想精度较差。 * 获取yolov8的模型有两种方式,一种是直接在https://github.com/airockchip/rknn_model_zoo/tree/main/examples/yolov8/model 中执行download脚本下载。另一种方式就是,直接在https://github.com/airockchip/ultralytics_yolov8 rknn fork的分支通过修改./ultralytics/cfg/default.yml 并执行 ./ultralytics/engine/exporter.py进行适配rknn版本的onnx模型的导出。再将onnx模型通过2.3中的toolchain进行onnx 转 rknn文件的转化 * yolov5的版本可以直接在X86端进行模拟输出模拟的结果,但是yolov8的后处理由于处理逻辑和处理方式的差异需要自己适配 * 关于量化,目前rknn提供的量化方案中针对rk3588,只有非对称8,非对称u8和a16w16可用,目前看非对称8效果最好(==这个确实也有点存疑,关于混合精度的效果不是特别理想==) ## 2.5. 评测结果 * 推理用时来看,n,s的差异不大,可以优先考虑s版本。 |类型|推理用时ms(单帧/连续帧warmup)| 量化位宽 | 效果 | |----|----|----|------| |yolov8n 7.0 GFLOP|49/23|INT8|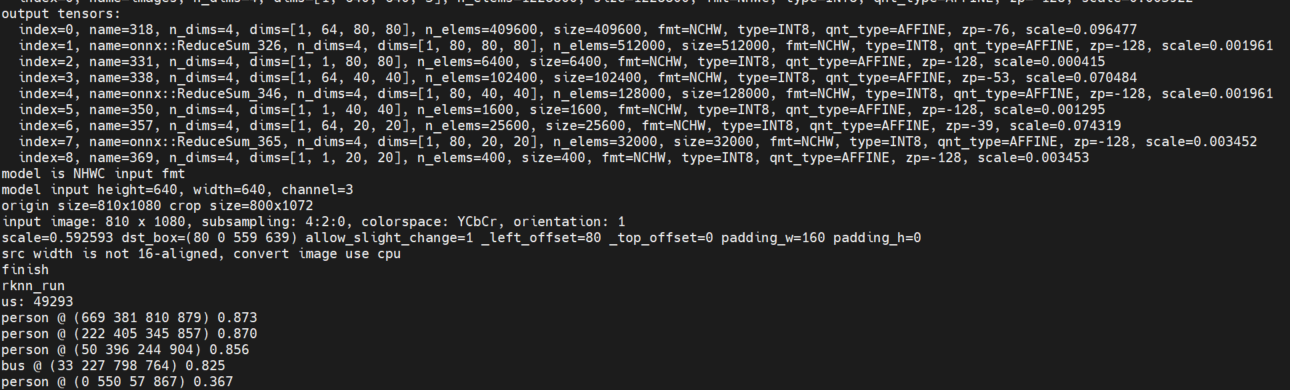| |yolov8s|57/39|INT8|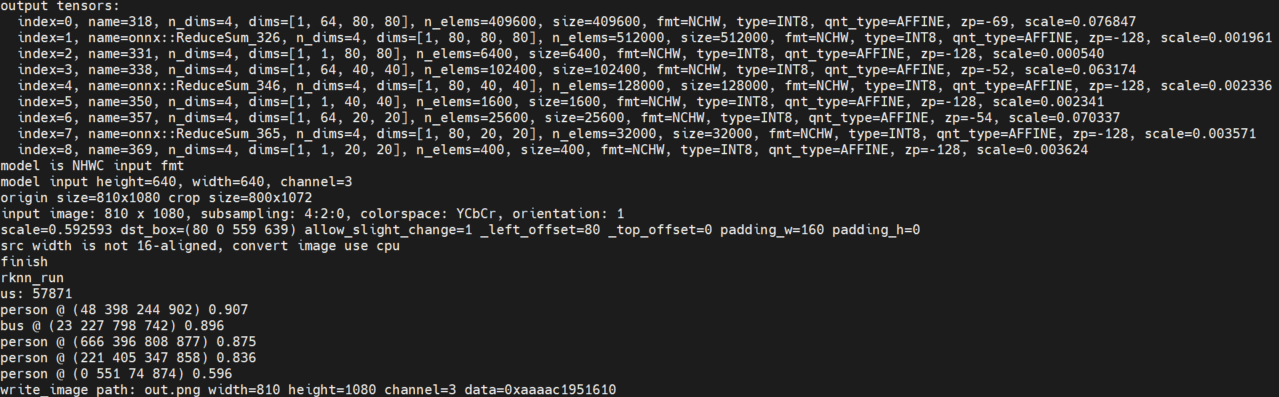| |yolov8m|113/85|INT8|| 这里带一个多帧结果的连续帧评测视频,用的是官方的yolov8m的模型,推理耗时平均为80-100ms左右。 [【附件】output.mp4](/media/attachment/2024/10/output_JC1khPR.mp4) * 跟踪这边直接使用bytetrack的cpp版本用于测试,https://github.com/Vertical-Beach/ByteTrack-cpp ,具体参数为frame_rate = 10(yolov8m帧率差不多为10fps左右,根据实际使用进行调整),trackbuffer = 100(实际追踪的物体数量,这个根据应用场景进行调整),track_thresh = 0.2 (检测的置信度超过这个与之才会被用来监控状态),high_thresh = 0.3 (跟踪后计算的置信度超过这个阈值才会被输出) match_thresh = 0.8。 * 整体在rk3588 cpu(a核上的推理耗时)不超过5ms(差不多跟踪20个左右的物体,每次输入20个左右的detection),因为是快速实现的代码,所以在性能方面仍然有优化空间 [【附件】output.mp4](/media/attachment/2024/10/output_eReVwTr.mp4)  # 3. 华为Atlas 200i DK A2 开发板测试 # Annexe 1. Reference * yolov8-doc: https://docs.ultralytics.com/modes/predict/ * yolov8-github: https://github.com/ultralytics/ultralytics * install pytorch on Jetson: https://docs.nvidia.com/deeplearning/frameworks/install-pytorch-jetson-platform/index.html * correspondant version: https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048 * https://wiki.seeedstudio.com/cn/How_to_Train_and_Deploy_YOLOv8_on_reComputer/ * https://wiki.seeedstudio.com/cn/YOLOv8-DeepStream-TRT-Jetson/ * https://wiki.seeedstudio.com/cn/YOLOv8-TRT-Jetson/ * https://github.com/NVIDIA-AI-IOT/nvidia-tao * nv TAO doc: https://developer.nvidia.com/tao-toolkit-get-started * nv TAO github: https://github.com/NVIDIA/tao_tutorials # Annexe 2. Optimization of Yolov8 on rk3588 ## A.2.1. 模型端改造 * 从骨干网可以看到,yolov8的网络层分成了三个分支 分别对应8倍(80*80),16倍(40*40)和32倍(20*20)下采样p3,p4,p5,然后在neck上使用PAN-FPN进行多尺度特征融合,然后在Head上针对每个特征图进行类别和位置信息的预测 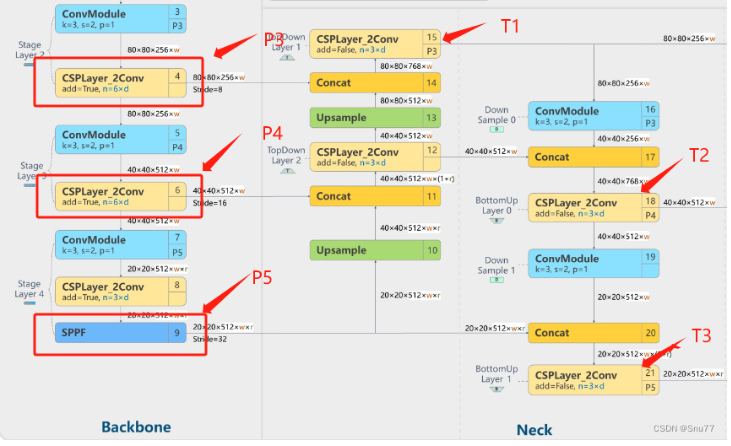   * 从实际yolv8n.onnx模型可以看到相关输出。考虑到npu上对于后处理【也就是图中从多尺度输出后,到解析出1*84*8400的最终输出,8400个 1(batch)* 84(xyhw+80个类别置信度)的输出】的友好性,在进行模型导出时对后处理部分做了调整而将从(1*64*20*20,1*80*20*20,1*64*40*40,1*80*40*40,1*64*80*80,1*80*80*80)到最终输出的结果调整到cpu上进行处理(更改输出节点,移除模型中的后处理操作: YOLOv8 的模型在原始设计中通常会包含一些后处理步骤,例如将检测框的边界框值解码、非极大值抑制(NMS)等。这些步骤在模型内部实现时,可能对量化过程不友好。模型量化是指将浮点数表示的参数转换为较低精度(如 INT8)以加快推理速度和减少内存消耗。量化过程中,后处理步骤往往因为涉及复杂的浮点计算而难以量化。因此,移除这些后处理操作,并将它们转移到模型外部的推理后处理部分,可以减少量化的难度,并提高模型推理的效率) [【附件】yolov8n_simplified.onnx](/media/attachment/2024/10/yolov8n_simplified_y4O4RXJ.onnx)  [【附件】yolov8n.onnx](/media/attachment/2024/10/yolov8n_a8x7dGT.onnx) 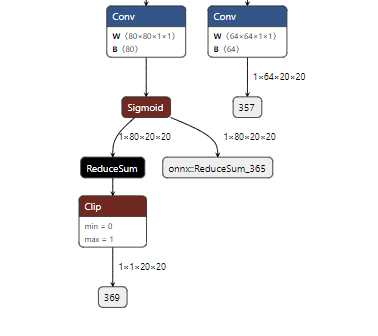 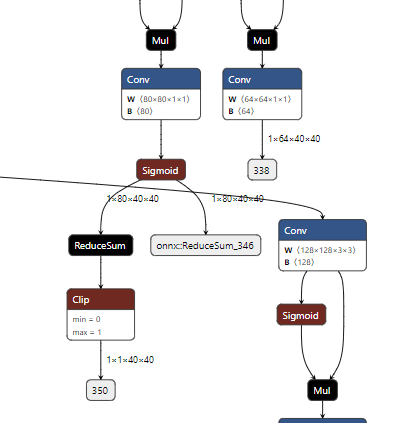 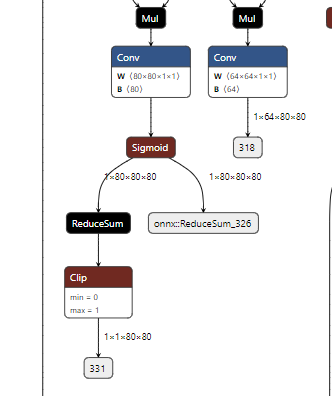 * 移除模型末端的 DFL(Distribution Focal Loss)结构: DFL 是 YOLOv8 中的一种损失计算结构,通常用于更好地拟合目标检测框的分布。然而,在某些硬件(如 NPU)上,DFL 结构的计算开销较大,可能会显著降低推理速度。因此,移除 DFL 结构,可以避免这些计算开销,从而提升 NPU 设备上的推理速度。这一改动不会影响模型的核心检测能力,但在追求高效推理的场景下是有益的。 * 添加 score-sum 输出分支以加速后处理: 后处理过程中,通常需要计算每个目标的置信度分数,并进行筛选、排序等操作。通过在模型中添加一个专门计算分数总和的输出分支,可以加速这些后处理操作。这个分支直接输出每个检测结果的总分数(例如,类别分数和置信度的乘积),从而减少在外部进行额外计算的时间。这一优化加快了后处理过程,特别是在多目标检测时,能够显著减少推理后的处理时间。
dingfeng
2024年10月10日 14:51
4268
0 条评论
转发文档
收藏文档
上一篇
下一篇
评论
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码