Public Docs
【模型量化】深度学习模型量化 & 量化理论 & 各平台的量化过程 & 硬件加速
【TVM】TI关于TVM的使用测试与分析
【LLM&LVM】大模型开源工程思维导图
SmartSip
【北航卓越工程师】《汽车前沿技术导论:智能驾驶》讲义
【工具链】Yocto使用介绍——使用Yocto创建一个树莓派的系统镜像
【工具链】使用ssh+dialog指令设定服务器指定用户仅容器访问
【推理引擎】一篇关于模型推理的详细对比与学习
【推理引擎】关于TVM中的Schedule优化详解(On going)
【LLM微调】使用litgpt进行私有数据集模型微调的测试总结
【TVM】在TVM Relay中创建一个自定义操作符
【STT+LLM+TTS】如何使用语音转文字模型+大预言模型+语音生成模型完成一个类人的语音交互机器人
【RAG】 通过RAG构建垂直领域的LLM Agent的方法探索
【RAG】GraphRAG精读与测试(On going)
【AI Agent】MetaGPT精读与学习
【AI Base】Ilya Sutskever 27篇必读论文分享清单
【Nvidia】Jetson AGX Orin/ Jetson Orin nano 硬件测试调试内容(On going)
【BI/DI】LLM Using in BI Testing Scenario (On going)
【Nvidia】How to Activate a Camera on Nvidia Platform in Details
【RAS-PI】树莓派驱动开发
【行业咨询阅读】关注实时咨询和分析
【mobileye】2024 Driving AI
【mobileye】SDS_Safety_Architecture
【yolo】yolov8测试
【nvidia】Triton server实践
【alibaba】MNN(on updating)
【OpenAI】Triton(on updating)
【CAIS】关于Compound AI Systems的思考
【Nvidia】关于Cuda+Cudnn+TensorRT推理环境
【BEV】BEVDet在各个平台上的执行效率及优化(On Updating)
【Chip】AI在芯片设计和电路设计中的应用
【Chip】ChiPFormer
【Chip】关于布线的学习
【Chip】MaskPlace论文精读与工程复现优化
【gynasium】强化学习初体验
【Cadence】X AI
【transformer】MinGPT开源工程学习
【中间件】针对apollo 10.0中关于cyberRT性能优化的深度解读和思考
【Robotics】调研了解当前机器人开发者套件(on updating)
【Robotics】ROS CON China 2024 文档技术整理与感想总结(上2024.12.7,中2024.12.8,下场外产品)
【algorithm】关于模型、数据与标注规范的平衡问题
【nvidia】DLA的学习了解与使用
【nvidia】构建nvidia嵌入式平台的交叉编译环境(其他环境平台可借鉴)
【2025AI生成式大会】2025大会个人总结
【Robotics】 Create Quadruped Robot RL FootStep Training Environment In IsaacLab
【Robotics】如何一个人较为完整的完成一个机器人系统软件算法层面的设计与开发
【VLM】读懂多模态大模型评价指标
【VLM】大模型部署的端侧部署性能与精度评估方法与分析
【Nvidia】Jetson Orin 平台VLM部署方法与指标评测
【Database】向量数据库
【SoC】性能与功耗评估
【MCP】MCP探索
【InnoFrance】一个“关于声音”的有趣项目
【Robotics】写给那些想要快速了解机器人或者具身智能的工程师们
【Robotics】open X Embodiment RT-X 数据集下载与使用和分析
文档发布于【Feng's Docs】
-
+
首页
【AI Agent】MetaGPT精读与学习
# 1 Introduction 智能体框架是未来AI应用提升生产力的一个重要方向,如下图所示是MetaGPT简称MG构建智能体的一个基本思路. 那就是: * `智能体`是以`LLM`为基础, 通过`记忆`信息和行为`规划`,使用`工具`完成相关任务. * 而`多智能体` 在确定的`环境`下, 以标准的`SOP`, 通过对需求 方案 目标 等进行`评审`, 通过路由+消息订阅的方式完成整个协作的过程.  # 2 Description ## 2.1 所以首先第一步就是要先了解开源大模型的能力 * 下图是目前大模型的排行榜[MMLU](https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu)还是一个比较标准的能衡量大模型能力的评价指标.  * 如MG一作Alex WU所说的, 随着大模型整体能力的提升, 冰山之上的模型能力也会越强. 目前的MG框架受限于LLM本身的能力, 如果需要开发一些较为复杂的APP, 会有明显的差异. 我使用ollma, gpt3.5-turbo和gpt-4-turbo分别测试了同一个prompt `"Create a 2048 game"`, 只有使用gpt-4-turbo的模型完成了这一任务. 其他两个模型都在完成了相关PRD分析后, 在写的main.py中交了枪。 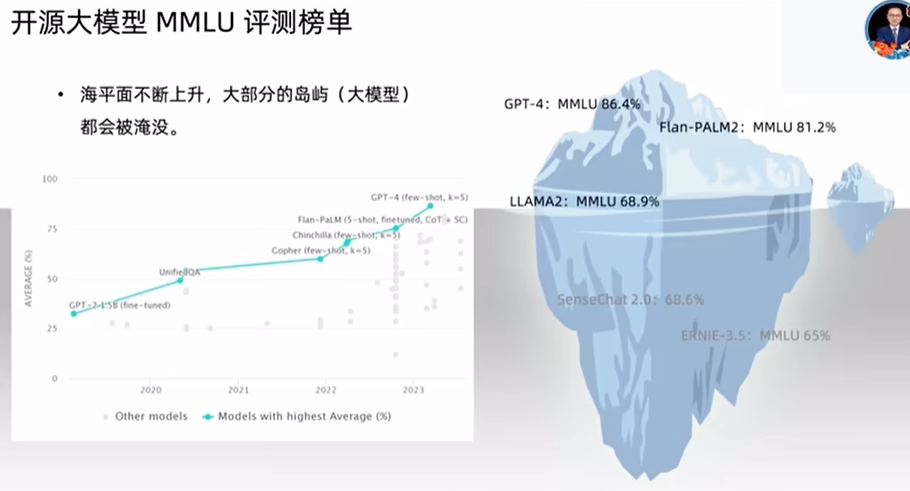 * 从MG的Roadmap可以看到, 整个框架面向未来当然是为了实现模型自主训练\自主微调\与进化. 但是当下短期目标仍然是为了实现能够完成一个较为复杂的由2000行代码构成的app。  * MG目前已经能够支持18种provider下的上百种模型, 可以预见几件事: 1. 未来大模型提供的api能力和token数量一定会越来越强, 未来大模型应用会卷出花样; 2. AI agent随着可接入的llm的种类和类型的增多, 从以LLM为主的方式, 也可能会增加例如LVM或者LAM(Large Audio Model)这种. 如果能够增加其他类型的SOP Role, 也不是没可能从software company 变身为 MCN company或者是律师事务所等等. 当然从目前实测来看 Agent还是无法做到让工作有灵魂。 Anthropic / Claude API Zhipu API iFlytek's large model Spark API : Azure OpenAI API Google Gemini Baidu QianFan API Use security authentication AK/SK to authenticate Use application AK/SK to authenticate (Not Recommended) Aliyun DashScope API Moonshot / Kimi API Fireworks API Mistral API Yi / lingyiwanwu API ollama API WizardLM-2-8x22b via openrouter Llama-3-70b instruct via openrouter Llama-3-70b via groq Amazon Bedrock API ## 2.2 实际测试体验的几点感受 ### 2.2.1 关于PRD * 测试了几种不同类型的大模型的表现, 在未添加搜索引擎的情况下, 部分Task任务其实完成的更像是一种形式, 例如competitive analysis, 甚至还会出现一些乱分析的情况. 这块确实有点受限于模型本身的能力. 如下图所示, 在未找到有效数据的情况下`捏造`了一些结果: 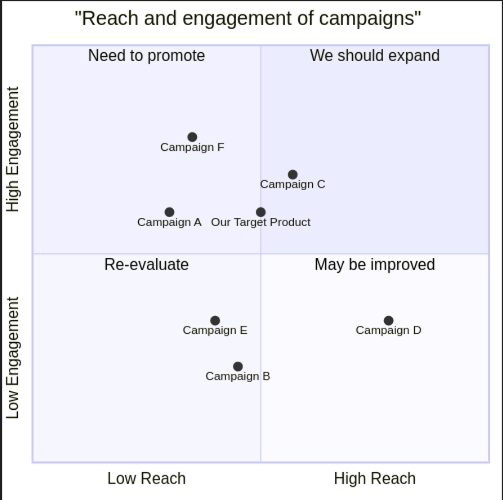 # 3 Metagpt精读 实操完MG,整体精读一下作者的逻辑和整个工程。 首先,作者指出了整个MG的工程构建哲学。那就是作为一家软件公司,Code = SOP(Team)。Code代码,SOP标准化流程和Team团队,是一家软件公司的核心。 大模型的推理能力决定了,能否当前构建工程复杂度的上限。openai的技术报告中有提到,其中有一个指标是一次性完成代码的正确率,差不多只有40%。 但是open ai 提出了一个概念叫step by step,也就是说你可以引导AI去一步一步实现你的想法。当尝试次数达到10^3次时, 成功率可以提升到80%。 https://artificialanalysis.ai/ 吴恩达在X上分享了一个当前大模型API的能力介绍,能够比较综合的帮助我们在选择业务场景对应的大模型API时可以参考的信息。 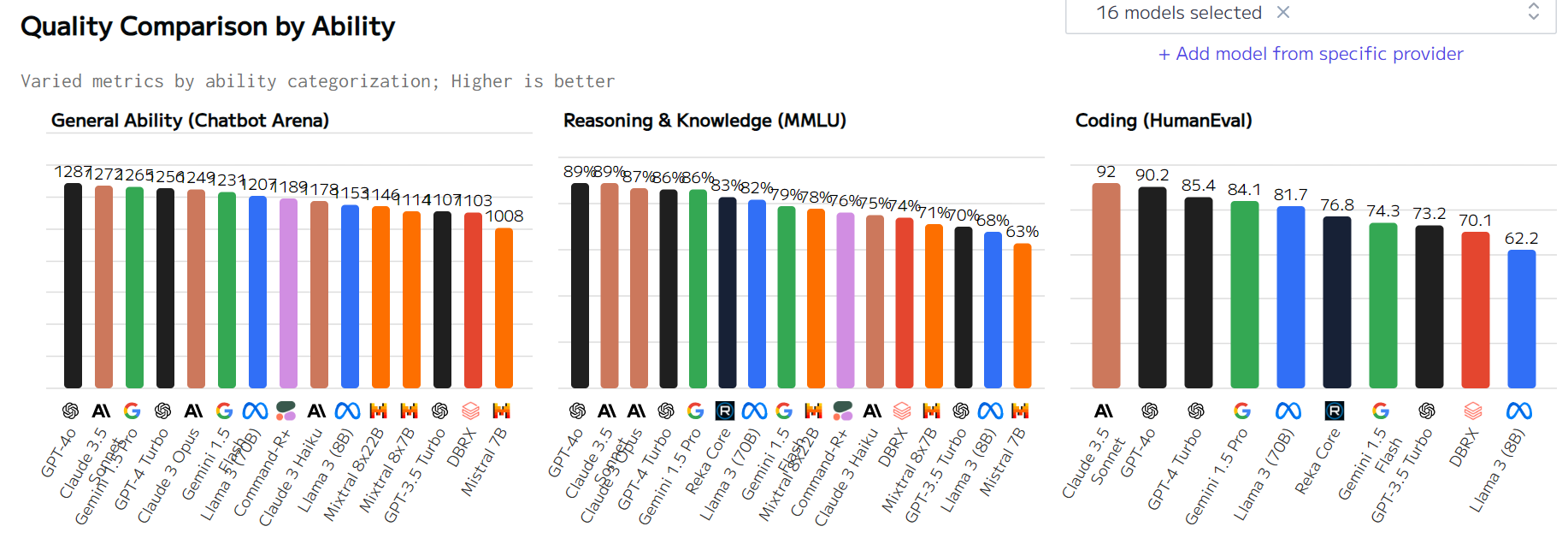 从细分对coding的能力来说,llama3和gpt3.5turbo 相比于gemini1.5 gpt4系列和claude3 差距还是很明显的。 这样的统计现象也在测试metaGPT采用不同的大模型api时得到了主观验证确实效果有比较大的差距。 另外,https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu mmlu从整个数据中可以看到,目前开源模型的能力差不多MMLU是将近70,和目前顶级的模型差不多还相差将近25。 从上面的coding能力,质量和推理理解能力来说,可以直观感觉60%,70%, 80%好像差距没有那么大。但是这里面还有另外一个视角,那就是我们从错误率的角度来比较,80%出错率是20%, 60% 出错率是40%,那其实60分的模型出错的概率实际上是要比80分的模型出错概率增加了一倍,这样一个差距用来做实际应用差距是非常明显的。 ## 3.1 工程结构 * 项目基础结构 ``` mindmap # workspace ## action 描述各种智能体的动作 ## config(?) ## Document store 文档化接口,如飞书文档等,用于使用并保存技术文档 ## environment ## ext ## learn 作为一个智能体,也需要学习,一些学习内容都放置于此 ## management 智能体管理,用来作为一个long term view 智能体是可以自主被生产的 ## memory 记忆。和人一样用来保存长短记忆 ## prompts 提示词 ## provider 第三方llm api扩展 ## rag ## roles 各种各样的智能体角色 ## skills ## strategy ## tools 工具,搜索引擎,图转文字,文字转图,等等 ## utils 可用接口 ## context.py ## llm.py ## software_company.py ## team.py ``` * 整体项目结构的说明 ``` mermaid mindmap root((Metagpt)) action 描述各种智能体的动作 config(?) document_store 文档化接口,如飞书文档等,用于使用并保存技术文档 environment ext learn 作为一个智能体,也需要学习,一些学习内容都放置于此 management 智能体管理,用来作为一个long term view 智能体是可以自主被生产的 memory 记忆。和人一样用来保存长、短记忆 prompts 提示词 provider 第三方llm api扩展,目前支持18种 rag roles 各种各样的智能体角色 skills strategy tools 工具,搜索引擎,图转文字,文字转图,等等 utils 可用接口 Files context.py llm.py software_company.py 程序入口,通过typer定义了相关cli指令。sc作为整个工程的入口,软件公司首先要有一个团队,team.py中的Team创建团队。然后通过environment模块种的Environment传入环境变量。然后为Team hire各种role种定义的角色。 team.py 定义一个团队的基本要素。包含人员雇佣hire,团队目标idea,目标执行预算invest,和项目执行run_project(start_project is deprecated) ``` * Roles ``` mermaid --- title: 所有角色说明 --- classDiagram BaseModel note for BaseModel "Pydantic 是一个用于数据验证和设置管理的 Python 库。它允许你使用 Python 类型注释来定义数据模型,并自动验证和转换输入数据.BaseModel是其中的一个模块。\nclass User(BaseModel): id: int name: str age: Optional[int] = None friends: List[str] = [] # 创建一个用户对象 try: user = User(id=1, name='John Doe', age=25, friends=['Alice', 'Bob']) print(user) except ValidationError as e: print(e) # 无效数据示例 try: invalid_user = User(id='abc', name='John Doe', age='twenty-five', friends=['Alice', 'Bob']) except ValidationError as e: print(e)" BaseModel<|.. Role note for Role "Role/Agent base class. 定义了一个prompt模板用来针对不同角色的action进行交互" Role<|-- Architect Role<|-- Assistant Sales<|-- CustomerService Role<|-- Engineer Role<|-- InvoiceOCRAssistant Role<|-- ProductManager Role<|-- ProjectManager Role<|-- QaEngineer Role<|-- Sales Role<|-- Searcher Role<|-- SkAgent Role<|-- Teacher Role<|-- TutorialAssistant note for TutorialAssistant "Tutorial assistant, input one sentence to generate a tutorial document in markup format" Role *-- Action Role *-- RoleContext note for RoleContext "Role Runtime Context" Action <|-- UserRequirement Action <|-- DebugError Action <|-- DesignReview Action <|-- WriteDesign Action <|-- ExecuteTask Action <|-- FixBug Action <|-- GenerateQuestions Action <|-- InvoiceOCR Action <|-- PrepareDocuments Action <|-- PrepareInterview Action <|-- WriteTasks Action <|-- RebuildClassView Action <|-- RebuildSequenceView Action <|-- CollectLinks Action <|-- WebBrowseAndSummarize Action <|-- ConductResearch Action <|-- RunCode Action <|-- SearchAndSummarize Action <|-- ArgumentsParingAction Action <|-- SkillAction Action <|-- SummarizeCode Action <|-- TalkAction Action <|-- WriteCodeAN Action <|-- WriteCodePlanAndChange Action <|-- WriteCodeReview Action <|-- WriteCode Action <|-- WriteDocstring Action <|-- WritePRDReview Action <|-- WritePRD Action <|-- WriteReview Action <|-- WriteTeachingPlanPart Action <|-- WriteTest Action <|-- WriteDirectory Action <|-- WriteContent ActionGraph ActionNode class Role { } class Architect { } class ActionGraph { ActionGraph: a directed graph to represent the dependency between actions. +add_node() +add_edge(from_node: ActionNode, to_node: ActionNode) +topological_sort() } class ActionNode { } ```   # # Annexe * [metagpt github](https://github.com/geekan/MetaGPT) * [LLM发展介绍](https://www.bilibili.com/video/BV1Ru411V7XL/?spm_id_from=333.788.recommend_more_video.0&vd_source=c551ef751ac5907298e9c711d193f9cd) * [大模型性能](https://artificialanalysis.ai/)
dingfeng
2024年7月15日 17:28
2826
0 条评论
转发文档
收藏文档
上一篇
下一篇
评论
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码