Public Docs
【模型量化】深度学习模型量化 & 量化理论 & 各平台的量化过程 & 硬件加速
【TVM】TI关于TVM的使用测试与分析
【LLM&LVM】大模型开源工程思维导图
SmartSip
【北航卓越工程师】《汽车前沿技术导论:智能驾驶》讲义
【工具链】Yocto使用介绍——使用Yocto创建一个树莓派的系统镜像
【工具链】使用ssh+dialog指令设定服务器指定用户仅容器访问
【推理引擎】一篇关于模型推理的详细对比与学习
【推理引擎】关于TVM中的Schedule优化详解(On going)
【LLM微调】使用litgpt进行私有数据集模型微调的测试总结
【TVM】在TVM Relay中创建一个自定义操作符
【STT+LLM+TTS】如何使用语音转文字模型+大预言模型+语音生成模型完成一个类人的语音交互机器人
【RAG】 通过RAG构建垂直领域的LLM Agent的方法探索
【RAG】GraphRAG精读与测试(On going)
【AI Agent】MetaGPT精读与学习
【AI Base】Ilya Sutskever 27篇必读论文分享清单
【Nvidia】Jetson AGX Orin/ Jetson Orin nano 硬件测试调试内容(On going)
【BI/DI】LLM Using in BI Testing Scenario (On going)
【Nvidia】How to Activate a Camera on Nvidia Platform in Details
【RAS-PI】树莓派驱动开发
【行业咨询阅读】关注实时咨询和分析
【mobileye】2024 Driving AI
【mobileye】SDS_Safety_Architecture
【yolo】yolov8测试
【nvidia】Triton server实践
【alibaba】MNN(on updating)
【OpenAI】Triton(on updating)
【CAIS】关于Compound AI Systems的思考
【Nvidia】关于Cuda+Cudnn+TensorRT推理环境
【BEV】BEVDet在各个平台上的执行效率及优化(On Updating)
【Chip】AI在芯片设计和电路设计中的应用
【Chip】ChiPFormer
【Chip】关于布线的学习
【Chip】MaskPlace论文精读与工程复现优化
【gynasium】强化学习初体验
【Cadence】X AI
【transformer】MinGPT开源工程学习
【中间件】针对apollo 10.0中关于cyberRT性能优化的深度解读和思考
【Robotics】调研了解当前机器人开发者套件(on updating)
【Robotics】ROS CON China 2024 文档技术整理与感想总结(上2024.12.7,中2024.12.8,下场外产品)
【algorithm】关于模型、数据与标注规范的平衡问题
【nvidia】DLA的学习了解与使用
【nvidia】构建nvidia嵌入式平台的交叉编译环境(其他环境平台可借鉴)
【2025AI生成式大会】2025大会个人总结
【Robotics】 Create Quadruped Robot RL FootStep Training Environment In IsaacLab
【Robotics】如何一个人较为完整的完成一个机器人系统软件算法层面的设计与开发
【VLM】读懂多模态大模型评价指标
【VLM】大模型部署的端侧部署性能与精度评估方法与分析
【Nvidia】Jetson Orin 平台VLM部署方法与指标评测
【Database】向量数据库
【SoC】性能与功耗评估
【MCP】MCP探索
【InnoFrance】一个“关于声音”的有趣项目
【Robotics】写给那些想要快速了解机器人或者具身智能的工程师们
【Robotics】open X Embodiment RT-X 数据集下载与使用和分析
文档发布于【Feng's Docs】
-
+
首页
【VLM】大模型部署的端侧部署性能与精度评估方法与分析
# pre 本章节详细介绍大模型的部署与性能分析流程,并通过实例展示如何评估和优化大模型的部署性能,从性能和精度给出最终的优化结果。以sglang的部署框架部署为例。 # 测试用例 使用一张coco数据集的数据尺寸为640 * 428的rgb图片  对于输出的结果尽可能丰富,做出了200个提问进行随机提问:(提问测试代码如下) ``` import json import time import base64 from openai import OpenAI import os from concurrent.futures import ThreadPoolExecutor, as_completed # Initialize client client = OpenAI(base_url=f"http://localhost:30000/v1", api_key="None") questions = [ "请介绍一下你在图片中看到了什么?", "请识别出图片中碗的位置?", "请告诉我图中碗里装的是什么?", "请描述图片中碗的颜色和形状。", "请分析图片中碗的可能用途。", "请给出图片中碗的边界框坐标(bbox)。", "请详细描述图片中碗的纹理和材质,请详细描述,分三段,每段约100字。", "请列出图片中所有碗的数量和位置。", "请推测图片中碗的制作工艺。", "请比较图片中两个碗的异同。", "请介绍一下你在图片中看到了什么?", "请识别出图片中勺子的位置?", "请告诉我图中勺子里装的是什么?", "请描述图片中勺子的颜色和形状。", "请分析图片中勺子的可能用途。", "请给出图片中勺子的边界框坐标(bbox)。", "请详细描述图片中勺子的纹理和材质,请详细描述,分三段,每段约100字。", "请列出图片中所有勺子的数量和位置。", "请推测图片中勺子的制作工艺。", "请比较图片中两个勺子的异同。", "请介绍一下你在图片中看到了什么?", "请识别出图片中盘子的位置?", "请告诉我图中盘子里装的是什么?", "请描述图片中盘子的颜色和形状。", "请分析图片中盘子的可能用途。", "请给出图片中盘子的边界框坐标(bbox)。", "请详细描述图片中盘子的纹理和材质,使用尽可能长的文本篇幅。", "请列出图片中所有盘子的数量和位置。", "请推测图片中盘子的制作工艺。", "请比较图片中两个盘子的异同。", "请介绍一下你在图片中看到了什么?", "请识别出图片中食物的位置?", "请告诉我图中食物里装的是什么?", "请描述图片中食物的颜色和形状。", "请分析图片中食物的可能用途。", "请给出图片中食物的边界框坐标(bbox)。", "请详细描述图片中食物的纹理和材质,字数不少于300字。", "请列出图片中所有食物的数量和位置。", "请推测图片中食物的制作工艺。", "请比较图片中两个食物的异同。", "请介绍一下你在图片中看到了什么?", "请识别出图片中蔬菜的位置?", "请告诉我图中蔬菜里装的是什么?", "请描述图片中蔬菜的颜色和形状。", "请分析图片中蔬菜的可能用途。", "请给出图片中蔬菜的边界框坐标(bbox)。", "请详细描述图片中蔬菜的纹理和材质,字数不少于300字。", "请列出图片中所有蔬菜的数量和位置。", "请推测图片中蔬菜的制作工艺。", "请比较图片中两个蔬菜的异同。", "请介绍一下你在图片中看到了什么?", "请识别出图片中水果的位置?", "请告诉我图中水果里装的是什么?", "请描述图片中水果的颜色和形状。", "请分析图片中水果的可能用途。", "请给出图片中水果的边界框坐标(bbox)。", "请详细描述图片中水果的纹理和材质,字数不少于300字。", "请列出图片中所有水果的数量和位置。", "请推测图片中水果的制作工艺。", "请比较图片中两个水果的异同。", "请介绍一下你在图片中看到了什么?", "请识别出图片中餐具的位置?", "请告诉我图中餐具里装的是什么?", "请描述图片中餐具的颜色和形状。", "请分析图片中餐具的可能用途。", "请给出图片中餐具的边界框坐标(bbox)。", "请详细描述图片中餐具的纹理和材质,字数不少于300字。", "请列出图片中所有餐具的数量和位置。", "请推测图片中餐具的制作工艺。", "请比较图片中两个餐具的异同。", "请介绍一下你在图片中看到了什么?", "请识别出图片中饮料的位置?", "请告诉我图中饮料里装的是什么?", "请描述图片中饮料的颜色和形状。", "请分析图片中饮料的可能用途。", "请给出图片中饮料的边界框坐标(bbox)。", "请详细描述图片中饮料的纹理和材质,字数不少于300字。", "请列出图片中所有饮料的数量和位置。", "请推测图片中饮料的制作工艺。", "请比较图片中两个饮料的异同。", "请介绍一下你在图片中看到了什么?", "请识别出图片中桌子的位置?", "请告诉我图中桌子里装的是什么?", "请描述图片中桌子的颜色和形状。", "请分析图片中桌子的可能用途。", "请给出图片中桌子的边界框坐标(bbox)。", "请详细描述图片中桌子的纹理和材质,字数不少于300字。", "请列出图片中所有桌子的数量和位置。", "请推测图片中桌子的制作工艺。", "请比较图片中两个桌子的异同。", "请介绍一下你在图片中看到了什么?", "请识别出图片中背景物体的位置?", "请告诉我图中背景物体里装的是什么?", "请描述图片中背景物体的颜色和形状。", "请分析图片中背景物体的可能用途。", "请给出图片中背景物体的边界框坐标(bbox)。", "请详细描述图片中背景物体的纹理和材质,字数不少于300字。", "请列出图片中所有背景物体的数量和位置。", "请推测图片中背景物体的制作工艺。", "请比较图片中两个背景物体的异同。", "Please describe what you see in the image.", "Please identify the location of the bowl in the image.", "What is inside the bowl in the image?", "Describe the color and shape of the bowl in the image.", "Analyze the possible use of the bowl in the image.", "Provide the bounding box coordinates (bbox) of the bowl in the image.", "Give a detailed description of the texture and material of the bowl, with at least 300 words.", "List the quantity and positions of all bowls in the image.", "Speculate on the manufacturing process of the bowl in the image.", "Compare and contrast the two bowls in the image.", "Please describe what you see in the image.", "Please identify the location of the spoon in the image.", "What is inside the spoon in the image?", "Describe the color and shape of the spoon in the image.", "Analyze the possible use of the spoon in the image.", "Provide the bounding box coordinates (bbox) of the spoon in the image.", "Give a detailed description of the texture and material of the spoon, with at least 300 words.", "List the quantity and positions of all spoons in the image.", "Speculate on the manufacturing process of the spoon in the image.", "Compare and contrast the two spoons in the image.", "Please describe what you see in the image.", "Please identify the location of the plate in the image.", "What is inside the plate in the image?", "Describe the color and shape of the plate in the image.", "Analyze the possible use of the plate in the image.", "Provide the bounding box coordinates (bbox) of the plate in the image.", "Give a detailed description of the texture and material of the plate, with at least 300 words.", "List the quantity and positions of all plates in the image.", "Speculate on the manufacturing process of the plate in the image.", "Compare and contrast the two plates in the image.", "Please describe what you see in the image.", "Please identify the location of the food in the image.", "What is inside the food in the image?", "Describe the color and shape of the food in the image.", "Analyze the possible use of the food in the image.", "Provide the bounding box coordinates (bbox) of the food in the image.", "Give a detailed description of the texture and material of the food, with at least 300 words.", "List the quantity and positions of all food items in the image.", "Speculate on the manufacturing process of the food in the image.", "Compare and contrast the two food items in the image.", "Please describe what you see in the image.", "Please identify the location of the vegetables in the image.", "What is inside the vegetables in the image?", "Describe the color and shape of the vegetables in the image.", "Analyze the possible use of the vegetables in the image.", "Provide the bounding box coordinates (bbox) of the vegetables in the image.", "Give a detailed description of the texture and material of the vegetables, with at least 300 words.", "List the quantity and positions of all vegetables in the image.", "Speculate on the manufacturing process of the vegetables in the image.", "Compare and contrast the two vegetables in the image.", "Please describe what you see in the image.", "Please identify the location of the fruits in the image.", "What is inside the fruits in the image?", "Describe the color and shape of the fruits in the image.", "Analyze the possible use of the fruits in the image.", "Provide the bounding box coordinates (bbox) of the fruits in the image.", "Give a detailed description of the texture and material of the fruits, with at least 300 words.", "List the quantity and positions of all fruits in the image.", "Speculate on the manufacturing process of the fruits in the image.", "Compare and contrast the two fruits in the image.", "Please describe what you see in the image.", "Please identify the location of the tableware in the image.", "What is inside the tableware in the image?", "Describe the color and shape of the tableware in the image.", "Analyze the possible use of the tableware in the image.", "Provide the bounding box coordinates (bbox) of the tableware in the image.", "Give a detailed description of the texture and material of the tableware, with at least 300 words.", "List the quantity and positions of all tableware in the image.", "Speculate on the manufacturing process of the tableware in the image.", "Compare and contrast the two tableware items in the image.", "Please describe what you see in the image.", "Please identify the location of the drinks in the image.", "What is inside the drinks in the image?", "Describe the color and shape of the drinks in the image.", "Analyze the possible use of the drinks in the image.", "Provide the bounding box coordinates (bbox) of the drinks in the image.", "Give a detailed description of the texture and material of the drinks, with at least 300 words.", "List the quantity and positions of all drinks in the image.", "Speculate on the manufacturing process of the drinks in the image.", "Compare and contrast the two drinks in the image.", "Please describe what you see in the image.", "Please identify the location of the table in the image.", "What is inside the table in the image?", "Describe the color and shape of the table in the image.", "Analyze the possible use of the table in the image.", "Provide the bounding box coordinates (bbox) of the table in the image.", "Give a detailed description of the texture and material of the table, with at least 300 words.", "List the quantity and positions of all tables in the image.", "Speculate on the manufacturing process of the table in the image.", "Compare and contrast the two tables in the image.", "Please describe what you see in the image.", "Please identify the location of the background objects in the image.", "What is inside the background objects in the image?", "Describe the color and shape of the background objects in the image.", "Analyze the possible use of the background objects in the image.", "Provide the bounding box coordinates (bbox) of the background objects in the image.", "Give a detailed description of the texture and material of the background objects, with at least 300 words.", "List the quantity and positions of all background objects in the image.", "Speculate on the manufacturing process of the background objects in the image.", "Compare and contrast the two background objects in the image." ] images_path = [] img_path = "./qwen-vl-finetune/demo/images/COCO_train2014_000000580957.jpg" def encode_image_to_base64(image_path): with open(image_path, "rb") as f: return base64.b64encode(f.read()).decode("utf-8") def run_sglang_inference(i): start_time1 = time.perf_counter() content = [] if not os.path.exists(img_path): print(f"Warning: image file not found: {img_path}, skipping this image.") return img_base64 = encode_image_to_base64(img_path) content.append({ "type": "image_url", "image_url": { "url" : f"data:image/jpeg;base64,{img_base64}" } }) content.append({ "type": "text", "text": questions[i % len(questions)] }) start_time = time.perf_counter() try: response = client.chat.completions.create( model="Qwen/Qwen2.5-VL-7B-Instruct", messages=[ { "role": "user", "content": content } ], temperature=0, ) end_time = time.perf_counter() elapsed = end_time - start_time elapsed1 = start_time - start_time1 response_content = response.choices[0].message.content print(f"[{i}] Preprocess: {elapsed1:.6f}s, Inference: {elapsed:.6f}s | Response: {response_content}") except Exception as e: print(f"[{i}] Error: {e}") def continuous_ask_multithread(interval=1, total_rounds=100, max_workers=8): with ThreadPoolExecutor(max_workers=max_workers) as executor: futures = [] for i in range(total_rounds): futures.append(executor.submit(run_sglang_inference, i)) time.sleep(interval) for future in as_completed(futures): pass if __name__ == "__main__": continuous_ask_multithread(interval=1, total_rounds=10000, max_workers=4) ``` # 1 4090服务器测试 ## 1.1 性能 ### 1.1.0 pre 主要评估速度并对耗时进行精确的分析。 如果是以sglang作为推理部署框架,那整体E2E的耗时来源包含以下几个部分: 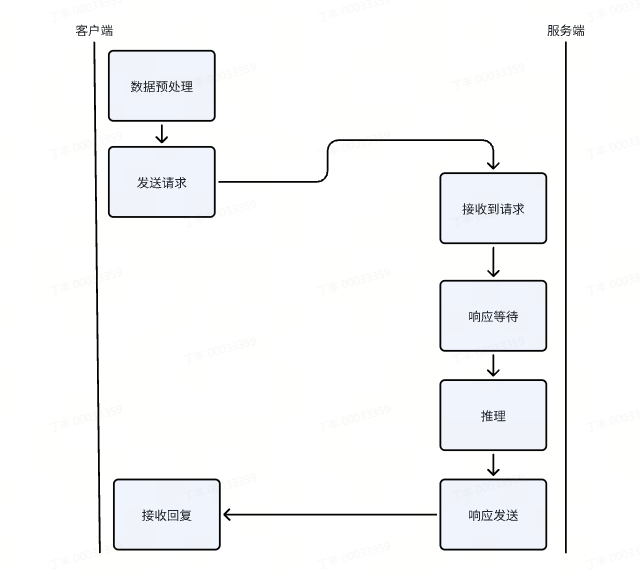 - 其中数据预处理主要和需要响应和请求的数据类型和尺寸有关,例如图像的分辨率可能需要resize或者crop,数据可能要转base64 可能要进行encoder等等; - 其次发送请求与接收请求主要与客户端调度,网络延迟等有关 - 等待响应主要与服务端的处理能力和响应事件的数量有关 - 推理主要就是体现服务端算力、模型大小以及量化位宽等相关(重点评估) - 响应发送同发送请求类似 所以可以使用如下工具进行详细的分析和统计 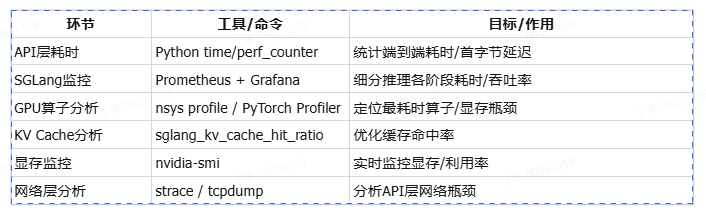 ### 1.1.1 服务端SGLANG性能统计Prometheus + Grafana SGLang服务支持Prometheus格式监控,默认可采集如下关键指标: - E2E Latency:端到端请求平均处理耗时 - TTFT(Time To First Token):首Token生成延时 - TPOT(Time Per Output Token):每个Token生成延时 - Token Throughput:Token吞吐速率 - KV Cache Hit Ratio:缓存命中率 - 显存占用:GPU资源监控 具体使用方法如下: 1. sglang服务启动时添加--enable-metrics参数 ``` python3 -m sglang.launch_server --model-path ./Qwen2.5-VL-3B-Instruct --host 0.0.0.0 --port 30000 --enable-metrics ``` 2. 安装prometheus ``` sudo apt install prometheus ``` 3. 配置prometheus scrape configs ``` vi /etc/prometheus/prometheus.yml # 增加 scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'sglang' static_configs: - targets: ['localhost:30000'] ``` 4. 请求指标 ``` curl http://10.163.176.59:30000/metrics # HELP sglang:num_running_reqs The number of running requests. # TYPE sglang:num_running_reqs gauge sglang:num_running_reqs{engine_type="unified",model_name="./Qwen2.5-VL-3B-Instruct",pp_rank="0",tp_rank="0"} 0.0 # HELP sglang:num_used_tokens The number of used tokens. # TYPE sglang:num_used_tokens gauge sglang:num_used_tokens{engine_type="unified",model_name="./Qwen2.5-VL-3B-Instruct",pp_rank="0",tp_rank="0"} 0.0 # HELP sglang:token_usage The token usage. # TYPE sglang:token_usage gauge sglang:token_usage{engine_type="unified",model_name="./Qwen2.5-VL-3B-Instruct",pp_rank="0",tp_rank="0"} 0.0 # HELP sglang:gen_throughput The generation throughput (token/s). # TYPE sglang:gen_throughput gauge sglang:gen_throughput{engine_type="unified",model_name="./Qwen2.5-VL-3B-Instruct",pp_rank="0",tp_rank="0"} 0.0 # HELP sglang:num_queue_reqs The number of requests in the waiting queue. # TYPE sglang:num_queue_reqs gauge sglang:num_queue_reqs{engine_type="unified",model_name="./Qwen2.5-VL-3B-Instruct",pp_rank="0",tp_rank="0"} 0.0 # HELP sglang:num_grammar_queue_reqs The number of requests in the grammar waiting queue. # TYPE sglang:num_grammar_queue_reqs gauge sglang:num_grammar_queue_reqs{engine_type="unified",model_name="./Qwen2.5-VL-3B-Instruct",pp_rank="0",tp_rank="0"} 0.0 # HELP sglang:cache_hit_rate The prefix cache hit rate. # TYPE sglang:cache_hit_rate gauge sglang:cache_hit_rate{engine_type="unified",model_name="./Qwen2.5-VL-3B-Instruct",pp_rank="0",tp_rank="0"} 0.0 # HELP sglang:spec_accept_length The average acceptance length of speculative decoding. # TYPE sglang:spec_accept_length gauge sglang:spec_accept_length{engine_type="unified",model_name="./Qwen2.5-VL-3B-Instruct",pp_rank="0",tp_rank="0"} 0.0 # HELP sglang:total_retracted_reqs The total number of retracted requests due to kvcache full. # TYPE sglang:total_retracted_reqs gauge sglang:total_retracted_reqs{engine_type="unified",model_name="./Qwen2.5-VL-3B-Instruct",pp_rank="0",tp_rank="0"} 0.0 # HELP sglang:num_prefill_prealloc_queue_reqs The number of requests in the prefill prealloc queue. # TYPE sglang:num_prefill_prealloc_queue_reqs gauge sglang:num_prefill_prealloc_queue_reqs{engine_type="unified",model_name="./Qwen2.5-VL-3B-Instruct",pp_rank="0",tp_rank="0"} 0.0 # HELP sglang:num_prefill_infight_queue_reqs The number of requests in the prefill infight queue. # TYPE sglang:num_prefill_infight_queue_reqs gauge sglang:num_prefill_infight_queue_reqs{engine_type="unified",model_name="./Qwen2.5-VL-3B-Instruct",pp_rank="0",tp_rank="0"} 0.0 # HELP sglang:num_decode_prealloc_queue_reqs The number of requests in the decode prealloc queue. # TYPE sglang:num_decode_prealloc_queue_reqs gauge sglang:num_decode_prealloc_queue_reqs{engine_type="unified",model_name="./Qwen2.5-VL-3B-Instruct",pp_rank="0",tp_rank="0"} 0.0 # HELP sglang:num_decode_transfer_queue_reqs The number of requests in the decode transfer queue. # TYPE sglang:num_decode_transfer_queue_reqs gauge sglang:num_decode_transfer_queue_reqs{engine_type="unified",model_name="./Qwen2.5-VL-3B-Instruct",pp_rank="0",tp_rank="0"} 0.0 # HELP sglang:prompt_tokens_total Number of prefill tokens processed. # TYPE sglang:prompt_tokens_total counter sglang:prompt_tokens_total{model_name="./Qwen2.5-VL-3B-Instruct"} 6.0 # HELP sglang:generation_tokens_total Number of generation tokens processed. # TYPE sglang:generation_tokens_total counter sglang:generation_tokens_total{model_name="./Qwen2.5-VL-3B-Instruct"} 8.0 # HELP sglang:num_requests_total Number of requests processed. # TYPE sglang:num_requests_total counter sglang:num_requests_total{model_name="./Qwen2.5-VL-3B-Instruct"} 1.0 # HELP sglang:time_to_first_token_seconds Histogram of time to first token in seconds. # TYPE sglang:time_to_first_token_seconds histogram sglang:time_to_first_token_seconds_sum{model_name="./Qwen2.5-VL-3B-Instruct"} 1.4348304271697998 sglang:time_to_first_token_seconds_bucket{le="0.1",model_name="./Qwen2.5-VL-3B-Instruct"} 0.0 sglang:time_to_first_token_seconds_bucket{le="0.2",model_name="./Qwen2.5-VL-3B-Instruct"} 0.0 sglang:time_to_first_token_seconds_bucket{le="0.4",model_name="./Qwen2.5-VL-3B-Instruct"} 0.0 sglang:time_to_first_token_seconds_bucket{le="0.6",model_name="./Qwen2.5-VL-3B-Instruct"} 0.0 sglang:time_to_first_token_seconds_bucket{le="0.8",model_name="./Qwen2.5-VL-3B-Instruct"} 0.0 sglang:time_to_first_token_seconds_bucket{le="1.0",model_name="./Qwen2.5-VL-3B-Instruct"} 0.0 sglang:time_to_first_token_seconds_bucket{le="2.0",model_name="./Qwen2.5-VL-3B-Instruct"} 1.0 sglang:time_to_first_token_seconds_bucket{le="4.0",model_name="./Qwen2.5-VL-3B-Instruct"} 1.0 sglang:time_to_first_token_seconds_bucket{le="6.0",model_name="./Qwen2.5-VL-3B-Instruct"} 1.0 sglang:time_to_first_token_seconds_bucket{le="8.0",model_name="./Qwen2.5-VL-3B-Instruct"} 1.0 sglang:time_to_first_token_seconds_bucket{le="10.0",model_name="./Qwen2.5-VL-3B-Instruct"} 1.0 sglang:time_to_first_token_seconds_bucket{le="20.0",model_name="./Qwen2.5-VL-3B-Instruct"} 1.0 sglang:time_to_first_token_seconds_bucket{le="40.0",model_name="./Qwen2.5-VL-3B-Instruct"} 1.0 sglang:time_to_first_token_seconds_bucket{le="60.0",model_name="./Qwen2.5-VL-3B-Instruct"} 1.0 sglang:time_to_first_token_seconds_bucket{le="80.0",model_name="./Qwen2.5-VL-3B-Instruct"} 1.0 sglang:time_to_first_token_seconds_bucket{le="100.0",model_name="./Qwen2.5-VL-3B-Instruct"} 1.0 sglang:time_to_first_token_seconds_bucket{le="200.0",model_name="./Qwen2.5-VL-3B-Instruct"} 1.0 sglang:time_to_first_token_seconds_bucket{le="400.0",model_name="./Qwen2.5-VL-3B-Instruct"} 1.0 sglang:time_to_first_token_seconds_bucket{le="+Inf",model_name="./Qwen2.5-VL-3B-Instruct"} 1.0 sglang:time_to_first_token_seconds_count{model_name="./Qwen2.5-VL-3B-Instruct"} 1.0 # HELP sglang:e2e_request_latency_seconds Histogram of End-to-end request latency in seconds # TYPE sglang:e2e_request_latency_seconds histogram sglang:e2e_request_latency_seconds_sum{model_name="./Qwen2.5-VL-3B-Instruct"} 1.4348244667053223 sglang:e2e_request_latency_seconds_bucket{le="0.1",model_name="./Qwen2.5-VL-3B-Instruct"} 0.0 ``` 完成以上步骤,即可证明prometheus的配置是正常的,相关参数的分析和作用如下表 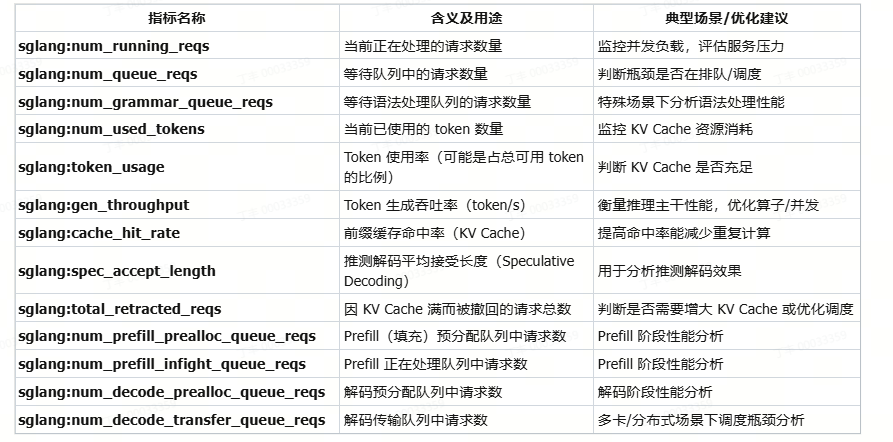 #### 1.1.1.1 Prometheus http://10.163.176.59:9090/ 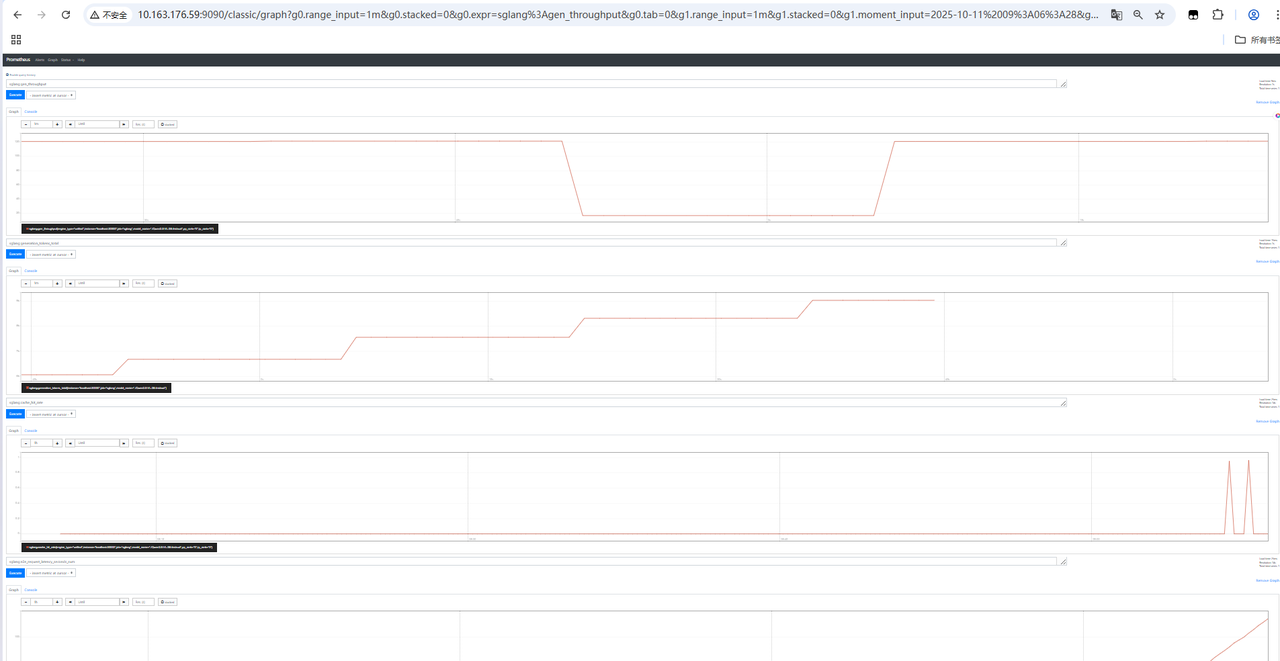 #### 1.1.1.2 Grafana 1. 安装 ``` sudo apt-get install -y apt-transport-https sudo apt-get install -y software-properties-common wget wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add - echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list sudo apt-get update sudo apt-get install grafana ``` 2. 配置 ``` sudo systemctl start grafana-server sudo systemctl enable grafana-server ``` 3. 使用 ``` 默认端口是 3000。 浏览器访问: http://localhost:3000 首次登录用户名和密码都是 admin,登录后建议修改密码。 ``` 4. 配置连接prometheus ``` 登录 Grafana 后,左侧菜单点击 “齿轮”图标(Configuration) > “Data Sources” 点击 “Add data source”,选择 Prometheus。 在 “HTTP” 部分的 “URL” 输入框填写 Prometheus 地址,通常为: http://localhost:9090 如果 Prometheus 在远程服务器,需填写实际 IP 和端口,如 http://your-server-ip:9090 点击页面底部 “Save & Test”,出现 “Data source is working” 即配置成功。 新建 Dashboard 左侧菜单点击 “+” > “Dashboard” > “Add new panel” 添加图表 在 “Query” 输入框填入如 sglang:gen_throughput 或其他你关心的指标。 可选择可视化类型(折线图、柱状图等),配置时间区间、刷新频率等。 配置好后点击 “Apply” 保存面板。 组合多个图表 重复添加多个 panel,展示不同指标(如吞吐量、缓存命中率、队列长度等)。 可以保存整个 Dashboard,方便以后直接查看。 ``` 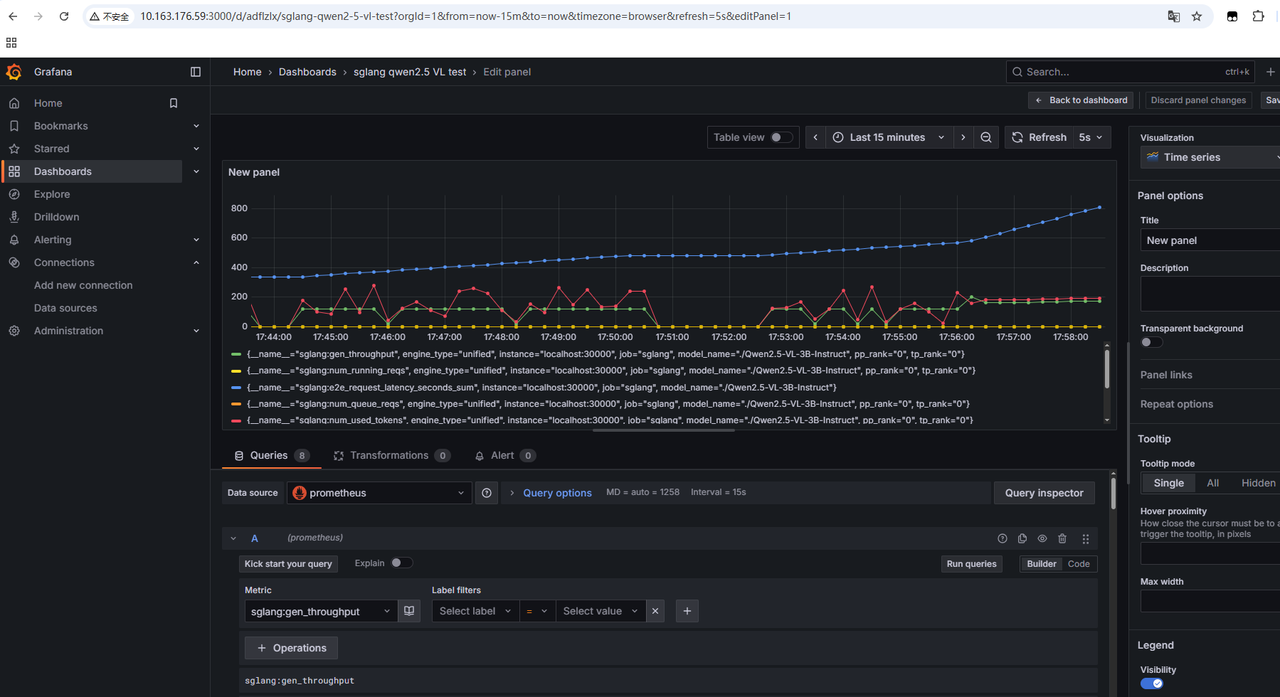 ### 1.1.2 Nsight-system 分析服务端性能 - 默认系统已经安装nsys - 查看nsys的可检查项 ``` # (sglang) root:~/Downloads$ nsys status --environment Timestamp counter supported: Yes CPU Profiling Environment Check Root privilege: disabled Linux Kernel Paranoid Level = 4 Linux Distribution = Ubuntu Linux Kernel Version = 6.8.0-84-generic: OK Linux perf_event_open syscall available: Fail Sampling trigger event available: Fail Intel(c) Last Branch Record support: Not Available CPU Profiling Environment (process-tree): Fail CPU Profiling Environment (system-wide): Fail See the product documentation at https://docs.nvidia.com/nsight-systems for more information, including information on how to set the Linux Kernel Paranoid Level. ``` 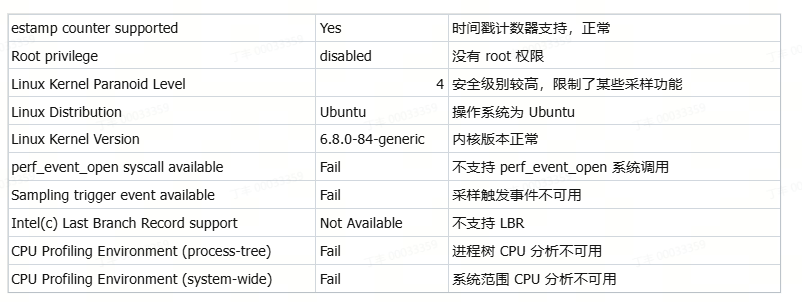 ``` # ~/Downloads$ sudo nsys status --environment Timestamp counter supported: Yes CPU Profiling Environment Check Root privilege: enabled Linux Kernel Paranoid Level = 4 Linux Distribution = Ubuntu Linux Kernel Version = 6.8.0-84-generic: OK Linux perf_event_open syscall available: OK Sampling trigger event available: OK Intel(c) Last Branch Record support: Available CPU Profiling Environment (process-tree): OK CPU Profiling Environment (system-wide): OK See the product documentation at https://docs.nvidia.com/nsight-systems for more information, including information on how to set the Linux Kernel Paranoid Level. ``` 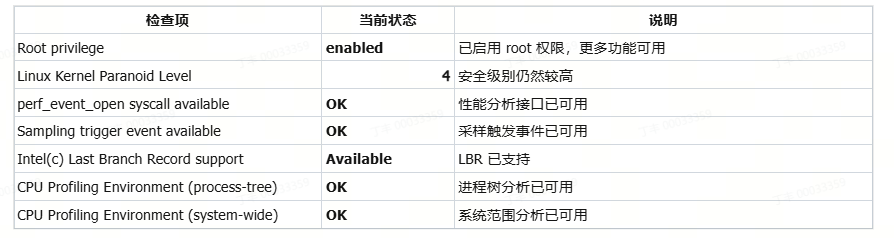 ``` 降低 Kernel Paranoid Level 方法: 临时设置(重启后失效): echo 1 | sudo tee /proc/sys/kernel/perf_event_paranoid 永久设置: 编辑 /etc/sysctl.conf,加入或修改: kernel.perf_event_paranoid = 1 执行: sudo sysctl -p ``` - 关闭metric统计,使用nsys profile指令启动sglang服务 ``` nsys profile -o sglang_profile python3 -m sglang.launch_server --model-path ./Qwen2.5-VL-3B-Instruct --host 0.0.0.0 --port 30000 ``` #### 1.1.3.1 报告分析 老版本工具为nsight-sys,新版本为nsys-ui,注意版本不匹配会导致报告无法打开 【todo】 ### 1.1.3 Evalscope evalscope是一款能够对大模型性能进行压测的工具 https://evalscope.readthedocs.io/zh-cn/latest/get_started/basic_usage.html https://github.com/modelscope/evalscope 直接看压测部分,可以针对模型也可以针对基于框架部署后的API接口 https://evalscope.readthedocs.io/zh-cn/latest/user_guides/stress_test/quick_start.html #### 1.1.3.1 安装 ``` pip install evalscope[perf] -U ``` #### 1.1.3.2 执行使用 ``` evalscope perf \ --parallel 1 10 50 100 200 \ --number 10 20 100 200 400 \ --model Qwen2.5-VL-7B-Instruct \ --url http://127.0.0.1:30000/v1/chat/completions \ --api openai \ --dataset random \ --max-tokens 1024 \ --min-tokens 1024 \ --prefix-length 0 \ --min-prompt-length 1024 \ --max-prompt-length 1024 \ --tokenizer-path /mnt/fd9ef272-d51b-4896-bfc8-9beaa52ae4a5/dingfeng1/Qwen2.5-VL-7B-Instruct/ \ --extra-args '{"ignore_eos": true}' ``` - 其他数据集:https://evalscope.readthedocs.io/zh-cn/latest/user_guides/stress_test/parameters.html#id5 #### 1.1.3.3 结果展示 ``` 2025-10-28 10:24:08 - evalscope - INFO: Save the result to: outputs/20251028_102408/Qwen2.5-VL-7B-Instruct 2025-10-28 10:24:08 - evalscope - INFO: Starting benchmark with args: 2025-10-28 10:24:08 - evalscope - INFO: { "model": "Qwen2.5-VL-7B-Instruct", "model_id": "Qwen2.5-VL-7B-Instruct", "attn_implementation": null, "api": "openai", "tokenizer_path": "/mnt/fd9ef272-d51b-4896-bfc8-9beaa52ae4a5/dingfeng1/Qwen2.5-VL-7B-Instruct/", "port": 8877, "url": "http://127.0.0.1:30000/v1/chat/completions", "headers": {}, "connect_timeout": 600, "read_timeout": 600, "api_key": null, "no_test_connection": false, "number": 10, "parallel": 1, "rate": -1, "sleep_interval": 5, "db_commit_interval": 1000, "queue_size_multiplier": 5, "in_flight_task_multiplier": 2, "log_every_n_query": 10, "debug": false, "visualizer": null, "wandb_api_key": null, "swanlab_api_key": null, "name": null, "outputs_dir": "outputs/20251028_102408/Qwen2.5-VL-7B-Instruct/parallel_1_number_10", "max_prompt_length": 1024, "min_prompt_length": 1024, "prefix_length": 0, "prompt": null, "query_template": null, "apply_chat_template": true, "image_width": 224, "image_height": 224, "image_format": "RGB", "image_num": 1, "image_patch_size": 28, "dataset": "random", "dataset_path": null, "frequency_penalty": null, "repetition_penalty": null, "logprobs": null, "max_tokens": 1024, "min_tokens": 1024, "n_choices": null, "seed": null, "stop": null, "stop_token_ids": null, "stream": true, "temperature": 0.0, "top_p": null, "top_k": null, "extra_args": { "ignore_eos": true } } 2025-10-28 10:24:25 - evalscope - INFO: Test connection successful. 2025-10-28 10:24:26 - evalscope - INFO: Save the data base to: outputs/20251028_102408/Qwen2.5-VL-7B-Instruct/parallel_1_number_10/benchmark_data.db Processing: 90%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▍ | 9/10 [02:25<00:16, 16.18s/it]2025-10-28 10:27:07 - evalscope - INFO: { "Time taken for tests (s)": 161.7876, "Number of concurrency": 1, "Total requests": 10, "Succeed requests": 10, "Failed requests": 0, "Output token throughput (tok/s)": 70.3211, "Total token throughput (tok/s)": 140.5116, "Request throughput (req/s)": 0.0687, "Average latency (s)": 16.1772, "Average time to first token (s)": 0.1196, "Average time per output token (s)": 0.0157, "Average inter-token latency (s)": 0.0171, "Average input tokens per request": 1022.1, "Average output tokens per request": 1024.0 } Processing: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [02:41<00:00, 16.19s/it] 2025-10-28 10:27:08 - evalscope - INFO: Benchmarking summary: +-----------------------------------+-----------+ | Key | Value | +===================================+===========+ | Time taken for tests (s) | 161.788 | +-----------------------------------+-----------+ | Number of concurrency | 1 | +-----------------------------------+-----------+ | Total requests | 10 | +-----------------------------------+-----------+ | Succeed requests | 10 | +-----------------------------------+-----------+ | Failed requests | 0 | +-----------------------------------+-----------+ | Output token throughput (tok/s) | 70.3211 | +-----------------------------------+-----------+ | Total token throughput (tok/s) | 140.512 | +-----------------------------------+-----------+ | Request throughput (req/s) | 0.0687 | +-----------------------------------+-----------+ | Average latency (s) | 16.1772 | +-----------------------------------+-----------+ | Average time to first token (s) | 0.1196 | +-----------------------------------+-----------+ | Average time per output token (s) | 0.0157 | +-----------------------------------+-----------+ | Average inter-token latency (s) | 0.0171 | +-----------------------------------+-----------+ | Average input tokens per request | 1022.1 | +-----------------------------------+-----------+ | Average output tokens per request | 1024 | +-----------------------------------+-----------+ 2025-10-28 10:27:08 - evalscope - INFO: Percentile results: +-------------+----------+---------+----------+-------------+--------------+---------------+----------------+---------------+ | Percentiles | TTFT (s) | ITL (s) | TPOT (s) | Latency (s) | Input tokens | Output tokens | Output (tok/s) | Total (tok/s) | +-------------+----------+---------+----------+-------------+--------------+---------------+----------------+---------------+ | 10% | 0.1141 | 0.0156 | 0.0157 | 16.1685 | 1024 | 1024 | 63.2714 | 126.4421 | | 25% | 0.1149 | 0.0157 | 0.0157 | 16.1696 | 1024 | 1024 | 63.2739 | 126.5428 | | 50% | 0.1157 | 0.0157 | 0.0157 | 16.1763 | 1024 | 1024 | 63.3074 | 126.6051 | | 66% | 0.1159 | 0.0157 | 0.0157 | 16.1798 | 1024 | 1024 | 63.3093 | 126.6148 | | 75% | 0.116 | 0.0158 | 0.0157 | 16.1836 | 1024 | 1024 | 63.3288 | 126.6185 | | 80% | 0.1234 | 0.0158 | 0.0157 | 16.1842 | 1024 | 1024 | 63.3329 | 126.6659 | | 90% | 0.1574 | 0.016 | 0.0157 | 16.1971 | 1024 | 1024 | 63.3532 | 126.7064 | | 95% | 0.1574 | 0.0314 | 0.0157 | 16.1971 | 1024 | 1024 | 63.3532 | 126.7064 | | 98% | 0.1574 | 0.0315 | 0.0157 | 16.1971 | 1024 | 1024 | 63.3532 | 126.7064 | | 99% | 0.1574 | 0.0315 | 0.0157 | 16.1971 | 1024 | 1024 | 63.3532 | 126.7064 | +-------------+----------+---------+----------+-------------+--------------+---------------+----------------+---------------+ 2025-10-28 10:27:08 - evalscope - INFO: Save the summary to: outputs/20251028_102408/Qwen2.5-VL-7B-Instruct/parallel_1_number_10 ``` ``` ╭──────────────────────────────────────────────────────────╮ │ Performance Test Summary Report │ ╰──────────────────────────────────────────────────────────╯ Basic Information: ┌───────────────────────┬──────────────────────────────────┐ │ Model │ Qwen2.5-VL-7B-Instruct │ │ Total Generated │ 747,520.0 tokens │ │ Total Test Time │ 1111.45 seconds │ │ Avg Output Rate │ 672.56 tokens/sec │ └───────────────────────┴──────────────────────────────────┘ Detailed Performance Metrics ┏━━━━━━┳━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━┓ ┃ ┃ ┃ Avg ┃ P99 ┃ Gen. ┃ Avg ┃ P99 ┃ Avg ┃ P99 ┃ Success┃ ┃Conc. ┃ RPS ┃ Lat.(s) ┃ Lat.(s) ┃ toks/s ┃ TTFT(s) ┃ TTFT(s) ┃ TPOT(s) ┃ TPOT(s) ┃ Rate┃ ┡━━━━━━╇━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━┩ │ 1 │ 0.07 │ 16.177 │ 16.197 │ 70.32 │ 0.120 │ 0.157 │ 0.016 │ 0.016 │ 100.0%│ │ 10 │ 0.53 │ 18.895 │ 18.909 │ 541.90 │ 0.614 │ 1.037 │ 0.018 │ 0.018 │ 100.0%│ │ 50 │ 0.77 │ 53.331 │ 74.445 │ 789.11 │ 30.843 │ 45.199 │ 0.022 │ 0.046 │ 100.0%│ │ 100 │ 0.77 │ 103.268 │ 202.397 │ 786.83 │ 77.063 │ 109.951 │ 0.026 │ 0.110 │ 100.0%│ │ 200 │ 0.77 │ 202.781 │ 460.487 │ 784.94 │ 171.103 │ 240.243 │ 0.031 │ 0.236 │ 100.0%│ └──────┴──────┴──────────┴──────────┴─────────┴──────────┴─────────┴──────────┴─────────┴──────────┘ Best Performance Configuration Highest RPS Concurrency 50 (0.77 req/sec) Lowest Latency Concurrency 1 (16.177 seconds) Performance Recommendations: • Optimal concurrency range is around 50 ``` ## 1.2 精度评估(使用OpenCompass项目对API部署的模型进行精度评估) OpenCompass:https://rank.opencompass.org.cn/leaderboard-multimodal VLMEvalKit:https://github.com/open-compass/VLMEvalKit ### 1.2.1 OpenCompass安装 https://opencompass.readthedocs.io/zh-cn/latest/get_started/installation.html 可以使用Opencompass对模型的部署精度进行评估。 - 优点:支持多种主流大模型(包括Qwen系列)、多任务、多指标评测,自动下载数据集,易配置。 - 适用:文本、视觉-语言模型均支持。 整体的过程非常清晰,具体安装步骤可以参见上方连接。安装分为三个步骤: - 数据集 https://opencompass.readthedocs.io/zh-cn/latest/dataset_statistics.html - 推理框架 https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/new_model.html(目前支持lmdeploy和vllm,但是OpenCompass比较容易支持新的后端框架,模型和API的扩展) - Api 完成安装后,即可开始进行评测。 ### 1.2.2 OpenCompass评测流程 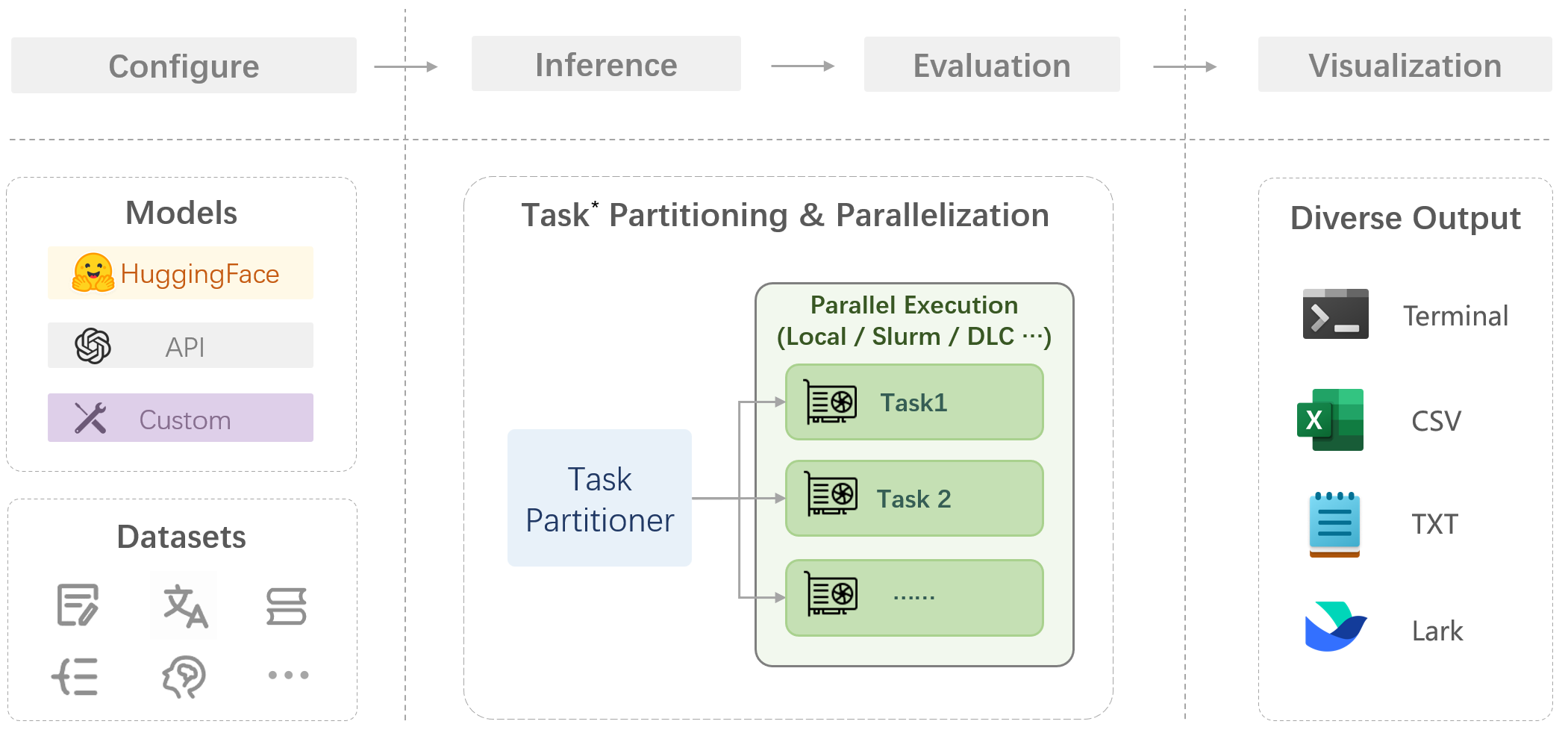 * 配置 -> 推理 -> 评估 -> 可视化 #### 1.2.3.1 配置模型 https://opencompass.readthedocs.io/zh-cn/latest/user_guides/models.html 配置模型,分成了两种方式,一种方式是直接通过评测项目预制的推理框架vllm或者lmdepoy执行推理,官方已经提供了不少样例。 另一种方式则是通过API的方式,如果使用的推理框架支持openai_api则可以直接定义使用,同时框架也支持扩展其他的API如智谱或者科大讯飞的API,因为我们使用的是SGLANG作为部署框架,而sglang默认也支持openai_api,所以直接使用API的方式更加方便。 直接在configs/models/下创建自己的模型配置,配置样例如下,如果顺利得话直接使用 tools/list_configs.py工具即可看到对应得配置。 ``` # cat opencompass/configs/models/qwen2_5/sglang_qwen2_5_vl_7b_instract.py from opencompass.models import OpenAISDK api_meta_template = dict( round=[ dict(role='HUMAN', api_role='HUMAN'), dict(role='BOT', api_role='BOT', generate=True), ], reserved_roles=[dict(role='SYSTEM', api_role='SYSTEM')], ) models = [ dict( abbr='Qwen2.5-VL-7B-Instruct-SGLang-API', type=OpenAISDK, key='EMPTY', # API key openai_api_base='http://localhost:30000/v1', # 服务地址 path='/mnt/fd9ef272-d51b-4896-bfc8-9beaa52ae4a5/dingfeng1/Qwen2.5-VL-7B-Instruct/', # 请求服务时的 model name # tokenizer_path='meta-llama/Meta-Llama-3.1-8B-Instruct', # 请求服务时的 tokenizer name 或 path, 为None时使用默认tokenizer gpt-4 rpm_verbose=True, # 是否打印请求速率 meta_template=api_meta_template, # 服务请求模板 query_per_second=1, # 服务请求速率 max_out_len=1024, # 最大输出长度 max_seq_len=128000, # 最大输入长度 temperature=0.01, # 生成温度 batch_size=1, # 批处理大小 retry=3, # 重试次数 ) ] ``` ``` # python tools/list_configs.py qwen2_5 (opencompass) hi@hi-ThinkStation-P3-Tower:~/Documents/opencompass$ python tools/list_configs.py qwen2_5 +--------------------------------+----------------------------------------------------------------------+ | Model | Config Path | |--------------------------------+----------------------------------------------------------------------| | lmdeploy_qwen2_5_3b_instruct | opencompass/configs/models/qwen2_5/lmdeploy_qwen2_5_3b_instruct.py | | lmdeploy_qwen2_5_72b | opencompass/configs/models/qwen2_5/lmdeploy_qwen2_5_72b.py | | lmdeploy_qwen2_5_72b_instruct | opencompass/configs/models/qwen2_5/lmdeploy_qwen2_5_72b_instruct.py | | lmdeploy_qwen2_5_7b | opencompass/configs/models/qwen2_5/lmdeploy_qwen2_5_7b.py | | lmdeploy_qwen2_5_7b_instruct | opencompass/configs/models/qwen2_5/lmdeploy_qwen2_5_7b_instruct.py | | sglang_qwen2_5_vl_7b_instract | opencompass/configs/models/qwen2_5/sglang_qwen2_5_vl_7b_instract.py | | vllm_qwen2_57b_a14b_instruct | opencompass/configs/models/qwen/vllm_qwen2_57b_a14b_instruct.py | | vllm_qwen2_5_0_5b_instruct | opencompass/configs/models/qwen2_5/vllm_qwen2_5_0_5b_instruct.py | | vllm_qwen2_5_14b_instruct | opencompass/configs/models/qwen2_5/vllm_qwen2_5_14b_instruct.py | +--------------------------------+----------------------------------------------------------------------+ # 同理可以查看数据集 # (opencompass) hi@hi-ThinkStation-P3-Tower:~/Documents/opencompass$ python tools/list_configs.py mmlu +-------------------------------------------------------+------------------------------------------------------------------------------------------------+ | Dataset | Config Path | |-------------------------------------------------------+------------------------------------------------------------------------------------------------| | MMLUArabic_gen | opencompass/configs/datasets/MMLUArabic/MMLUArabic_gen.py | | MMLUArabic_gen_326684 | opencompass/configs/datasets/MMLUArabic/MMLUArabic_gen_326684.py | | MMLUArabic_ppl | opencompass/configs/datasets/MMLUArabic/MMLUArabic_ppl.py | | MMLUArabic_ppl_d2333a | opencompass/configs/datasets/MMLUArabic/MMLUArabic_ppl_d2333a.py | | MMLUArabic_zero_shot_gen | opencompass/configs/datasets/MMLUArabic/MMLUArabic_zero_shot_gen.py | | MMLUArabic_zero_shot_gen_3523e0 | opencompass/configs/datasets/MMLUArabic/MMLUArabic_zero_shot_gen_3523e0.py | | cmmlu_0shot_cot_gen_305931 | opencompass/configs/datasets/cmmlu/cmmlu_0shot_cot_gen_305931.py | | cmmlu_0shot_nocot_llmjudge_gen_e1cd9a | opencompass/configs/datasets/cmmlu/cmmlu_0shot_nocot_llmjudge_gen_e1cd9a.py | | cmmlu_gen | opencompass/configs/datasets/cmmlu/cmmlu_gen.py | | cmmlu_gen_c13365 | opencompass/configs/datasets/cmmlu/cmmlu_gen_c13365.py | | cmmlu_llm_judge_gen | opencompass/configs/datasets/cmmlu/cmmlu_llm_judge_gen.py | | cmmlu_llmjudge_gen_e1cd9a | opencompass/configs/datasets/cmmlu/cmmlu_llmjudge_gen_e1cd9a.py | | cmmlu_ppl | opencompass/configs/datasets/cmmlu/cmmlu_ppl.py | | cmmlu_ppl_041cbf | opencompass/configs/datasets/cmmlu/cmmlu_ppl_041cbf.py | | cmmlu_ppl_8b9c76 | opencompass/configs/datasets/cmmlu/cmmlu_ppl_8b9c76.py | | cmmlu_stem_0shot_nocot_gen_3653db | opencompass/configs/datasets/cmmlu/cmmlu_stem_0shot_nocot_gen_3653db.py | | cmmlu_stem_0shot_nocot_llmjudge_gen_3653db | opencompass/configs/datasets/cmmlu/cmmlu_stem_0shot_nocot_llmjudge_gen_3653db.py | | cmmlu_stem_0shot_nocot_xml_gen_3653db | opencompass/configs/datasets/cmmlu/cmmlu_stem_0shot_nocot_xml_gen_3653db.py | | demo_cmmlu_base_ppl | opencompass/configs/datasets/demo/demo_cmmlu_base_ppl.py | | demo_cmmlu_chat_gen | opencompass/configs/datasets/demo/demo_cmmlu_chat_gen.py | | mmlu_all_sets | opencompass/configs/datasets/mmlu/mmlu_all_sets.py | | mmlu_cf_categories | opencompass/configs/datasets/mmlu_cf/mmlu_cf_categories.py | | mmlu_cf_few_shot | opencompass/configs/datasets/mmlu_cf/mmlu_cf_few_shot.py | | mmlu_cf_gen | opencompass/configs/datasets/mmlu_cf/mmlu_cf_gen.py | | mmlu_cf_gen_040615 | opencompass/configs/datasets/mmlu_cf/mmlu_cf_gen_040615.py | | mmlu_cf_zero_shot | opencompass/configs/datasets/mmlu_cf/mmlu_cf_zero_shot.py | | mmlu_clean_ppl | opencompass/configs/datasets/mmlu/mmlu_clean_ppl.py | | mmlu_contamination_ppl_810ec6 | opencompass/configs/datasets/contamination/mmlu_contamination_ppl_810ec6.py | | mmlu_gen | opencompass/configs/datasets/mmlu/mmlu_gen.py | | mmlu_gen_23a9a9 | opencompass/configs/datasets/mmlu/mmlu_gen_23a9a9.py | | mmlu_gen_4d595a | opencompass/configs/datasets/mmlu/mmlu_gen_4d595a.py | | mmlu_gen_5d1409 | opencompass/configs/datasets/mmlu/mmlu_gen_5d1409.py | | mmlu_gen_79e572 | opencompass/configs/datasets/mmlu/mmlu_gen_79e572.py | | mmlu_gen_a484b3 | opencompass/configs/datasets/mmlu/mmlu_gen_a484b3.py | | mmlu_llm_judge_gen | opencompass/configs/datasets/mmlu/mmlu_llm_judge_gen.py | | mmlu_llmjudge_gen_f4336b | opencompass/configs/datasets/mmlu/mmlu_llmjudge_gen_f4336b.py | | mmlu_model_postprocess_gen_4d595a | opencompass/configs/datasets/mmlu/mmlu_model_postprocess_gen_4d595a.py | | mmlu_openai_0shot_nocot_llmjudge_gen_216503 | opencompass/configs/datasets/mmlu/mmlu_openai_0shot_nocot_llmjudge_gen_216503.py | | mmlu_openai_simple_evals_gen_b618ea | opencompass/configs/datasets/mmlu/mmlu_openai_simple_evals_gen_b618ea.py | | mmlu_ppl | opencompass/configs/datasets/mmlu/mmlu_ppl.py | | mmlu_ppl_ac766d | opencompass/configs/datasets/mmlu/mmlu_ppl_ac766d.py | | mmlu_pro_0shot_cot_gen_08c1de | opencompass/configs/datasets/mmlu_pro/mmlu_pro_0shot_cot_gen_08c1de.py | | mmlu_pro_0shot_nocot_genericllmeval_gen_08c1de | opencompass/configs/datasets/mmlu_pro/mmlu_pro_0shot_nocot_genericllmeval_gen_08c1de.py | | mmlu_pro_biomed_0shot_cot_gen_057927 | opencompass/configs/datasets/mmlu_pro/mmlu_pro_biomed_0shot_cot_gen_057927.py | | mmlu_pro_biomed_0shot_nocot_genericllmeval_gen_057927 | opencompass/configs/datasets/mmlu_pro/mmlu_pro_biomed_0shot_nocot_genericllmeval_gen_057927.py | | mmlu_pro_categories | opencompass/configs/datasets/mmlu_pro/mmlu_pro_categories.py | | mmlu_pro_few_shot_gen_bfaf90 | opencompass/configs/datasets/mmlu_pro/mmlu_pro_few_shot_gen_bfaf90.py | | mmlu_pro_gen | opencompass/configs/datasets/mmlu_pro/mmlu_pro_gen.py | | mmlu_pro_gen_cdbebf | opencompass/configs/datasets/mmlu_pro/mmlu_pro_gen_cdbebf.py | | mmlu_pro_llm_judge_gen | opencompass/configs/datasets/mmlu_pro/mmlu_pro_llm_judge_gen.py | | mmlu_stem_0shot_cascade_eval_gen_216503 | opencompass/configs/datasets/mmlu/mmlu_stem_0shot_cascade_eval_gen_216503.py | | mmlu_stem_0shot_gen_216503 | opencompass/configs/datasets/mmlu/mmlu_stem_0shot_gen_216503.py | | mmlu_stem_0shot_xml_gen_216503 | opencompass/configs/datasets/mmlu/mmlu_stem_0shot_xml_gen_216503.py | | mmlu_stem_sets | opencompass/configs/datasets/mmlu/mmlu_stem_sets.py | | mmlu_xfinder_gen_4d595a | opencompass/configs/datasets/mmlu/mmlu_xfinder_gen_4d595a.py | | mmlu_zero_shot_gen_47e2c0 | opencompass/configs/datasets/mmlu/mmlu_zero_shot_gen_47e2c0.py | | mmmlu_5_shot_gen_bcbeb3 | opencompass/configs/datasets/mmmlu/mmmlu_5_shot_gen_bcbeb3.py | | mmmlu_gen | opencompass/configs/datasets/mmmlu/mmmlu_gen.py | | mmmlu_gen | opencompass/configs/datasets/PMMEval/mmmlu_gen.py | | mmmlu_gen_c51a84 | opencompass/configs/datasets/mmmlu/mmmlu_gen_c51a84.py | | mmmlu_gen_d5017d | opencompass/configs/datasets/PMMEval/mmmlu_gen_d5017d.py | | mmmlu_lite_gen | opencompass/configs/datasets/mmmlu_lite/mmmlu_lite_gen.py | | mmmlu_lite_gen_c51a84 | opencompass/configs/datasets/mmmlu_lite/mmmlu_lite_gen_c51a84.py | | mmmlu_prompt | opencompass/configs/datasets/mmmlu/mmmlu_prompt.py | +-------------------------------------------------------+------------------------------------------------------------------------------------------------+ ``` #### 1.2.3.2 配置数据集 https://opencompass.readthedocs.io/zh-cn/latest/user_guides/datasets.html 直接执行已经存在的数据集得话,数据会放在~/.cache/opencompass/data/中,离线下载的数据集可以直接在~/.cache/opencompass 中解压,也可以通过修改环境变量的方式配置离线数据集。 #### 1.2.3.3 执行推理 以上过程完成后,根据数据集和模型的提示则可以执行评测推理,因为是API调用,可以根据服务端打印信息或者日志查看到已经正常执行,也可以根据1.1.1章节中的统计接口查看执行效率。 ``` python run.py --datasets mmmlu_lite_gen_c51a84 --models sglang_qwen2_5_vl_7b_instract ``` #### 1.2.3.4 评估结果与可视化 使用sglang评测qwen2.5-vl-7B,使用mmlu的数据评测4小时的结果如下 ``` Map: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 3360.28 examples/s] Map: 100%| 10/23 04:39:40 - OpenCompass - INFO - Running 0-th replica of evaluation 10/23 04:39:40 - OpenCompass - INFO - Details is not give by evaluator, try to format it dataset version metric mode Qwen2.5-VL-7B-Instruct-SGLang-API ------------------------------------------------- --------- -------- ------ ----------------------------------- lukaemon_mmlu_college_biology bf6b83 accuracy gen 79.17 lukaemon_mmlu_college_chemistry bf6b83 accuracy gen 50.00 lukaemon_mmlu_college_computer_science bf6b83 accuracy gen 58.00 lukaemon_mmlu_college_mathematics bf6b83 accuracy gen 43.00 lukaemon_mmlu_college_physics bf6b83 accuracy gen 63.73 lukaemon_mmlu_electrical_engineering bf6b83 accuracy gen 68.97 lukaemon_mmlu_astronomy bf6b83 accuracy gen 73.68 lukaemon_mmlu_anatomy bf6b83 accuracy gen 62.96 lukaemon_mmlu_abstract_algebra bf6b83 accuracy gen 59.00 lukaemon_mmlu_machine_learning bf6b83 accuracy gen 54.46 lukaemon_mmlu_clinical_knowledge bf6b83 accuracy gen 78.11 lukaemon_mmlu_global_facts bf6b83 accuracy gen 46.00 lukaemon_mmlu_management bf6b83 accuracy gen 81.55 lukaemon_mmlu_nutrition bf6b83 accuracy gen 74.18 lukaemon_mmlu_marketing bf6b83 accuracy gen 88.46 lukaemon_mmlu_professional_accounting bf6b83 accuracy gen 52.48 lukaemon_mmlu_high_school_geography bf6b83 accuracy gen 81.31 lukaemon_mmlu_international_law bf6b83 accuracy gen 77.69 lukaemon_mmlu_moral_scenarios bf6b83 accuracy gen 41.68 lukaemon_mmlu_computer_security bf6b83 accuracy gen 70.00 lukaemon_mmlu_high_school_microeconomics bf6b83 accuracy gen 83.61 lukaemon_mmlu_professional_law bf6b83 accuracy gen 44.33 lukaemon_mmlu_medical_genetics bf6b83 accuracy gen 82.00 lukaemon_mmlu_professional_psychology bf6b83 accuracy gen 66.50 lukaemon_mmlu_jurisprudence bf6b83 accuracy gen 71.30 lukaemon_mmlu_world_religions bf6b83 accuracy gen 78.95 lukaemon_mmlu_philosophy bf6b83 accuracy gen 69.13 lukaemon_mmlu_virology bf6b83 accuracy gen 50.00 lukaemon_mmlu_high_school_chemistry bf6b83 accuracy gen 69.46 lukaemon_mmlu_public_relations bf6b83 accuracy gen 61.82 lukaemon_mmlu_high_school_macroeconomics bf6b83 accuracy gen 73.85 lukaemon_mmlu_human_sexuality bf6b83 accuracy gen 76.34 lukaemon_mmlu_elementary_mathematics bf6b83 accuracy gen 91.01 lukaemon_mmlu_high_school_physics bf6b83 accuracy gen 65.56 lukaemon_mmlu_high_school_computer_science bf6b83 accuracy gen 89.00 lukaemon_mmlu_high_school_european_history bf6b83 accuracy gen 72.12 lukaemon_mmlu_business_ethics bf6b83 accuracy gen 66.00 lukaemon_mmlu_moral_disputes bf6b83 accuracy gen 66.47 lukaemon_mmlu_high_school_statistics bf6b83 accuracy gen 71.30 lukaemon_mmlu_miscellaneous bf6b83 accuracy gen 85.44 lukaemon_mmlu_formal_logic bf6b83 accuracy gen 50.00 lukaemon_mmlu_high_school_government_and_politics bf6b83 accuracy gen 89.64 lukaemon_mmlu_prehistory bf6b83 accuracy gen 73.46 lukaemon_mmlu_security_studies bf6b83 accuracy gen 65.71 lukaemon_mmlu_high_school_biology bf6b83 accuracy gen 83.87 lukaemon_mmlu_logical_fallacies bf6b83 accuracy gen 75.46 lukaemon_mmlu_high_school_world_history bf6b83 accuracy gen 74.68 lukaemon_mmlu_professional_medicine bf6b83 accuracy gen 73.90 lukaemon_mmlu_high_school_mathematics bf6b83 accuracy gen 58.52 lukaemon_mmlu_college_medicine bf6b83 accuracy gen 69.94 lukaemon_mmlu_high_school_us_history bf6b83 accuracy gen 75.98 lukaemon_mmlu_sociology bf6b83 accuracy gen 78.11 lukaemon_mmlu_econometrics bf6b83 accuracy gen 53.51 lukaemon_mmlu_high_school_psychology bf6b83 accuracy gen 87.16 lukaemon_mmlu_human_aging bf6b83 accuracy gen 69.96 lukaemon_mmlu_us_foreign_policy bf6b83 accuracy gen 81.00 lukaemon_mmlu_conceptual_physics bf6b83 accuracy gen 78.72 10/23 04:39:40 - OpenCompass - INFO - write summary to /home/hi/Documents/opencompass/outputs/demo/20251022_193952/summary/summary_20251022_193952.txt 10/23 04:39:40 - OpenCompass - INFO - write csv to /home/hi/Documents/opencompass/outputs/demo/20251022_193952/summary/summary_20251022_193952.csv The markdown format results is as below: | dataset | version | metric | mode | Qwen2.5-VL-7B-Instruct-SGLang-API | |----- | ----- | ----- | ----- | -----| | lukaemon_mmlu_college_biology | bf6b83 | accuracy | gen | 79.17 | | lukaemon_mmlu_college_chemistry | bf6b83 | accuracy | gen | 50.00 | | lukaemon_mmlu_college_computer_science | bf6b83 | accuracy | gen | 58.00 | | lukaemon_mmlu_college_mathematics | bf6b83 | accuracy | gen | 43.00 | | lukaemon_mmlu_college_physics | bf6b83 | accuracy | gen | 63.73 | | lukaemon_mmlu_electrical_engineering | bf6b83 | accuracy | gen | 68.97 | | lukaemon_mmlu_astronomy | bf6b83 | accuracy | gen | 73.68 | | lukaemon_mmlu_anatomy | bf6b83 | accuracy | gen | 62.96 | | lukaemon_mmlu_abstract_algebra | bf6b83 | accuracy | gen | 59.00 | | lukaemon_mmlu_machine_learning | bf6b83 | accuracy | gen | 54.46 | | lukaemon_mmlu_clinical_knowledge | bf6b83 | accuracy | gen | 78.11 | | lukaemon_mmlu_global_facts | bf6b83 | accuracy | gen | 46.00 | | lukaemon_mmlu_management | bf6b83 | accuracy | gen | 81.55 | | lukaemon_mmlu_nutrition | bf6b83 | accuracy | gen | 74.18 | | lukaemon_mmlu_marketing | bf6b83 | accuracy | gen | 88.46 | | lukaemon_mmlu_professional_accounting | bf6b83 | accuracy | gen | 52.48 | | lukaemon_mmlu_high_school_geography | bf6b83 | accuracy | gen | 81.31 | | lukaemon_mmlu_international_law | bf6b83 | accuracy | gen | 77.69 | | lukaemon_mmlu_moral_scenarios | bf6b83 | accuracy | gen | 41.68 | | lukaemon_mmlu_computer_security | bf6b83 | accuracy | gen | 70.00 | | lukaemon_mmlu_high_school_microeconomics | bf6b83 | accuracy | gen | 83.61 | | lukaemon_mmlu_professional_law | bf6b83 | accuracy | gen | 44.33 | | lukaemon_mmlu_medical_genetics | bf6b83 | accuracy | gen | 82.00 | | lukaemon_mmlu_professional_psychology | bf6b83 | accuracy | gen | 66.50 | | lukaemon_mmlu_jurisprudence | bf6b83 | accuracy | gen | 71.30 | | lukaemon_mmlu_world_religions | bf6b83 | accuracy | gen | 78.95 | | lukaemon_mmlu_philosophy | bf6b83 | accuracy | gen | 69.13 | | lukaemon_mmlu_virology | bf6b83 | accuracy | gen | 50.00 | | lukaemon_mmlu_high_school_chemistry | bf6b83 | accuracy | gen | 69.46 | | lukaemon_mmlu_public_relations | bf6b83 | accuracy | gen | 61.82 | | lukaemon_mmlu_high_school_macroeconomics | bf6b83 | accuracy | gen | 73.85 | | lukaemon_mmlu_human_sexuality | bf6b83 | accuracy | gen | 76.34 | | lukaemon_mmlu_elementary_mathematics | bf6b83 | accuracy | gen | 91.01 | | lukaemon_mmlu_high_school_physics | bf6b83 | accuracy | gen | 65.56 | | lukaemon_mmlu_high_school_computer_science | bf6b83 | accuracy | gen | 89.00 | | lukaemon_mmlu_high_school_european_history | bf6b83 | accuracy | gen | 72.12 | | lukaemon_mmlu_business_ethics | bf6b83 | accuracy | gen | 66.00 | | lukaemon_mmlu_moral_disputes | bf6b83 | accuracy | gen | 66.47 | | lukaemon_mmlu_high_school_statistics | bf6b83 | accuracy | gen | 71.30 | | lukaemon_mmlu_miscellaneous | bf6b83 | accuracy | gen | 85.44 | | lukaemon_mmlu_formal_logic | bf6b83 | accuracy | gen | 50.00 | | lukaemon_mmlu_high_school_government_and_politics | bf6b83 | accuracy | gen | 89.64 | | lukaemon_mmlu_prehistory | bf6b83 | accuracy | gen | 73.46 | | lukaemon_mmlu_security_studies | bf6b83 | accuracy | gen | 65.71 | | lukaemon_mmlu_high_school_biology | bf6b83 | accuracy | gen | 83.87 | | lukaemon_mmlu_logical_fallacies | bf6b83 | accuracy | gen | 75.46 | | lukaemon_mmlu_high_school_world_history | bf6b83 | accuracy | gen | 74.68 | | lukaemon_mmlu_professional_medicine | bf6b83 | accuracy | gen | 73.90 | | lukaemon_mmlu_high_school_mathematics | bf6b83 | accuracy | gen | 58.52 | | lukaemon_mmlu_college_medicine | bf6b83 | accuracy | gen | 69.94 | | lukaemon_mmlu_high_school_us_history | bf6b83 | accuracy | gen | 75.98 | | lukaemon_mmlu_sociology | bf6b83 | accuracy | gen | 78.11 | | lukaemon_mmlu_econometrics | bf6b83 | accuracy | gen | 53.51 | | lukaemon_mmlu_high_school_psychology | bf6b83 | accuracy | gen | 87.16 | | lukaemon_mmlu_human_aging | bf6b83 | accuracy | gen | 69.96 | | lukaemon_mmlu_us_foreign_policy | bf6b83 | accuracy | gen | 81.00 | | lukaemon_mmlu_conceptual_physics | bf6b83 | accuracy | gen | 78.72 | 10/23 04:39:40 - OpenCompass - INFO - write markdown summary to /home/hi/Documents/opencompass/outputs/demo/20251022_193952/summary/summary_20251022_193952.md (opencompass) hi@hi-ThinkStation-P3-Tower:~/Documents/opencompass$ ``` ``` markdown | dataset | version | metric | mode | Qwen2.5-VL-7B-Instruct-SGLang-API | |----- | ----- | ----- | ----- | -----| | lukaemon_mmlu_college_biology | bf6b83 | accuracy | gen | 79.17 | | lukaemon_mmlu_college_chemistry | bf6b83 | accuracy | gen | 50.00 | | lukaemon_mmlu_college_computer_science | bf6b83 | accuracy | gen | 58.00 | | lukaemon_mmlu_college_mathematics | bf6b83 | accuracy | gen | 43.00 | | lukaemon_mmlu_college_physics | bf6b83 | accuracy | gen | 63.73 | | lukaemon_mmlu_electrical_engineering | bf6b83 | accuracy | gen | 68.97 | | lukaemon_mmlu_astronomy | bf6b83 | accuracy | gen | 73.68 | | lukaemon_mmlu_anatomy | bf6b83 | accuracy | gen | 62.96 | | lukaemon_mmlu_abstract_algebra | bf6b83 | accuracy | gen | 59.00 | | lukaemon_mmlu_machine_learning | bf6b83 | accuracy | gen | 54.46 | | lukaemon_mmlu_clinical_knowledge | bf6b83 | accuracy | gen | 78.11 | | lukaemon_mmlu_global_facts | bf6b83 | accuracy | gen | 46.00 | | lukaemon_mmlu_management | bf6b83 | accuracy | gen | 81.55 | | lukaemon_mmlu_nutrition | bf6b83 | accuracy | gen | 74.18 | | lukaemon_mmlu_marketing | bf6b83 | accuracy | gen | 88.46 | | lukaemon_mmlu_professional_accounting | bf6b83 | accuracy | gen | 52.48 | | lukaemon_mmlu_high_school_geography | bf6b83 | accuracy | gen | 81.31 | | lukaemon_mmlu_international_law | bf6b83 | accuracy | gen | 77.69 | | lukaemon_mmlu_moral_scenarios | bf6b83 | accuracy | gen | 41.68 | | lukaemon_mmlu_computer_security | bf6b83 | accuracy | gen | 70.00 | | lukaemon_mmlu_high_school_microeconomics | bf6b83 | accuracy | gen | 83.61 | | lukaemon_mmlu_professional_law | bf6b83 | accuracy | gen | 44.33 | | lukaemon_mmlu_medical_genetics | bf6b83 | accuracy | gen | 82.00 | | lukaemon_mmlu_professional_psychology | bf6b83 | accuracy | gen | 66.50 | | lukaemon_mmlu_jurisprudence | bf6b83 | accuracy | gen | 71.30 | | lukaemon_mmlu_world_religions | bf6b83 | accuracy | gen | 78.95 | | lukaemon_mmlu_philosophy | bf6b83 | accuracy | gen | 69.13 | | lukaemon_mmlu_virology | bf6b83 | accuracy | gen | 50.00 | | lukaemon_mmlu_high_school_chemistry | bf6b83 | accuracy | gen | 69.46 | | lukaemon_mmlu_public_relations | bf6b83 | accuracy | gen | 61.82 | | lukaemon_mmlu_high_school_macroeconomics | bf6b83 | accuracy | gen | 73.85 | | lukaemon_mmlu_human_sexuality | bf6b83 | accuracy | gen | 76.34 | | lukaemon_mmlu_elementary_mathematics | bf6b83 | accuracy | gen | 91.01 | | lukaemon_mmlu_high_school_physics | bf6b83 | accuracy | gen | 65.56 | | lukaemon_mmlu_high_school_computer_science | bf6b83 | accuracy | gen | 89.00 | | lukaemon_mmlu_high_school_european_history | bf6b83 | accuracy | gen | 72.12 | | lukaemon_mmlu_business_ethics | bf6b83 | accuracy | gen | 66.00 | | lukaemon_mmlu_moral_disputes | bf6b83 | accuracy | gen | 66.47 | | lukaemon_mmlu_high_school_statistics | bf6b83 | accuracy | gen | 71.30 | | lukaemon_mmlu_miscellaneous | bf6b83 | accuracy | gen | 85.44 | | lukaemon_mmlu_formal_logic | bf6b83 | accuracy | gen | 50.00 | | lukaemon_mmlu_high_school_government_and_politics | bf6b83 | accuracy | gen | 89.64 | | lukaemon_mmlu_prehistory | bf6b83 | accuracy | gen | 73.46 | | lukaemon_mmlu_security_studies | bf6b83 | accuracy | gen | 65.71 | | lukaemon_mmlu_high_school_biology | bf6b83 | accuracy | gen | 83.87 | | lukaemon_mmlu_logical_fallacies | bf6b83 | accuracy | gen | 75.46 | | lukaemon_mmlu_high_school_world_history | bf6b83 | accuracy | gen | 74.68 | | lukaemon_mmlu_professional_medicine | bf6b83 | accuracy | gen | 73.90 | | lukaemon_mmlu_high_school_mathematics | bf6b83 | accuracy | gen | 58.52 | | lukaemon_mmlu_college_medicine | bf6b83 | accuracy | gen | 69.94 | | lukaemon_mmlu_high_school_us_history | bf6b83 | accuracy | gen | 75.98 | | lukaemon_mmlu_sociology | bf6b83 | accuracy | gen | 78.11 | | lukaemon_mmlu_econometrics | bf6b83 | accuracy | gen | 53.51 | | lukaemon_mmlu_high_school_psychology | bf6b83 | accuracy | gen | 87.16 | | lukaemon_mmlu_human_aging | bf6b83 | accuracy | gen | 69.96 | | lukaemon_mmlu_us_foreign_policy | bf6b83 | accuracy | gen | 81.00 | | lukaemon_mmlu_conceptual_physics | bf6b83 | accuracy | gen | 78.72 | ``` ### 1.2.3 VLMEvalKit 安装 如果是评测多模态模型可以使用VLMEvalKit https://github.com/open-compass/VLMEvalKit/blob/main/docs/en/Quickstart.md#step-0-installation--setup-essential-keys ``` git clone https://github.com/open-compass/VLMEvalKit.git cd VLMEvalKit pip install -e . ``` ### 1.2.4 VLMEvalKit 评测流程 ``` python run.py --help # 查看帮助页面 ``` VLMEvalKit可以通过--config输入配置文件或者是 --data --model参数进行评测 可以通过如下指令进行查看当前支持的数据集和模型,如果新创建了数据集和模型,也可以通过如下指令查看是否成功。 ``` vlmutil dlist all # 查看所有数据 vlmutil mlist all # 查看所有模型 ``` #### 1.2.4.1 配置数据 ``` vlmeval/dataset/ # 在该目录下进行数据创建 ``` #### 1.2.4.2 配置模型 ``` cat vlmeval/config.py # 查看注册的模型,其中包括了API调用的模型和直接启动模型的配置结构 ``` 以我们当前使用sglang部署模型为例,使用API调用模型。其他例子中有直接配置模型的例子 ``` "Qwen2.5VL7BSglang": partial( LMDeployAPI, # 直接置空 model="/mnt/fd9ef272-d51b-4896-bfc8-9beaa52ae4a5/dingfeng1/Qwen2.5-VL-7B-Instruct/", # 调用模型的名字 本地API为非必须 api_base="http://localhost:30000/v1/chat/completions", # 调用模型的api链接 temperature=0, # 温度 retry=10, # 重复次数,optional # timeout, optional ), ``` #### 1.2.4.3 执行评测 如果想要评测各种量化精度和性能,以及某些自定义数据集的性能差异,只需要调整数据集或者在部署框架上调整即可 确认数据集和模型正常创建配置后执行以下命令启动评测,例如使用mmbenchv1.1数据集。如果提示api-key的问题,因为是本地使用的模型,可以在VLMEvalKit/.env中创建个假的key ``` python run.py --data MMBench_V11 --model Qwen2.5VL3BSglang Please install pyav to use video processing functions. [2025-10-27 18:35:24] WARNING - RUN - run.py: main - 217: --reuse is not set, will not reuse previous (before one day) temporary files /home/hi/Documents/VLMEvalKit/vlmeval/smp/file.py:485: UserWarning: --reuse flag not set but history records detected in ./outputs/Qwen2.5VL3BSglang/T20251027_Gb9ff66c9. Those files are moved to ./outputs/Qwen2.5VL3BSglang/T20251027_Gb9ff66c9/bak_20251027183525_MMBench_V11 for backup. warnings.warn( [2025-10-27 18:35:25] INFO - ChatAPI - lmdeploy.py: __init__ - 200: lmdeploy evaluate model: /mnt/fd9ef272-d51b-4896-bfc8-9beaa52ae4a5/dingfeng1/Qwen2.5-VL-3B-Instruct/ [2025-10-27 18:35:25] INFO - ChatAPI - lmdeploy.py: __init__ - 203: using custom prompt None [2025-10-27 18:35:25] INFO - ChatAPI - lmdeploy.py: __init__ - 205: Init temperature: 0 0%| | 0/12175 [00:00<?, ?it/s][2025-10-27 18:35:27] INFO - ChatAPI - lmdeploy.py: generate_inner - 292: Generate temperature: 0 [2025-10-27 18:35:27] INFO - ChatAPI - lmdeploy.py: generate_inner - 292: Generate temperature: 0 [2025-10-27 18:35:27] INFO - ChatAPI - lmdeploy.py: generate_inner - 292: Generate temperature: 0 [2025-10-27 18:35:27] INFO - ChatAPI - lmdeploy.py: generate_inner - 292: Generate temperature: 0 B. if a new batch of concrete was firm enough to use A. Do slugs eat more from tomato leaves or broccoli leaves? A. Do more bacteria grow in liquid with cinnamon than in liquid without cinnamon? [2025-10-27 18:35:27] INFO - ChatAPI - lmdeploy.py: generate_inner - 292: Generate temperature: 0 [2025-10-27 18:35:27] INFO - ChatAPI - lmdeploy.py: generate_inner - 292: Generate temperature: 0 0%| | 3/12175 [00:00<35:18, 5.74it/s][2025-10-27 18:35:27] INFO - ChatAPI - lmdeploy.py: generate_inner - 292: Generate temperature: 0 B. Do ping pong balls travel farther when launched from a 30¬∞ angle compared to a 45¬∞ angle? 0%| | 4/12175 [00:00<37:27, 5.41it/s]A. Does apple juice expand more or less than water when it freezes? A. Do more bacteria grow in liquid with cinnamon than in liquid without cinnamon? 0%| | 6/12175 [00:00<24:31, 8.27it/s]A. if the weather station would work when the temperature was 50¬∞C [2025-10-27 18:35:28] INFO - ChatAPI - lmdeploy.py: generate_inner - 292: Generate temperature: 0 A. if a new batch of concrete was firm enough to use [2025-10-27 18:35:28] INFO - ChatAPI - lmdeploy.py: generate_inner - 292: Generate temperature: 0 0%| | 8/12175 [00:01<27:18, 7.42it/s][2025-10-27 18:35:28] INFO - ChatAPI - lmdeploy.py: generate_inner - 292: Generate temperature: 0 [2025-10-27 18:35:28] INFO - ChatAPI - lmdeploy.py: generate_inner - 292: Generate temperature: 0 B. Do muffins made with white flour have larger volumes than muffins made with whole wheat flour? B. Do circuits that include iron produce dimmer light than circuits that include copper? 0%| | 10/12175 [00:01<28:48, 7.04it/s]A. It has warm, wet summers. It also has only a few types of trees. 0%|▏ | 11/12175 [00:01<27:10, 7.46it/s][2025-10-27 18:35:28] INFO - ChatAPI - lmdeploy.py: generate_inner - 292: Generate temperature: 0 [2025-10-27 18:35:28] INFO - ChatAPI - lmdeploy.py: generate_inner - 292: Generate temperature: 0 A. raccoon A. repel 0%|▏ | 13/12175 [00:01<24:51, 8.15it/s][2025-10-27 18:35:29] INFO - ChatAPI - lmdeploy.py: generate_inner - 292: Generate temperature: 0 [2025-10-27 18:35:29] INFO - ChatAPI - lmdeploy.py: generate_inner - 292: Generate temperature: 0 A. stretchy A. repel 0%|▏ | 15/12175 [00:01<23:30, 8.62it/s][2025-10-27 18:35:29] INFO - ChatAPI - lmdeploy.py: generate_inner - 292: Generate temperature: 0 [2025-10-27 18:35:29] INFO - ChatAPI - lmdeploy.py: generate_inner - 292: Generate temperature: 0 B. transparent B. salty 0%|▏ ``` #### 1.2.4.4 评估结果可视化 ``` MMBench_V11 [2025-10-27 18:56:13] INFO - RUN - run.py: main - 410: {'nproc': 4, 'verbose': False, 'retry': 3, 'model': 'chatgpt-0125'} [2025-10-27 18:56:14] INFO - ChatAPI - gpt.py: __init__ - 142: Environment variable OPENAI_API_BASE is set. Will use it as api_base. [2025-10-27 18:56:14] INFO - ChatAPI - gpt.py: __init__ - 160: Using API Base: http://0.0.0.0:23333/v1/chat/completions; API Key: sk-123456 /home/hi/Documents/VLMEvalKit/vlmeval/dataset/image_mcq.py:271: UserWarning: OPENAI API is not working properly, will use exact matching for evaluation warnings.warn('OPENAI API is not working properly, will use exact matching for evaluation') /home/hi/Documents/VLMEvalKit/vlmeval/dataset/image_mcq.py:272: UserWarning: To debug the OpenAI API, you can try the following scripts in python: You cam see the specific error if the API call fails. warnings.warn(DEBUG_MESSAGE) [2025-10-27 18:56:31] WARNING - Evaluation - multiple_choice.py: mcq_circular_eval - 548: Exact Matching mode, will not do GPT-based answer matching. [2025-10-27 18:56:32] INFO - RUN - run.py: main - 465: The evaluation of model Qwen2.5VL3BSglang x dataset MMBench_V11 has finished! [2025-10-27 18:56:32] INFO - RUN - run.py: main - 466: Evaluation Results: [2025-10-27 18:56:32] INFO - RUN - run.py: main - 472: -------------------------------------- ------------------- ------------------- split test dev Overall 0.7651948051948052 0.75 AR 0.8204081632653061 0.7865853658536586 CP 0.7814814814814814 0.7762430939226519 FP-C 0.704119850187266 0.6145251396648045 FP-S 0.8445475638051044 0.8546712802768166 LR 0.625 0.5725806451612904 RR 0.7093023255813954 0.7528735632183908 action_recognition 0.8632478632478633 0.7692307692307693 attribute_comparison 0.7333333333333333 0.5490196078431373 attribute_recognition 0.8426966292134831 0.9 celebrity_recognition 0.9183673469387755 0.9393939393939394 function_reasoning 0.9222222222222223 0.8833333333333333 future_prediction 0.68 0.56 identity_reasoning 0.9868421052631579 1.0 image_emotion 0.7888888888888889 0.85 image_quality 0.5161290322580645 0.39285714285714285 image_scene 0.8888888888888888 0.9479166666666666 image_style 0.7717391304347826 0.8225806451612904 image_topic 0.9777777777777777 0.9166666666666666 nature_relation 0.717391304347826 0.7741935483870968 object_localization 0.6476190476190476 0.6142857142857143 ocr 0.9555555555555556 0.95 physical_property_reasoning 0.5443037974683544 0.4716981132075472 physical_relation 0.49333333333333335 0.54 social_relation 0.8791208791208791 0.9032258064516129 spatial_relationship 0.4266666666666667 0.44 structuralized_imagetext_understanding 0.5871559633027523 0.581081081081081 -------------------------------------- ------------------- ------------------- ``` - 观察 - Qwen2.5VL7BSglang 在 Overall、FP-C、FP-S、RR、attribute_recognition、future_prediction、nature_relation、object_localization、spatial_relationship 等多项指标上表现明显优于 Qwen2.5VL3BSglang。 - Qwen2.5VL3BSglang 在 AR、action_recognition、function_reasoning、identity_reasoning、image_emotion、ocr、physical_property_reasoning 等维度上略优。 - 两者在部分维度(如 image_scene, image_topic)持平。 - 综合来看,Qwen2.5VL7BSglang 的整体表现更好,尤其在复杂关系、定位、未来预测等任务上提升明显。
dingfeng
2025年10月28日 18:00
550
0 条评论
转发文档
收藏文档
上一篇
下一篇
评论
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码