Public Docs
【模型量化】深度学习模型量化 & 量化理论 & 各平台的量化过程 & 硬件加速
【TVM】TI关于TVM的使用测试与分析
【LLM&LVM】大模型开源工程思维导图
SmartSip
【北航卓越工程师】《汽车前沿技术导论:智能驾驶》讲义
【工具链】Yocto使用介绍——使用Yocto创建一个树莓派的系统镜像
【工具链】使用ssh+dialog指令设定服务器指定用户仅容器访问
【推理引擎】一篇关于模型推理的详细对比与学习
【推理引擎】关于TVM中的Schedule优化详解(On going)
【LLM微调】使用litgpt进行私有数据集模型微调的测试总结
【TVM】在TVM Relay中创建一个自定义操作符
【STT+LLM+TTS】如何使用语音转文字模型+大预言模型+语音生成模型完成一个类人的语音交互机器人
【RAG】 通过RAG构建垂直领域的LLM Agent的方法探索
【RAG】GraphRAG精读与测试(On going)
【AI Agent】MetaGPT精读与学习
【AI Base】Ilya Sutskever 27篇必读论文分享清单
【Nvidia】Jetson AGX Orin/ Jetson Orin nano 硬件测试调试内容(On going)
【BI/DI】LLM Using in BI Testing Scenario (On going)
【Nvidia】How to Activate a Camera on Nvidia Platform in Details
【RAS-PI】树莓派驱动开发
【行业咨询阅读】关注实时咨询和分析
【mobileye】2024 Driving AI
【mobileye】SDS_Safety_Architecture
【yolo】yolov8测试
【nvidia】Triton server实践
【alibaba】MNN(on updating)
【OpenAI】Triton(on updating)
【CAIS】关于Compound AI Systems的思考
【Nvidia】关于Cuda+Cudnn+TensorRT推理环境
【BEV】BEVDet在各个平台上的执行效率及优化(On Updating)
【Chip】AI在芯片设计和电路设计中的应用
【Chip】ChiPFormer
【Chip】关于布线的学习
【Chip】MaskPlace论文精读与工程复现优化
【gynasium】强化学习初体验
【Cadence】X AI
【transformer】MinGPT开源工程学习
【中间件】针对apollo 10.0中关于cyberRT性能优化的深度解读和思考
【Robotics】调研了解当前机器人开发者套件(on updating)
【Robotics】ROS CON China 2024 文档技术整理与感想总结(上2024.12.7,中2024.12.8,下场外产品)
【algorithm】关于模型、数据与标注规范的平衡问题
【nvidia】DLA的学习了解与使用
【nvidia】构建nvidia嵌入式平台的交叉编译环境(其他环境平台可借鉴)
【2025AI生成式大会】2025大会个人总结
【Robotics】 Create Quadruped Robot RL FootStep Training Environment In IsaacLab
【Robotics】如何一个人较为完整的完成一个机器人系统软件算法层面的设计与开发
【VLM】读懂多模态大模型评价指标
【VLM】大模型部署的端侧部署性能与精度评估方法与分析
【Nvidia】Jetson Orin 平台VLM部署方法与指标评测
【Database】向量数据库
【SoC】性能与功耗评估
【MCP】MCP探索
【InnoFrance】一个“关于声音”的有趣项目
【Robotics】写给那些想要快速了解机器人或者具身智能的工程师们
【Robotics】open X Embodiment RT-X 数据集下载与使用和分析
文档发布于【Feng's Docs】
-
+
首页
【VLM】读懂多模态大模型评价指标
# 0 Brief 在尝试使用多模态大模型做一些垂类场景的验证和测试,所以一直在尝试Qwen系列VL模型的效果。随着Qwen3-VL 4B和8B的开源 https://www.datalearner.com/blog/1051760490394906 更加面向AI Agent和机器人,因为本身想要验证的垂类场景对图像的要求极为苛刻,要在高保真图像中找到像素级微小的缺陷(以下图为例找出印刷品上印刷结果和原矢量图上的区别,`要求忽略掉本身印刷物的色差的因素,又要找到相关印刷缺陷,如多墨、少墨、墨点、墨线、漏印、覆盖等等`),所以回过头来仔细看一下在Agent场景评估的一些任务和指标,以便确认当前QwenVL系列的数据和能力的提升,以及如何评估对于指代性任务的表现。  # 1 指标 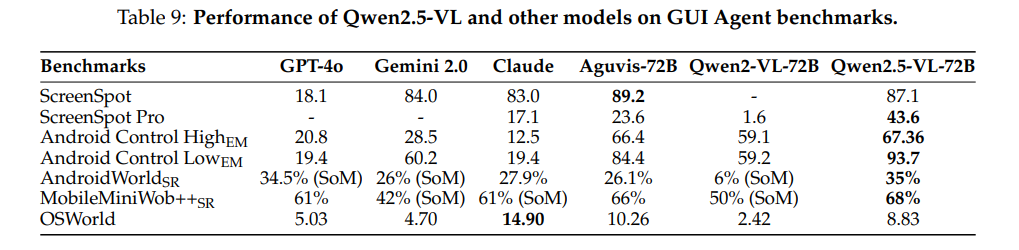 从Qwen2.5 VL和Qwen3VL使用的Agent的评价指标来看,整体任务分成以下几种: `“ The UI elements grounding is evaluated by ScreenSpot (Cheng et al., 2024) and ScreenSpot Pro (Li et al., 2025a). Offline evaluations are conducted on Android Control (Li et al., 2024f), while online evaluations are performed on platforms including AndroidWorld (Rawles et al., 2024), MobileMiniWob++ (Rawles et al., 2024), and OSWorld (Xie et al., 2025)”` ## 1.1 ScreenSpot 论文《SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents》(南京大学计算机学院和上海AIlab)是一项关于视觉GUI智能体的开创性工作,主要聚焦于提升GUI智能体的grounding能力,即`智能体对图形界面元素的准确定位和理解能力`。在人工智能和自然语言处理领域,grounding指的是将抽象的语言、指令或符号与现实世界中的具体实体、感知信息或环境状态建立联系的过程。 具体来说,grounding就是让模型或智能体能够“理解”语言或指令所指代的实际对象或场景,从而实现准确的操作或推理。 举个例子: * 在视觉GUI代理中,grounding就是让智能体能够根据界面截图和指令,准确定位到“按钮”、“输入框”等具体的界面元素,而不是仅仅停留在文字描述层面。 * 在机器人领域,grounding意味着机器人能够将“拿起桌子上的红色杯子”这句话中的“红色杯子”与它通过摄像头看到的具体物体对应起来。 ### 这篇论文的核心内容包括: 1. 提出了一种名为SeeClick的视觉GUI代理,仅依靠界面截图,在不同GUI平台上执行点击和打字等操作,避免依赖冗长或不可访问的结构化文本数据(如HTML、DOM等)。 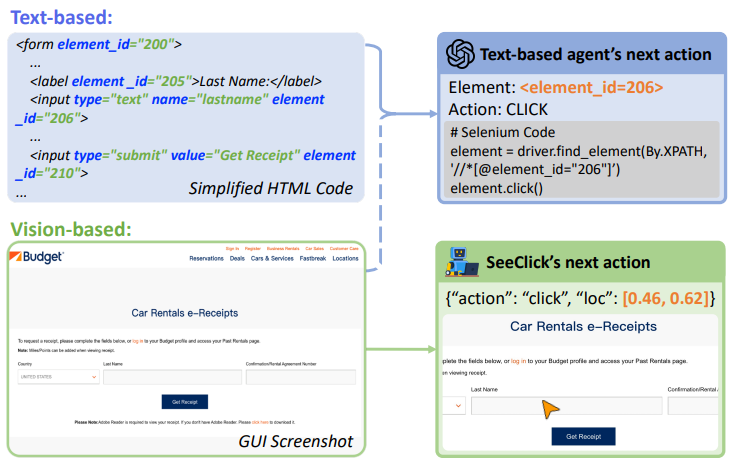 2. 设计了一种GUI grounding预训练策略,通过增强模型对界面元素的定位能力,提升智能体在复杂GUI任务中的表现。 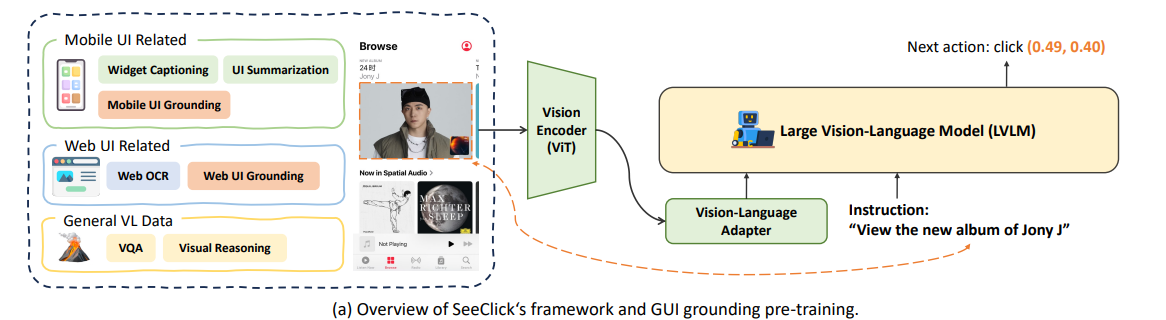 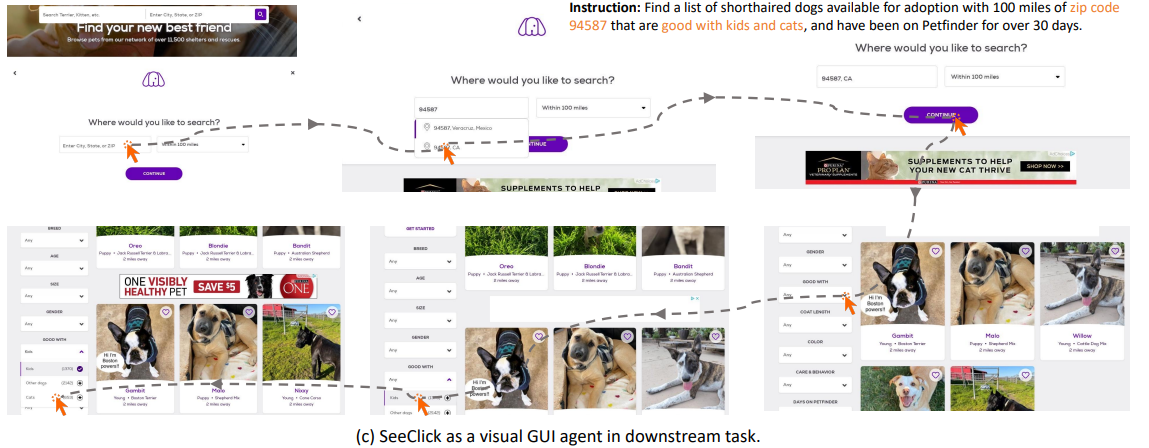 3. `构建了一个名为ScreenSpot的基准数据集,包含来自多种GUI平台(iOS, Android, MacOS, Windows 和 webpages)的600个截图和1200多条指令,用于训练和评估GUI grounding能力。` 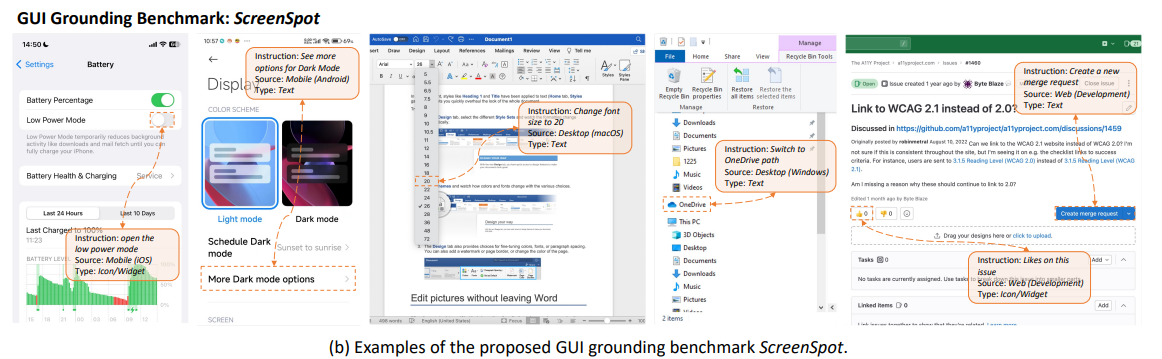 4. 实验结果表明,增强的grounding能力是提升下游GUI任务性能的关键。 该工作解决了传统GUI智能体依赖结构化数据的局限,强调通过视觉信息和自然语言输出实现更高效、更通用的GUI操作智能体。 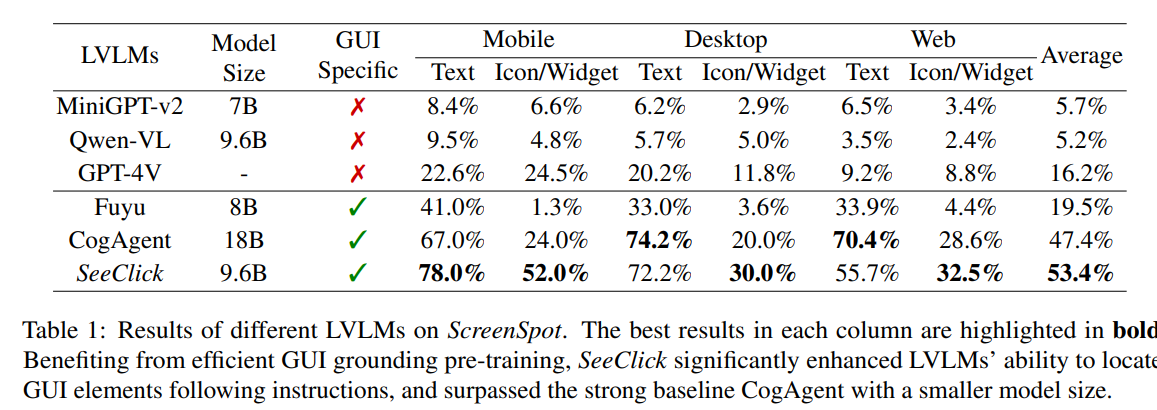 ### 关于数据构建 数据来源包括三种:网络上爬取的webui数据,移动端UI理解数据和VL指令跟随的通识数据。互联网数据大概300k左右,包含文本信息的图像展示和一些特殊标题或者文本在鼠标悬浮状态下的展示信息,以确保能够收集到足够的用来做理解任务和OCR任务的文本信息和符号信息。 移动端数据则包含:UI组件,UI理解和移动端UI总结。包含20k截屏、40k组件和100k描述。 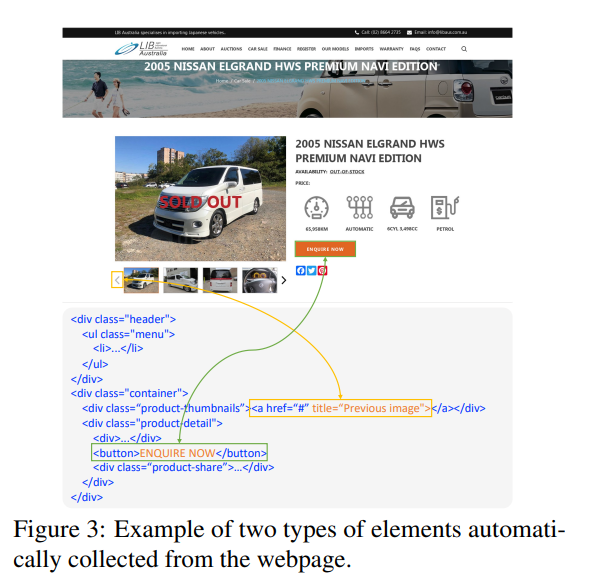 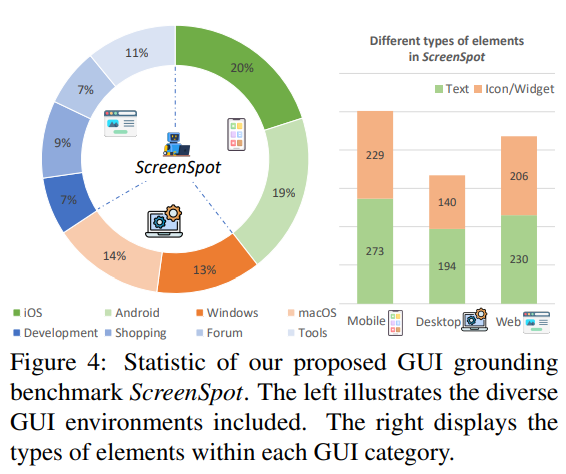 ## 1.2 ScreenSpot Pro 论文《ScreenSpot-Pro: GUI Grounding for Professional High-Resolution Computer Use》(新加坡国立,香港浸会,东南大学,salesforce研究所等等)提出了一个新的GUI grounding基准,专门用于评估和推动在专业、高分辨率计算机环境下的GUI智能体能力。 ### 该论文主要内容包括: * 高分辨率环境适配:针对专业用户使用的高分辨率、多显示器等复杂界面环境,设计了更具挑战性的GUI grounding任务。不同于之前的评价数据,screenSpot pro数据具备高分辨率,专业应用和种类多样的特点(Visual Studio Code, AutoCAD, Photoshop等等),由专业用户标注数据质量较高。 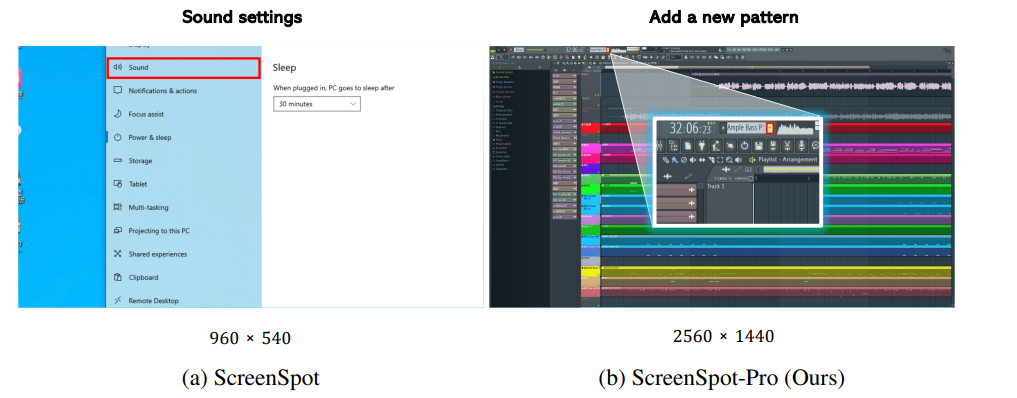 * `基准数据集:构建了包含丰富界面元素和操作指令的高质量数据集,用于训练和评测GUI智能体的定位和理解能力。`包含1581条专家标注数据包含工作流和一个截屏,包括5种工业领域得23种应用,在3种常用的操作系统上。 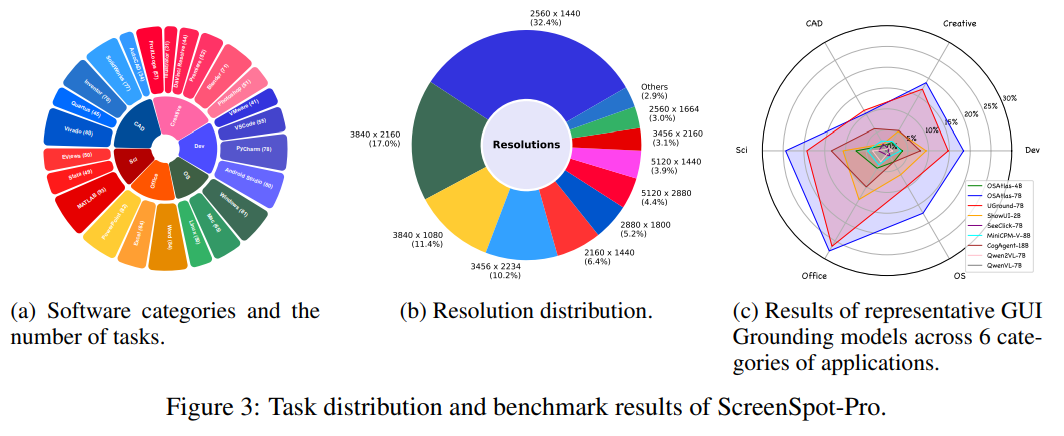 * 提升GUI智能体性能:通过该基准,推动模型在复杂界面中准确识别和操作界面元素,提升智能体在真实办公环境中的实用性和鲁棒性。 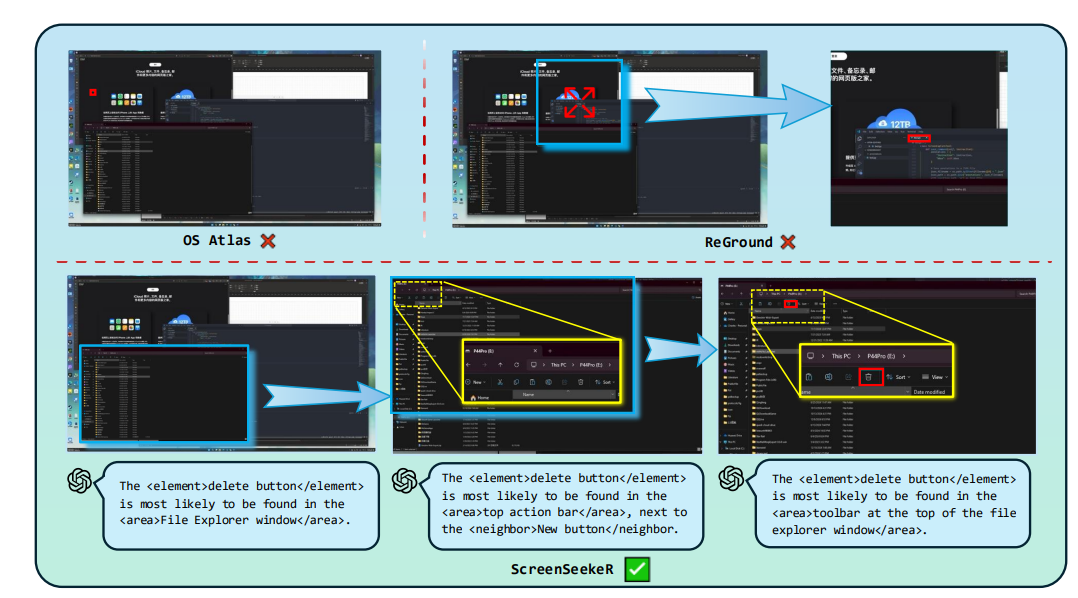 * 该工作是对之前ScreenSpot基准的扩展,更加贴近专业用户的实际使用场景,促进多模态GUI智能体在高分辨率和复杂界面环境中的发展。 ### 关于数据 数据囊获了多种专业软件   在质量控制上,ScreenSpot-Pro采用了三种主要手段,包含超过两个以上5年专业经验的标注员的确认,目标框的精度确认,图标文字分类确认。 ### 关于基准评估 ScreenSpot-Pro 基准上评估的五种基线方法,具体包括: * GPT Instruction:利用强大的 GPT-4o 模型对截图进行分析,生成优化后的详细指令,辅助定位任务。 * 无规划器视觉搜索方法(Planner-Free Visual Search): * 迭代分割(Iterative Splitting):从整张截图开始定位,逐步将截图分割成更小的区域,选择预测所在的区域继续搜索,采用固定的2行×2列分割策略。 * 迭代缩小(Iterative Narrowing):类似迭代分割,但每次裁剪的区域以预测中心为中心,区域大小为当前图像宽高的一半。 * ReGround:基于初始预测裁剪周围区域重新定位,裁剪大小固定,可根据模型输入大小调整。 * ScreenSeekeR:基于代理的定位框架 * 利用应用界面通常具有的层级结构特性,结合 GPT-4o 作为规划器,生成可能包含目标的候选区域,指导搜索过程。 * 通过“位置推断”模块,GPT-4o 根据指令预测目标的大致位置及其邻近元素,生成候选区域。 * 对候选区域进行评分和筛选,采用中心性评分函数和非极大值抑制减少重叠区域。 * 递归搜索候选区域,直到找到目标或达到最大搜索深度。 总结来说,这些方法从简单的指令优化,到无规划器的多轮视觉搜索,再到结合规划器的智能递归搜索,逐步提升了在高分辨率专业界面中定位目标的能力。 ### 关于错误信息分析 1. 错误分类: 被图标误导(Misled by Icon):模型选择了错误的图标元素,而非目标。 被文本误导(Misled by Text):模型选择了与指令不符的文本元素。 接近命中(Near Miss):预测位置接近真实目标(在真实框大小的3倍范围内)。 随机猜测(Random Guess):输出与目标无明显关联。 未找到(Not Found):模型未能找到目标。 2. 错误分布与分析: 所有方法中,“接近命中”错误频繁,表明需要更精确的定位模型。 许多错误源于对视觉或语义相似元素的误解,例如模型选中了“tool”这个词,而非指令中特定的工具。 图标识别错误也占较大比例,反映当前多模态大模型(MLLM)在专业领域知识上的不足。 3. 方法表现对比: ScreenSeekeR 在除“未找到”外的所有错误类别中表现最好,错误率最低。 “未找到”错误主要来自 ScreenSeekeR 的规划器未能定位目标而提前终止搜索。 另外两种方法虽然总是给出预测,但因此产生了更多“随机猜测”错误。 ## 1.3 AndroidControl 《On the Effects of Data Scale on UI Control Agents》(google deepmind)自主代理(autonomous agents)控制用户界面(UI)以完成用户任务的技术正在兴起。利用大型语言模型(LLMs)驱动这类代理成为关注热点,但如果不经过基于人类示范的微调,性能仍然较低。论文探讨仅通过微调是否能构建实用的UI控制代理。 作者收集并发布了一个新的数据集ANDROIDCOTROL,包含15,283条使用Android应用完成日常任务的示范。  该数据集相比现有数据集更丰富,每个任务实例包含高层和低层的人类指令,任务多样性高(14,548个独特任务,覆盖833个Android应用),支持深入分析模型在训练域内外的表现。  在训练域内,微调模型表现优于零样本和少样本基线,且性能随着数据规模增长而提升,表明通过增加数据量有望获得稳健表现。 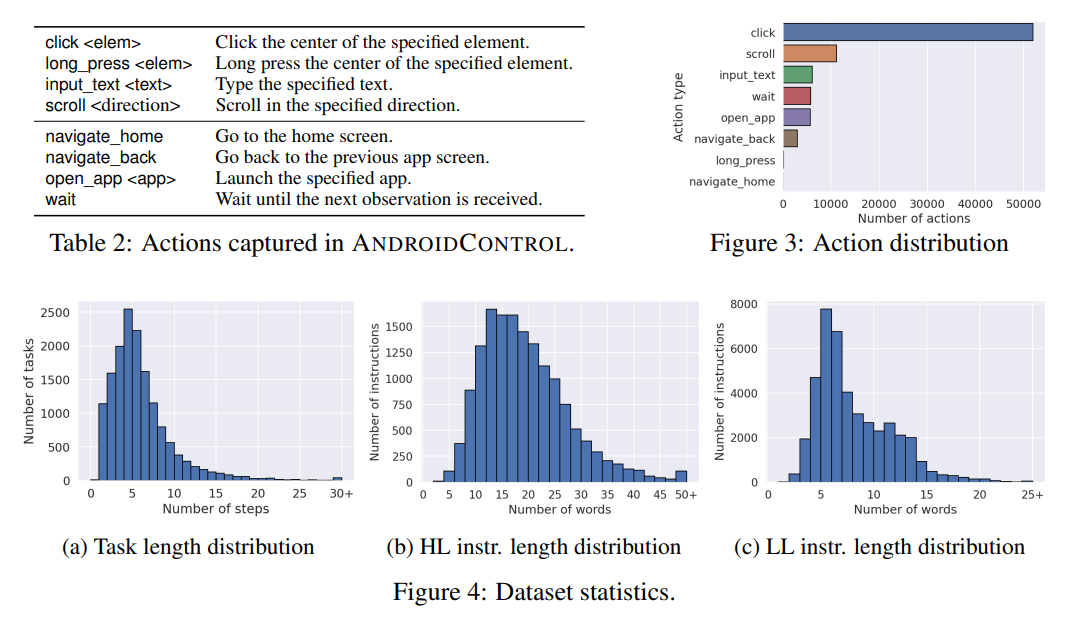 在训练域外,性能提升较慢,尤其是对于高层任务,单靠增加微调数据量难以实现稳健的泛化能力。 总结来说,论文强调了数据规模对UI控制代理性能的显著影响,指出微调在域内有效,但在域外泛化仍需更多方法支持。并且通过发布大规模、多样化的数据集,为后续研究提供了重要资源。 ## 1.4 AndroidWorld 论文《ANDROIDWORLD: A DYNAMIC BENCHMARKING ENVIRONMENT FOR AUTONOMOUS AGENTS》(google deepmind)介绍了一个名为ANDROIDWORLD的动态基准测试环境,旨在评估自主代理在真实Android移动设备上完成多样化任务的能力。 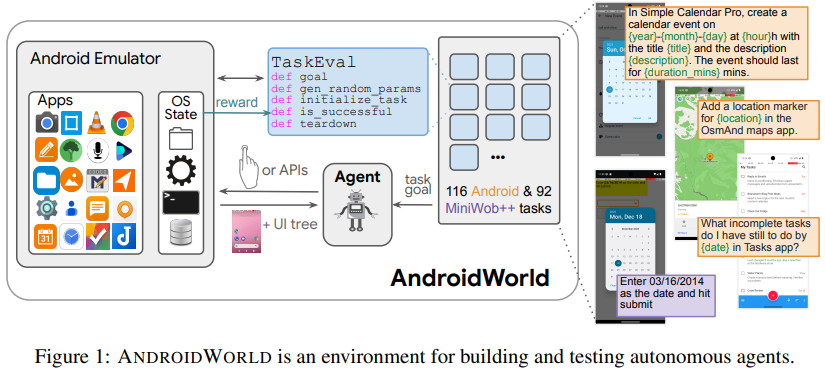 该平台的主要特点包括: * `真实Android环境:支持20个真实的Android应用,涵盖116个程序化任务,能够在真实的移动设备环境中运行和测试代理。` * 动态任务生成:任务通过参数化和自然语言表达动态构建,支持无限多样的任务变体,远超传统静态测试集的规模和复杂度。 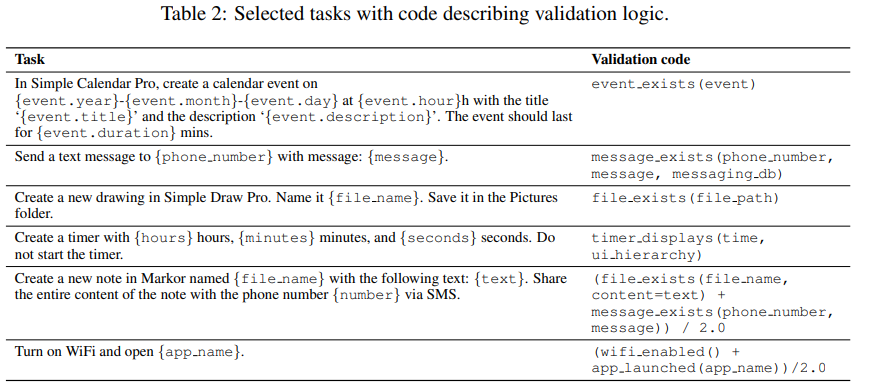 * 任务完整性保障:每个任务包含专门的初始化、成功检查和清理逻辑,确保任务的可重复性和系统状态的准确管理。 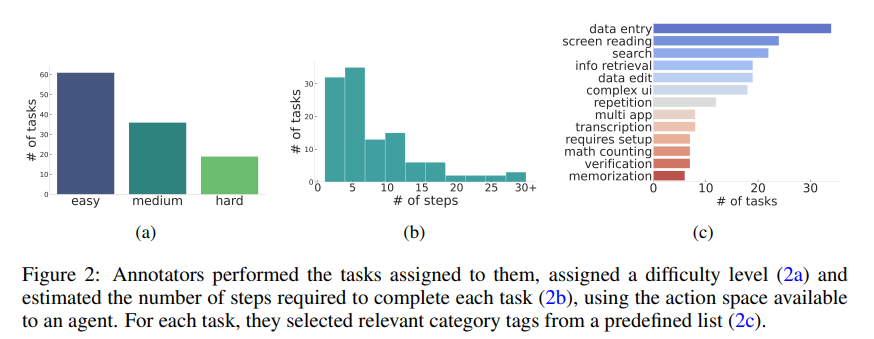 * 奖励信号设计:基于设备系统状态的修改和检查,提供明确的奖励信号,支持跨任务和跨应用的持续评估。 * 基线代理实验:设计并测试了多种基线代理,最佳代理完成率为30.6%,表明任务具有较高挑战性,未来仍有较大提升空间。 * 跨平台适配分析:将流行的桌面网页代理适配到Android环境,发现其性能显著下降,提示移动端代理需要专门优化。 * 鲁棒性评估:任务变体对代理性能影响显著,强调多样化测试对真实性能评估的重要性。 该工作解决了现有移动端代理基准环境任务静态、规模有限的问题,提供了一个动态、可扩展且现实的Android任务基准平台,为移动端自主代理的研究和应用提供了重要支持和参考。 ### 相比较于其他benchmark 1. 专注于移动平台(Android) 目前大多数基准环境集中于桌面计算环境或网页环境,缺乏针对移动设备(如Android)的全面解决方案。而Android拥有数十亿用户,是自动化代理极具潜力的应用场景。ANDROIDWORLD填补了这一空白,专门面向真实的Android移动环境设计。 2. 真实应用与动态任务生成 ANDROIDWORLD涵盖20个真实的Android应用,提供116个程序化任务。与许多基准环境只支持静态测试集不同,ANDROIDWORLD的任务是动态实例化的,使用随机生成的参数,支持数百万种独特的任务目标和条件,极大提升了任务的多样性和现实复杂度。 3. 可靠且持久的奖励信号 真实应用和网站通常不提供明确的奖励信号,传统方法依赖人工或基于大语言模型的评判,存在扩展性差或不完全可靠的问题。ANDROIDWORLD通过利用Android操作系统的状态管理机制,实现了自动化且持久的奖励信号,确保任务完成的功能正确性能够被准确量化。 4. 跨应用和跨任务的系统状态管理 通过Android系统自身的数据存储和更新机制,ANDROIDWORLD能够在任务初始化、执行和清理阶段保持系统状态的一致性和准确性,保证任务的可重复性和评估的公平性。 5. 轻量级且易用 ANDROIDWORLD设计轻量,仅需2GB内存和8GB磁盘空间,且通过Python库AndroidEnv连接Android模拟器,方便研究者快速部署和使用。 6. 集成网页任务,支持多模态测试 除了Android任务,ANDROIDWORLD还集成了MiniWoB++网页基准,支持多模态输入(文本、图像等),为代理提供更丰富的感知和交互能力。 7. 基线代理与性能分析 提供了多模态自主代理M3A作为基线,取得30.6%的任务成功率,显著优于适配的网页代理,但仍远低于人类80%的成功率,显示出该环境的挑战性和研究潜力。 8. 鲁棒性与多样性测试的重要性 通过对任务参数变化的系统性测试,发现代理性能受任务变体影响显著,强调了在多样化和动态任务条件下评估代理的必要性,避免性能指标被静态测试集所掩盖。 综上,ANDROIDWORLD在移动端真实环境、多样化动态任务、自动化持久奖励信号、系统状态管理和易用性等方面均优于现有基准,填补了移动平台自动化代理评测的空白,推动了该领域的研究和应用发展。 ## 1.5 OSWorld 论文《OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments》(香港大学,salesforce研究所,滑铁卢大学,卡耐基梅隆大学)介绍了一个名为OSWorld的基准测试平台,旨在评估多模态智能代理在真实计算机环境中完成开放式任务的能力。该平台的主要特点包括: * 真实计算机环境:支持跨多个操作系统(如Ubuntu、Windows、macOS),能够在真实的计算机环境中运行和测试代理。 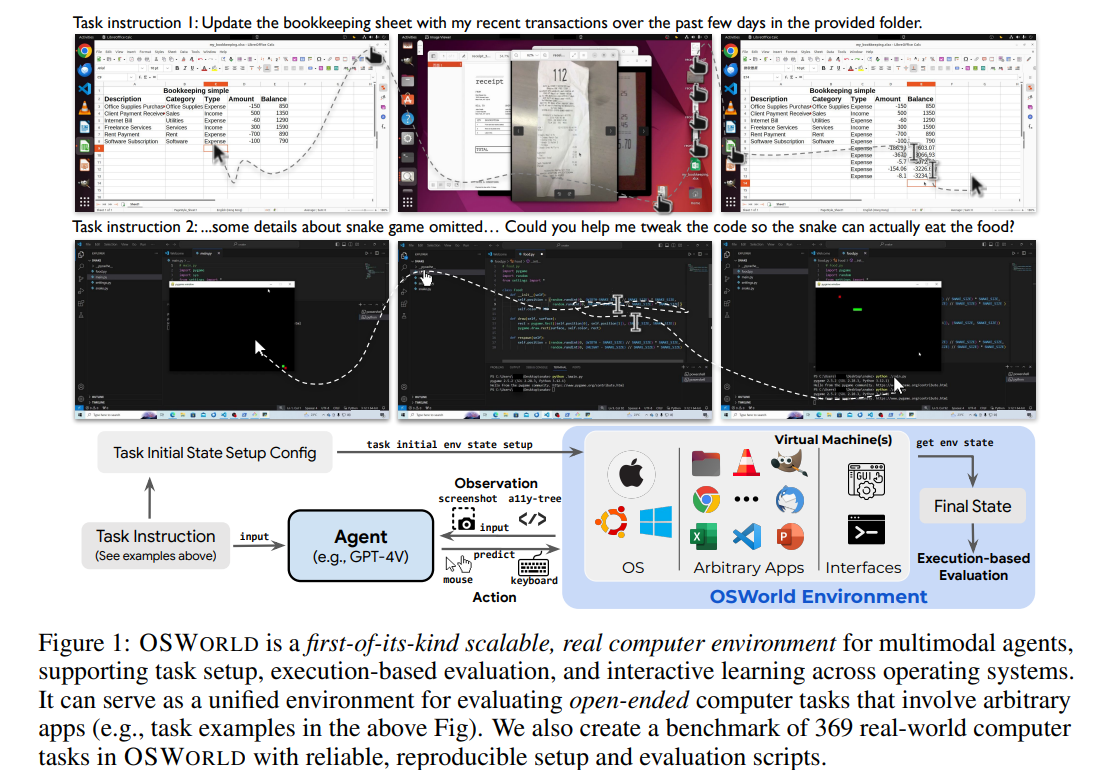 * 多模态交互:代理可以处理图像、文本等多种输入形式,实现更自然和复杂的人机交互。 * 开放式任务:支持各种开放式计算机任务,不局限于特定应用或领域,提升代理的适用范围和灵活性。  * 基于执行的评估:通过实际执行任务来评估代理性能,避免传统基准中只认可单一正确解的局限。 * 交互式学习:支持代理在环境中通过交互不断学习和改进。 * `一个包含369个真实计算机Ubuntu系统上的任务数据集和43个windows系统上的任务` 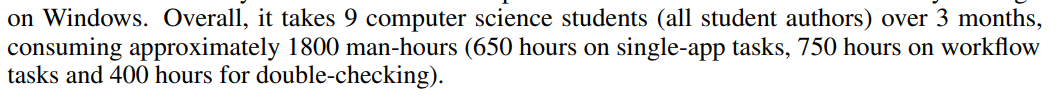 该工作解决了现有基准测试环境过于简化、任务范围有限的问题,为多模态智能代理在复杂真实环境中的应用提供了统一且可扩展的评测平台。 ### 关于数据 * 数据集统计 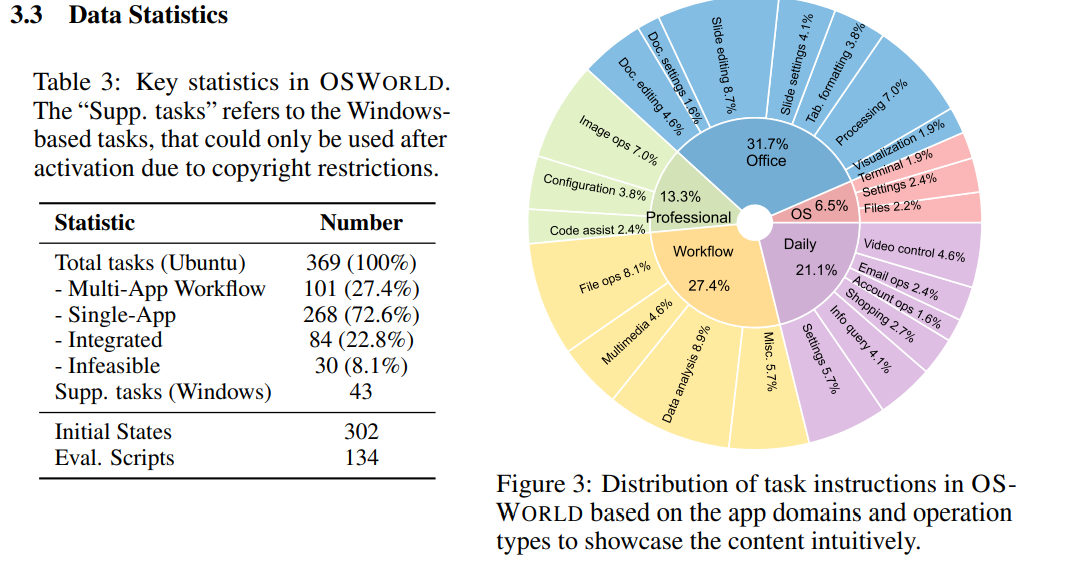 * 任务难度统计  # 2 Conclusion 从数据集内容来看,ScreenSpot,ScreenSpot-Pro,Android Control,AndroidWorld 和 OSworld 对于Agent来说任务难度是逐渐增大的; 不同数据集都有自己的特点,ScreenSpot和ScreenSpot-pro 更侧重单个screenspot+instruction的这种短任务形式,pro面向更专业的软件,具有更高保真的数据和更高的数据质量; AnroidControl,AndroidWorld和OSWorld 则更多包含了长程任务,并且任务种类,多样性等方面有明显的难度提升,前两者更多是在移动端而后者则是PC端; # Annexe * Qwen2.5 VL:https://arxiv.org/pdf/2502.13923 * ScreenSpot:https://arxiv.org/pdf/2401.10935 * ScreenSpot Pro:https://likaixin2000.github.io/papers/ScreenSpot_Pro.pdf * Android Control:https://arxiv.org/pdf/2406.03679 * Android World and MobileMini:https://arxiv.org/pdf/2405.14573 * OSworld:https://arxiv.org/pdf/2404.07972
dingfeng
2025年10月15日 18:13
1555
0 条评论
转发文档
收藏文档
上一篇
下一篇
评论
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码