Public Docs
【模型量化】深度学习模型量化 & 量化理论 & 各平台的量化过程 & 硬件加速
【TVM】TI关于TVM的使用测试与分析
【LLM&LVM】大模型开源工程思维导图
SmartSip
【北航卓越工程师】《汽车前沿技术导论:智能驾驶》讲义
【工具链】Yocto使用介绍——使用Yocto创建一个树莓派的系统镜像
【工具链】使用ssh+dialog指令设定服务器指定用户仅容器访问
【推理引擎】一篇关于模型推理的详细对比与学习
【推理引擎】关于TVM中的Schedule优化详解(On going)
【LLM微调】使用litgpt进行私有数据集模型微调的测试总结
【TVM】在TVM Relay中创建一个自定义操作符
【STT+LLM+TTS】如何使用语音转文字模型+大预言模型+语音生成模型完成一个类人的语音交互机器人
【RAG】 通过RAG构建垂直领域的LLM Agent的方法探索
【RAG】GraphRAG精读与测试(On going)
【AI Agent】MetaGPT精读与学习
【AI Base】Ilya Sutskever 27篇必读论文分享清单
【Nvidia】Jetson AGX Orin/ Jetson Orin nano 硬件测试调试内容(On going)
【BI/DI】LLM Using in BI Testing Scenario (On going)
【Nvidia】How to Activate a Camera on Nvidia Platform in Details
【RAS-PI】树莓派驱动开发
【行业咨询阅读】关注实时咨询和分析
【mobileye】2024 Driving AI
【mobileye】SDS_Safety_Architecture
【yolo】yolov8测试
【nvidia】Triton server实践
【alibaba】MNN(on updating)
【OpenAI】Triton(on updating)
【CAIS】关于Compound AI Systems的思考
【Nvidia】关于Cuda+Cudnn+TensorRT推理环境
【BEV】BEVDet在各个平台上的执行效率及优化(On Updating)
【Chip】AI在芯片设计和电路设计中的应用
【Chip】ChiPFormer
【Chip】关于布线的学习
【Chip】MaskPlace论文精读与工程复现优化
【gynasium】强化学习初体验
【Cadence】X AI
【transformer】MinGPT开源工程学习
【中间件】针对apollo 10.0中关于cyberRT性能优化的深度解读和思考
【Robotics】调研了解当前机器人开发者套件(on updating)
【Robotics】ROS CON China 2024 文档技术整理与感想总结(上2024.12.7,中2024.12.8,下场外产品)
【algorithm】关于模型、数据与标注规范的平衡问题
【nvidia】DLA的学习了解与使用
【nvidia】构建nvidia嵌入式平台的交叉编译环境(其他环境平台可借鉴)
【2025AI生成式大会】2025大会个人总结
【Robotics】 Create Quadruped Robot RL FootStep Training Environment In IsaacLab
【Robotics】如何一个人较为完整的完成一个机器人系统软件算法层面的设计与开发
【VLM】读懂多模态大模型评价指标
【VLM】大模型部署的端侧部署性能与精度评估方法与分析
【Nvidia】Jetson Orin 平台VLM部署方法与指标评测
【Database】向量数据库
【SoC】性能与功耗评估
【MCP】MCP探索
【InnoFrance】一个“关于声音”的有趣项目
【Robotics】写给那些想要快速了解机器人或者具身智能的工程师们
【Robotics】open X Embodiment RT-X 数据集下载与使用和分析
文档发布于【Feng's Docs】
-
+
首页
【nvidia】构建nvidia嵌入式平台的交叉编译环境(其他环境平台可借鉴)
# 0. Introduction 从工程开发的角度如果要针对nvdia嵌入式平台上的软件或者应用软件做标准化的流水线设计和软件编译发布,那就要充分利用nv提供的工具链能力,并结合自己项目的实际情况,将相关工作集成到自己的软件工作流中完成软件发布的流水线。 作为个人开发者或者小团队针对应用开发,通常对于整个流水线的要求并没有太多的规则和要求,通常都会直接在嵌入式平台上直接进行应用软件的开发与编译。对于一个==前期需要较多创新,修改和调整较多的项目==来说的,这样的方式在前期有较好的灵活性,对于不太熟悉嵌入式soc上开发应用或者OS,bsp的团队和个人来说,这样的方式能够==很快上手==。 * (`便利性`)这一方面得益与nv 比如 Jetson AGX Orin平台强大的性能,和类似个人电脑的易用性; * (`针对性`)另一方面如果要进行深度学习推理模型的板端性能优化,tensorRT的engine文件需要针对平台进行优化,所以需要在target平台上执行相关转换步骤。 但是因为`嵌入式平台的成本`和针对`多人协同工作`的便利性,合理使用目标平台的能力和个人开发设备,还是能大大提高开发过程中的功能稳定性和软件质量。 `本文针对以上问题总结了在嵌入式平台上的一种开发和配置流程,并给出了详细的步骤,方便0-1团队之后的软件健壮性和多人协同效率的提升`。==重点是在于针对nvidia的平台,如何基于自己团队的工程化能力使用一种适合的软件部署方案==。 ## 0.1 各种部署方案的对比 ``` mindmap # 直接编译测试 ## arm平台编译 ## 利用qemu # 间接编译 ## nv toolchain ## build in docker nv crosscompile container ## build with yocto ``` |方案|详细说明|优点|缺点|适用性备注| |-|-|-|-|-| |arm平台编译|因为目标平台是arm架构,所以可以直接借助市面上性能强大的arm架构的pc设备完成编译流程。如mac m系列| |qemu+docker|QEMU,全称Qick Emulator,是一个开源的机器与设备模拟器,其可以进行系统态模拟与用户态模拟。其中系统态模拟主要指机器模拟,能支持的架构有很多,包括x86,power,arm,mips等 |使用nv提供的交叉编译toolchain| nv官方有提供直接可以在X86上做交叉编译的工具链。详见 |yocto|yocto是一个开源的专门用于嵌入式linux镜像发布的工具,可直接发布linux镜像,交叉编译工具等| |docker 交叉编译镜像|nvidia官方有提供专门用于做交叉编译工作的docker镜像,方便在不影响宿主机环境的情况下完成交叉编译工作| # 1. Details ## 1.1. PreDetails 首先,截止2025.1.10,个人目前了解到,假设要在Orin 平台(分DRIVE Orin,Jetson AGX Orin,Jetson Orin NX,Jetson Orin {super} Nano)上进行软件开发和工程部署,有以下几种选择: * (**直接**)直接在Orin平台上进行编译,优点是问题少,缺点是效率低,一般一个研发团队也不会人手一个orin平台。如果是X86上开发,Orin上由一个人完成适配,也是一种方案,不过可能会出现爆发式集中式的平台切换问题和库版本问题。 * (**交叉编译**)熟悉嵌入式SOC BSP开发的通常会选择 `Yocto` 的方案。优点是方便,缺点是有一定门槛。 * 目前了解到NVIDIA官方针对DRIVE Orin(非Ubuntu)能够提供官方的Yocto BSP,而非DRIVE Orin 目前没有官方版本[https://forums.developer.nvidia.com/t/differences-between-using-yocto-project-and-jetpack/257971](https://forums.developer.nvidia.com/t/differences-between-using-yocto-project-and-jetpack/257971) 。 * 用户可以选择非官方版本的合作伙伴方案[https://developer.ridgerun.com/wiki/index.php/Yocto_Support_for_NVIDIA_Jetson_Platforms_-_Setting_up_Yocto](https://developer.ridgerun.com/wiki/index.php/Yocto_Support_for_NVIDIA_Jetson_Platforms_-_Setting_up_Yocto) 不过相关平台的使用范围比较有限。具体见下图,带`*`的是未经过验证的。同时支持的L4T版本依次是36.4,35.5/6,32.x...,使用时注意选择。 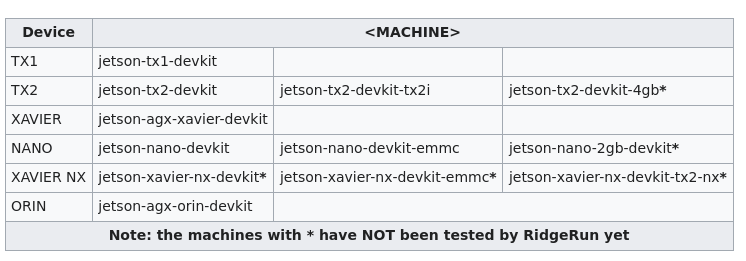 * (**交叉编译**)还有一种方式就是自己构建交叉编译环境。nvidia官方针对这种情况也是给出了详细的解决方案。如果是针对嵌入式SOC BSP开发不太熟悉的团队,两种方式都能达到目的,个人比较推荐第一种方式,因为如果遇到以来问题或者是系统依赖库冲突导致不可用等问题,容器中的环境不会影响上位机的状态。 * 一种是docker容器化的方式[https://catalog.ngc.nvidia.com/orgs/nvidia/containers/jetpack-linux-aarch64-crosscompile-x86](https://catalog.ngc.nvidia.com/orgs/nvidia/containers/jetpack-linux-aarch64-crosscompile-x86) ; * 一种是直接在上位机系统上直接构建的方式[https://docs.nvidia.com/jetson/archives/r35.4.1/DeveloperGuide/text/AT/JetsonLinuxToolchain.html?highlight=cross%20compile](https://docs.nvidia.com/jetson/archives/r35.4.1/DeveloperGuide/text/AT/JetsonLinuxToolchain.html?highlight=cross%20compile) ; * 即使是使用第一种docker容器的方案,仍然会在编译各种依赖库时遇到意想不到的问题,比如通过bazel进行编译,或者通过colcon catkin_make 编译ROS这样的大型第三方库。个人了解到不少团队会使用直接在target平台上先进行编译再将依赖库拷贝会docker 容器并构建镜像的方案。 `针对以上描述,本文核心展示交叉编译的结果,并直接展示如果通过YOCTO 和 docker容器的方案直接完成 ROS工程编译的过程,为之后要选择nv嵌入式平台开发的团队提供一些高效软件部署的思路,供借鉴`。我这边使用的是一台12core 24thread 12th Gen Intel(R) Core(TM) i9-12900K cpu,rtx4090 gpu,128GB MEM的设备。目标设备是Jetson AGX Orin 32GB版本。 ## 1.2. YOCTO Build ### 1.2.1. TIPS 根据上文中提到的的第三方yocto meta-tegra的支持,可以直接完成镜像的编译,编译时注意以下几点: * 根据提示完成git的安全配置 `git config --global --add safe.directory '*'` * 硬盘有`200GB`以上的空间,硬盘是`ext4`的linux专用格式,最好是`SSD`,速度快一些 * `不要使用root`用户,否则需要再conf文件中进行权限配置 * 如果遇到`liblsp.so preload`的问题,可以对/etc/ld.so.preload 进行修改该注释掉文件中的/lib/$LIB/liblsp.so * 如果是向我一样使用ssd,注意挂载配置`/dev/sdb1 on /media/mamba/mamba type ext4 (rw,nosuid,nodev,noexec,relatime, ...)` 不要出现noexec,放置在使用dtc编译设备树配置时出现权限问题 * 如果过程中出现一些冲突等信息,可以尝试删除tmp文件夹或者执行`bitbake -c cleansstate` 确保不会出现以来冲突的情况使得编译失败。 ### 1.2.2. Build Image https://developer.ridgerun.com/wiki/index.php/Yocto_Support_for_NVIDIA_Jetson_Platforms_-_Setting_up_Yocto 根据相关操作,针对35.5版本的L4T(linux for tegra)顺利得话可以正常完成镜像编译如下图。 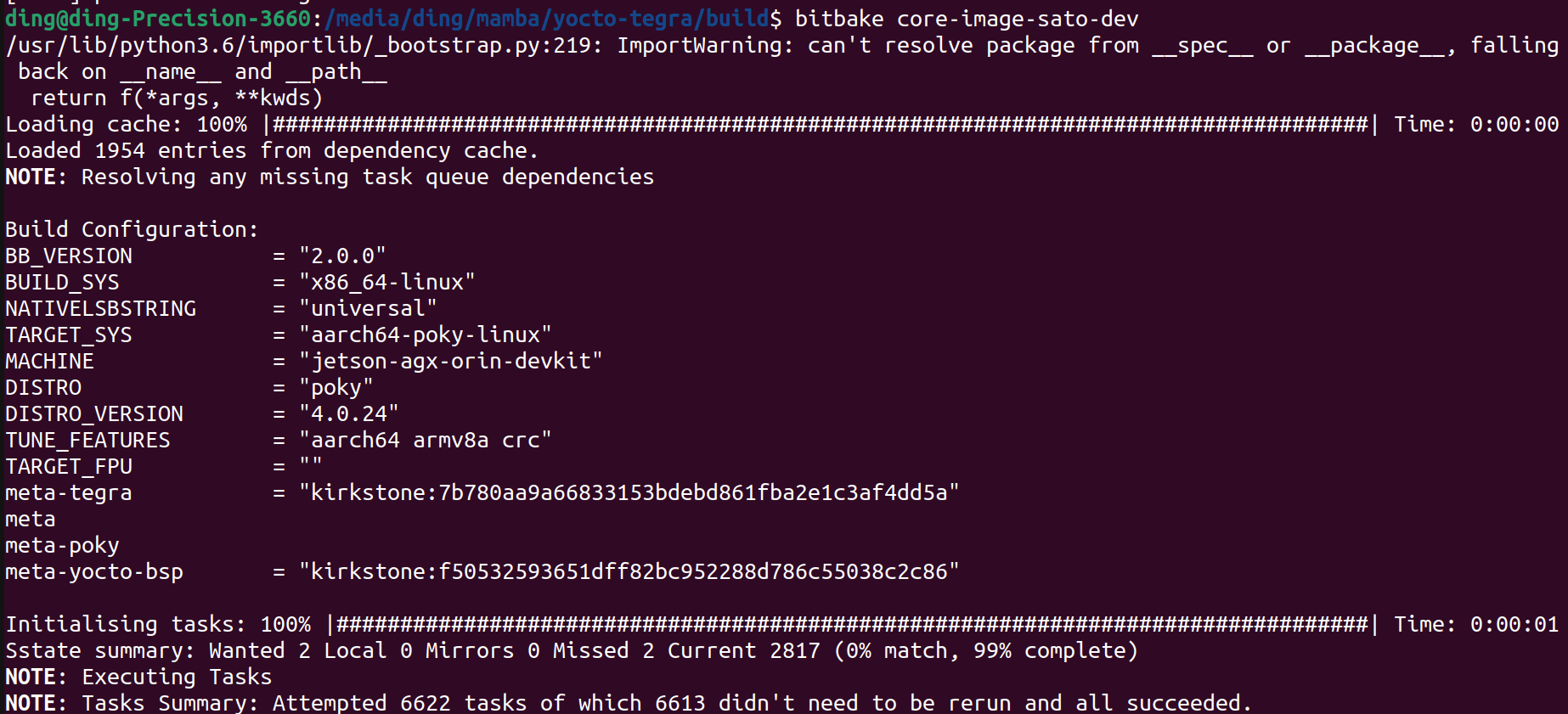 ### 1.2.3. Build ROS2 * 确认一下选择的meta tegra和yocto仓库分支版本是否有对ROS2对应版本的支持。我们的是kirkstone,ROS2 humble,可以看到还是一个LTS,可以放心进行测试。 https://github.com/ros/meta-ros 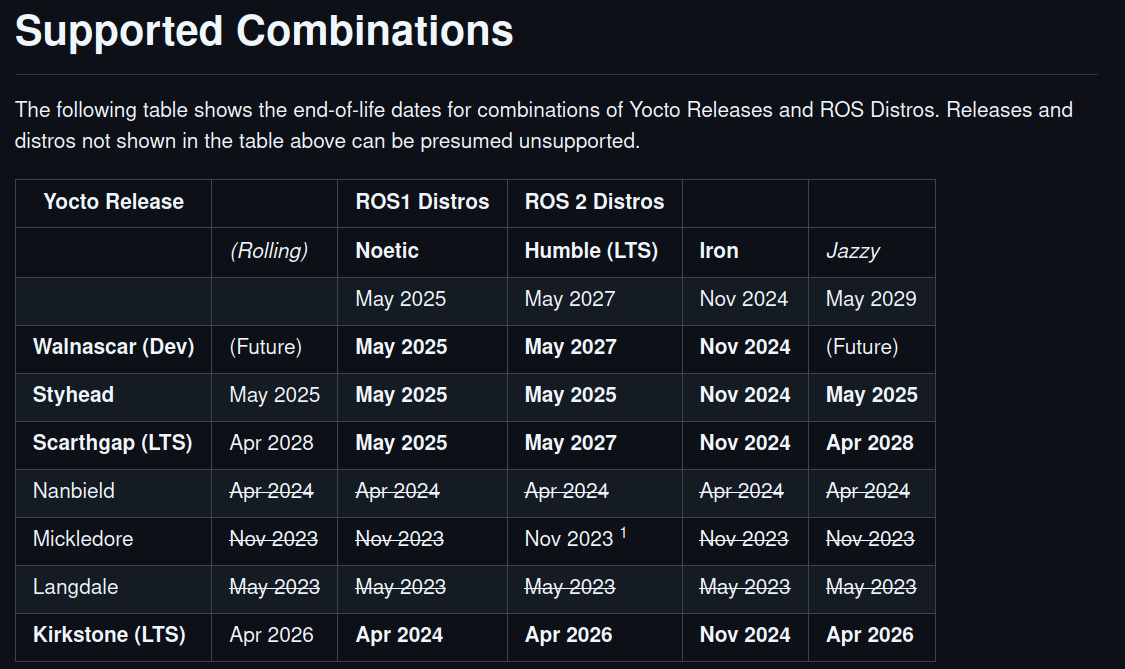 * 其次就是将ros-humble添加到 DISTRO_FEATURES 中进行镜像编译。具体过程如下: * 修改该conf/local.conf文件,可以之间添加`DISTRO_FEATURES:append = " ros-humble"` 如果是已经定义了DISTRO_FEATURES,也可以直接在DISTRO_FEATURES 中添加 ros-humble。这么做的目的是使得编译镜像时将ros-humble添加到镜像当中。 * 然后就是要添加ros-humble被编译所需要的recipy. ``` # 下载对应分支的meta-ros git clone -b kirkstone https://github.com/ros/meta-ros.git # 将 meta-ros-common,meta-ros2,meta-ros2-humble三个meta-layer添加到bblayers.conf中,注意顺序因为meta-ros-common中定义了变量${ROS_OE_RELEASE_SERIES} # meta-ros会依赖meta-openembedded git clone -b kirkstone https://github.com/openembedded/meta-openembedded.git # 将meta-python和meta-oe添加到bblayers.conf中,开始编译 bitbake <image> ``` 顺利得话你会看到正常完成的结果。之后如果如果要编译自己的应用,并发布镜像,就可以以该yocto工程作为基础。 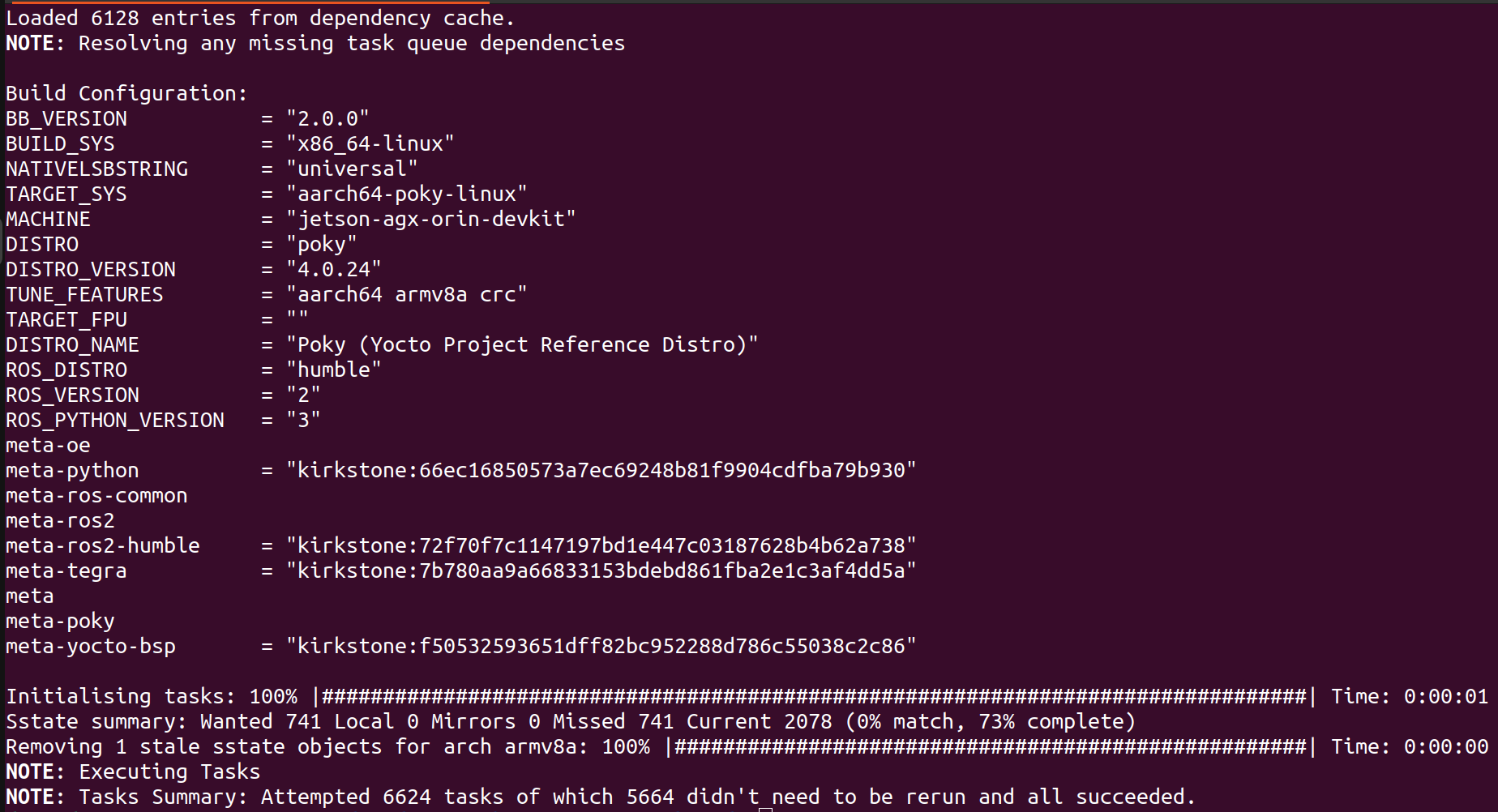 ### 1.2.4 Test Image On Target Device 进入 tmp/deploy/images/jetson-agx-orin-devkit/ 找到需要的Image和rootfs,可以使用dd,balenaEtcher,或者直接使用tegraflash工具完成镜像刷写。 ## 1.3. Docker Container Build ### 1.3.1. Create Docker Container https://catalog.ngc.nvidia.com/orgs/nvidia/containers/jetpack-linux-aarch64-crosscompile-x86 根据以上连接并完成相应的步骤,即可完成一个能够进行tensorRT,Cuda,Cudnn等基础依赖库的交叉编译环境构建。通过交叉编译Cuda-sample,VPI-Sample和自定义的小样例,即可确认整个交叉编译环境的构建是正常的。  其中非常重要的文件是,`Toolchain_aarch64_l4t.cmake`,在使用cmake进行其他模块的编译时,通过使用`-DCMAKE_TOOLCHAIN_FILE=Toolchain_aarch64_l4t.cmake`即可在执行cmake时帮助我们使用交叉编译工具链。如果需要编译第三方库,完成编译后记得将编译好的第三方库的install_path添加到该文件中,以便头文件和库文件能够在需要时被找到并使用。 ``` set(CMAKE_SYSTEM_NAME Linux) set(CMAKE_SYSTEM_PROCESSOR aarch64) set(target_arch aarch64-linux-gnu) set(CMAKE_LIBRARY_ARCHITECTURE ${target_arch} CACHE STRING "" FORCE) # Configure cmake to look for libraries, include directories and # packages inside the target root prefix. set(CMAKE_FIND_ROOT_PATH_MODE_PROGRAM NEVER) set(CMAKE_FIND_ROOT_PATH_MODE_LIBRARY ONLY) set(CMAKE_FIND_ROOT_PATH_MODE_INCLUDE ONLY) set(CMAKE_FIND_ROOT_PATH_MODE_PACKAGE ONLY) set(CMAKE_FIND_ROOT_PATH "/usr/${target_arch}") # needed to avoid doing some more strict compiler checks that # are failing when cross-compiling set(CMAKE_TRY_COMPILE_TARGET_TYPE STATIC_LIBRARY) # specify the toolchain programs find_program(CMAKE_C_COMPILER ${target_arch}-gcc) find_program(CMAKE_CXX_COMPILER ${target_arch}-g++) if(NOT CMAKE_C_COMPILER OR NOT CMAKE_CXX_COMPILER) message(FATAL_ERROR "Can't find suitable C/C++ cross compiler for ${target_arch}") endif() set(CMAKE_AR ${target_arch}-ar CACHE FILEPATH "" FORCE) set(CMAKE_RANLIB ${target_arch}-ranlib) set(CMAKE_LINKER ${target_arch}-ld) # Not all shared libraries dependencies are instaled in host machine. # Make sure linker doesn't complain. set(CMAKE_EXE_LINKER_FLAGS_INIT -Wl,--allow-shlib-undefined) # instruct nvcc to use our cross-compiler set(CMAKE_CUDA_FLAGS "-ccbin ${CMAKE_CXX_COMPILER} -Xcompiler -fPIC" CACHE STRING "" FORCE) # add custom dependencies here set(TARGET_FS "/l4t/targetfs/") include_directories(${TARGET_FS}/usr/include) link_directories(${TARGET_FS}/lib) ``` ### 1.3.2. Build ROS2 As an example * 安装相关依赖并使用vcs指令下载完整的ros2-humble依赖的仓库,https://raw.githubusercontent.com/ros2/ros2/humble/ros2.repos * ros2正常使用colcon进行编译构建,可以直接使用colcon命令,并将`-DCMAKE_TOOLCHAIN_FILE=Toolchain_aarch64_l4t.cmake` 作为cmake参数传递,同时添加一些build_prefix以便find package可以找到相关目录 # 1.4 Execute aarch64 on X86 * docker run --rm --privileged multiarch/qemu-user-static --reset -p yes * docker pull --platform=linux/arm64 ros:humble-ros-core * docker run -it --platform=linux/arm64 --name my_arm_container ros:humble-ros-core /bin/bash * uname -m ``` colcon build --merge-install --cmake-force-configure --packages-skip rviz_ogre_vendor --symlink-install --cmake-args -DCMAKE_TOOLCHAIN_FILE=/l4t/NVIDIA_VPI-3.1-samples/08-cross_aarch64_l4t/Toolchain_aarch64_l4t.cmake -DBUILD_TESTING=OFF -Diceoryx_hoofs_DIR=/workspace/ros2_humble/install/lib/cmake/iceoryx_hoofs/ -Dament_cmake_core_DIR=/workspace/ros2_humble/install/share/ament_cmake_core/cmake/ -Diceoryx_posh_DIR=/workspace/ros2_humble/install/lib/cmake/iceoryx_posh/ -Dament_cmake_python_DIR=/workspace/ros2_humble/install/share/ament_cmake_python/cmake/ -Dament_cmake_test_DIR=/workspace/ros2_humble/install/share/ament_cmake_test/cmake/ -Dament_cmake_export_dependencies_DIR=/workspace/ros2_humble/install/share/ament_cmake_export_dependencies/cmake/ -Dament_cmake_gtest_DIR=/workspace/ros2_humble/install/ament_cmake_gtest/share/ament_cmake_gtest/cmake/ -DCMAKE_CXX_STANDARD=17 -DBUILD_TESTING=OFF -Dament_cmake_DIR=/workspace/ros2_humble/install/share/ament_cmake/cmake/ -Dament_cmake_libraries_DIR=/workspace/ros2_humble/install/share/ament_cmake_libraries/cmake/ -Dament_cmake_export_definitions_DIR=/workspace/ros2_humble/install/share/ament_cmake_export_definitions/cmake/ -Dament_cmake_export_include_directories_DIR=/workspace/ros2_humble/install/share/ament_cmake_export_include_directories/cmake/ -Dament_cmake_export_interfaces_DIR=/workspace/ros2_humble/install/share/ament_cmake_export_interfaces/cmake/ -Dament_cmake_export_libraries_DIR=/workspace/ros2_humble/install/share/ament_cmake_export_libraries/cmake/ -Dament_cmake_export_link_flags_DIR=/workspace/ros2_humble/install/share/ament_cmake_export_link_flags/cmake/ -Dament_cmake_export_targets_DIR=/workspace/ros2_humble/install/share/ament_cmake_export_targets/cmake/ -Dament_cmake_gen_version_h_DIR=/workspace/ros2_humble/install/share/ament_cmake_gen_version_h/cmake/ -Dament_cmake_target_dependencies_DIR=/workspace/ros2_humble/install/share/ament_cmake_target_dependencies/cmake/ -Dament_cmake_include_directories_DIR=/workspace/ros2_humble/install/share/ament_cmake_include_directories/cmake/ -Dament_cmake_version_DIR=/workspace/ros2_humble/install/share/ament_cmake_version/cmake/ -Dament_cmake_gmock_DIR=/workspace/ros2_humble/install/share/ament_cmake_gmock/cmake/ -Dament_cmake_gtest_DIR=/workspace/ros2_humble/install/share/ament_cmake_gtest/cmake/ -Dzstd_vendor_DIR=/workspace/ros2_humble/install/share/zstd_vendor/cmake/ -Dbenchmark_DIR=/workspace/ros2_humble/install/lib/cmake/benchmark/ -DCMAKE_C_FLAGS="-Wno-error" -DCMAKE_CXX_FLAGS="-Wno-error" ``` # Annexe * https://forums.developer.nvidia.com/t/differences-between-using-yocto-project-and-jetpack/257971 * https://forums.developer.nvidia.com/t/cross-compilation-for-agx-orin/295419 * https://developer.ridgerun.com/wiki/index.php/Yocto_Support_for_NVIDIA_Jetson_Platforms_-_Setting_up_Yocto * https://docs.nvidia.com/jetson/archives/r35.4.1/DeveloperGuide/text/AT/JetsonLinuxToolchain.html?highlight=cross%20compile * https://catalog.ngc.nvidia.com/orgs/nvidia/containers/jetpack-linux-aarch64-crosscompile-x86 (交叉编译镜像) * https://catalog.ngc.nvidia.com/orgs/nvidia/containers/l4t-jetpack (jetson 板端镜像) * https://github.com/ros/meta-ros * https://github.com/OE4T/meta-tegra * https://catalog.ngc.nvidia.com/containers?filters=&orderBy=weightPopularDESC&query=&page=&pageSize= (nvidia 镜像仓库)
dingfeng
2025年2月4日 08:51
3311
0 条评论
转发文档
收藏文档
上一篇
下一篇
评论
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码