Public Docs
【模型量化】深度学习模型量化 & 量化理论 & 各平台的量化过程 & 硬件加速
【TVM】TI关于TVM的使用测试与分析
【LLM&LVM】大模型开源工程思维导图
SmartSip
【北航卓越工程师】《汽车前沿技术导论:智能驾驶》讲义
【工具链】Yocto使用介绍——使用Yocto创建一个树莓派的系统镜像
【工具链】使用ssh+dialog指令设定服务器指定用户仅容器访问
【推理引擎】一篇关于模型推理的详细对比与学习
【推理引擎】关于TVM中的Schedule优化详解(On going)
【LLM微调】使用litgpt进行私有数据集模型微调的测试总结
【TVM】在TVM Relay中创建一个自定义操作符
【STT+LLM+TTS】如何使用语音转文字模型+大预言模型+语音生成模型完成一个类人的语音交互机器人
【RAG】 通过RAG构建垂直领域的LLM Agent的方法探索
【RAG】GraphRAG精读与测试(On going)
【AI Agent】MetaGPT精读与学习
【AI Base】Ilya Sutskever 27篇必读论文分享清单
【Nvidia】Jetson AGX Orin/ Jetson Orin nano 硬件测试调试内容(On going)
【BI/DI】LLM Using in BI Testing Scenario (On going)
【Nvidia】How to Activate a Camera on Nvidia Platform in Details
【RAS-PI】树莓派驱动开发
【行业咨询阅读】关注实时咨询和分析
【mobileye】2024 Driving AI
【mobileye】SDS_Safety_Architecture
【yolo】yolov8测试
【nvidia】Triton server实践
【alibaba】MNN(on updating)
【OpenAI】Triton(on updating)
【CAIS】关于Compound AI Systems的思考
【Nvidia】关于Cuda+Cudnn+TensorRT推理环境
【BEV】BEVDet在各个平台上的执行效率及优化(On Updating)
【Chip】AI在芯片设计和电路设计中的应用
【Chip】ChiPFormer
【Chip】关于布线的学习
【Chip】MaskPlace论文精读与工程复现优化
【gynasium】强化学习初体验
【Cadence】X AI
【transformer】MinGPT开源工程学习
【中间件】针对apollo 10.0中关于cyberRT性能优化的深度解读和思考
【Robotics】调研了解当前机器人开发者套件(on updating)
【Robotics】ROS CON China 2024 文档技术整理与感想总结(上2024.12.7,中2024.12.8,下场外产品)
【algorithm】关于模型、数据与标注规范的平衡问题
【nvidia】DLA的学习了解与使用
【nvidia】构建nvidia嵌入式平台的交叉编译环境(其他环境平台可借鉴)
【2025AI生成式大会】2025大会个人总结
【Robotics】 Create Quadruped Robot RL FootStep Training Environment In IsaacLab
【Robotics】如何一个人较为完整的完成一个机器人系统软件算法层面的设计与开发
【VLM】读懂多模态大模型评价指标
【VLM】大模型部署的端侧部署性能与精度评估方法与分析
【Nvidia】Jetson Orin 平台VLM部署方法与指标评测
【Database】向量数据库
【SoC】性能与功耗评估
【MCP】MCP探索
【InnoFrance】一个“关于声音”的有趣项目
【Robotics】写给那些想要快速了解机器人或者具身智能的工程师们
【Robotics】open X Embodiment RT-X 数据集下载与使用和分析
文档发布于【Feng's Docs】
-
+
首页
【nvidia】DLA的学习了解与使用
# 0. 为什么要学习DLA,DLA有什么用 **DLA(Deep Learning Accelerator** 是nvidia提供的边缘AI平台的硬件加速能力。他的概念比较大,既有硬件的部分,也有软件的部分,下文的官方文档链接中将DLA描述的非常清楚。 https://developer.nvidia.com/deep-learning-accelerator DLA硬件特指在部分Nvidia的边缘端计算平台上内置的DLA硬件加速器,Jetson Orin系列使用Nvdlav2架构(相较于Xavier上的初代有最高达9倍的性能提升),Jetson Xavier系列则是Nvdla初代架构。而软件则是包含DLA的编译器核运行时软件栈在内的所有工具。先在offline时将网络模型翻译成二进制的dla执行图,用于集成到TensorRT中使用,而runtime则是包含了dla的固件和相关驱动。   除了直接使用dla的软件,我们也可以使用TensorRT发布的统一的平台,来对onnx模型的基于相关参数配置部署于dla上运行。  而相关改动带来的实际收益则是用更低的功耗,更高的性能,释放出cpu和gpu给更多其他应用,并为应用带来更健壮的性能。  # 1. 体验一下DLA 如果是直接使用TensorRT可以使用如下命令。 ``` bash /usr/src/tensorrt/bin/trtexec --onnx=1.3.81_ep003.onnx --saveEngine=1.3.81_ep003.fp16.engine --useDLACore=0 --fp16 --allowGPUFallback # --useDLACore表示使用dla的core,对于有两个core的AGX orin,可以设置0、1。 # --allowGPUFallback如果dla不支持的算子,porting到gpu上运算。 ``` 通常如果--allowGPUFallback,遇到不支持的算子log中会记录warning然后正常运行完成模型转化。否则会直接报错,提示相关算子不支持。  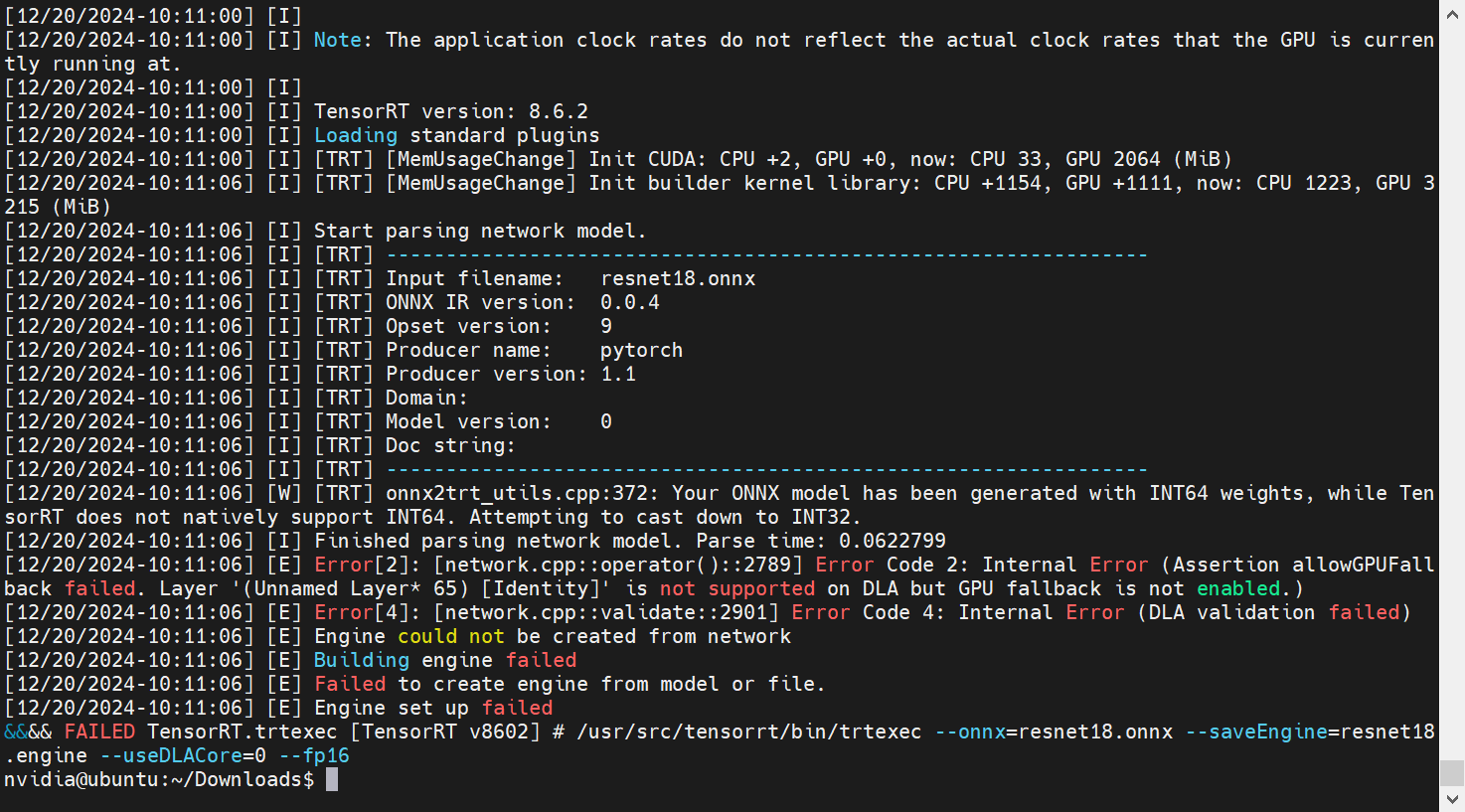 * dla支持的算子如下:https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#dla-lay-supp-rest  # 2. DLA,cuDLA,nvDLA * DLA 是一个广义的术语,涵盖所有用于深度学习加速的硬件和软件解决方案。 * nvDLA 是 NVIDIA 提供的专用深度学习硬件加速器,优化用于边缘计算和嵌入式系统,集成在 NVIDIA 的硬件产品中。 * cuDLA 则是基于 NVIDIA CUDA 平台的软件解决方案,通过利用 GPU 的并行计算能力和优化库(如 cuDNN)来加速深度学习任务。 # 3. 如何检查和分析dla的效果 ## 3.1 查看驱动 首先,基于1我们已经能够知道我们所使用的硬件中是否包含DLA硬件单元,在已经明确硬件包含DLA单元后,我们还需要查看操作系统是否已经有了完备的驱动能够使用DLA的io。 可以使用`sudo dmesg |grep dla`查看,我使用的agx orin拥有两个dla单元。`ps: 早期的驱动dla作为一个单独的io可以使用cat /dev/dla* 看到相关硬件,随着l4t的迭代,目前已经没有了dla的直接硬件io。`  ## 3.2 分析使用率 可以使用nvidia自带的指令`tegrastats`进行分析,当然也可以使用nsight-system&nsight-compute&nsight-graphics等nsight工具包进行性能分析。 * 使用tegrastats需要注意的是是否使用root权限,如果不适用root权限,是无法看到详细信息的,dla占用等都在详细信息中。 * 无sudo  * 有sudo  * 上图数据详解 1. 时间戳: 12-24-2024 10:49:16:当前系统时间,便于记录和分析数据。 2. 内存使用情况:RAM 1226/30698MB:当前已使用 1226 MB RAM,总共有 30698 MB 可用。 (lfb 13x4MB):线性分配块(Linear Frame Buffer)的使用情况。 3. 交换空间(Swap):SWAP 0/15349MB (cached 0MB):当前未使用交换空间,缓存也为 0 MB。 4. CPU 使用率: CPU [5%@729,0%@729,1%@729,0%@729,0%@729,0%@729,0%@729,1%@729,off,off,off,off]: 每个 CPU 核心的使用率及其频率(MHz)。 前 8 个核分别为 5%、0%、1%、0%、0%、0%、0%、1%,后 4 个核处于关闭状态(off)。 5. 内存控制器频率: EMC_FREQ 0%@3199:内存控制器当前未占用频率,最大频率为 3199 MHz。 6. 图形处理器频率: GR3D_FREQ 0%@[0,0]:GPU 当前未使用,频率为 0 MHz。 7. 多媒体加速器状态 NVENC off:NVIDIA 视频编码器未启用。 NVDEC off:NVIDIA 视频解码器未启用。 NVJPG off、NVJPG1 off:JPEG 编码器未启用。 VIC off:视频编解码接口未启用。 OFA off:Open Firmware Accelerator 未启用。 NVDLA0 off、NVDLA1 off:NVIDIA 深度学习加速器 0 和 1 未启用。 PVA0_FREQ off:PVA(Programmable Vision Accelerator)未启用。 8. 温度监控: 各个传感器的温度,例如 cpu@51.093C 表示 CPU 温度为 51.093°C。 9. 功耗监控: 各电压域的功耗,例如 VDD_GPU_SOC 3120mW/3120mW 表示 GPU SoC 电压域的功耗为 3120 mW。 ## 3.3 测试一个使用dla的任务 我们使用resnet50 做测试。相关代码已经上传至代码仓库:https://github.com/FengD/dla_test_code * 模型地址:https://github.com/onnx/models/blob/b9a54e89508f101a1611cd64f4ef56b9cb62c7cf/vision/classification/resnet/model/resnet50-v2-7.onnx * 使用如下指令将onnx模型转为engine文件,分别使用useDLACore和不适用DLACore生成两个文件。 ``` /usr/src/tensorrt/bin/trtexec --onnx=resnet50-v2-7.onnx --saveEngine=resnet50-v2-7-dla-fp16.engine --useDLACore=0 --fp16 --allowGPUFallback ``` * 通过执行编译好的程序可以看到如下信息:当使用dlacore时,模型得推理耗时相较于不适用dlacore有明显增加(经过warmup之后,usedlacore在17ms左右,不适用在3ms左右),但好处是对gpu的tensorcore的使用下降,可以看到GR3D_FREQ显卡使用率从90%下降至1%,猜测可能是因为模型中有dla不支持的层,所以内存使用频率有上升趋势。这个趋势从官方文档的说明中也得到证实。 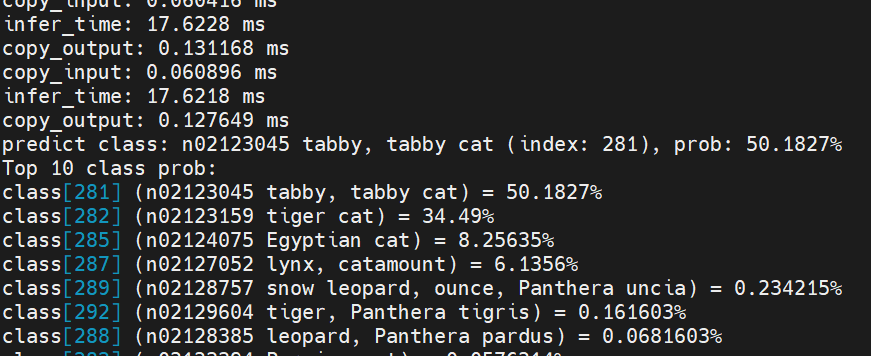      ## 3.4. 进一步使用nsight-system进行分析 进一步保存了nsys的报告用于详细分析。 [【附件】profile_report.nsys-rep](/media/attachment/2024/12/profile_report.nsys-rep) [【附件】profile_report-dla.nsys-rep](/media/attachment/2024/12/profile_report-dla.nsys-rep) # 4. DLA官方文档精读与功能挖掘 * https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#overview # Annexe * https://developer.nvidia.com/deep-learning-accelerator dla说明 * https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#dla_layers dla各层说明 * https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#dla_topic dla 说明 * https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#dla-lay-supp-rests dla支持算子 * https://developer.nvidia.com/zh-cn/blog/optimizing-cuda-memory-transfers-with-nsight-systems/ & https://developer.nvidia.com/zh-cn/blog/accelerating-data-center-and-hpc-performance-analysis-with-nvidia-nsight-systems/ 分析过程实例
dingfeng
2024年12月31日 11:26
3832
0 条评论
转发文档
收藏文档
上一篇
下一篇
评论
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码