Public Docs
【模型量化】深度学习模型量化 & 量化理论 & 各平台的量化过程 & 硬件加速
【TVM】TI关于TVM的使用测试与分析
【LLM&LVM】大模型开源工程思维导图
SmartSip
【北航卓越工程师】《汽车前沿技术导论:智能驾驶》讲义
【工具链】Yocto使用介绍——使用Yocto创建一个树莓派的系统镜像
【工具链】使用ssh+dialog指令设定服务器指定用户仅容器访问
【推理引擎】一篇关于模型推理的详细对比与学习
【推理引擎】关于TVM中的Schedule优化详解(On going)
【LLM微调】使用litgpt进行私有数据集模型微调的测试总结
【TVM】在TVM Relay中创建一个自定义操作符
【STT+LLM+TTS】如何使用语音转文字模型+大预言模型+语音生成模型完成一个类人的语音交互机器人
【RAG】 通过RAG构建垂直领域的LLM Agent的方法探索
【RAG】GraphRAG精读与测试(On going)
【AI Agent】MetaGPT精读与学习
【AI Base】Ilya Sutskever 27篇必读论文分享清单
【Nvidia】Jetson AGX Orin/ Jetson Orin nano 硬件测试调试内容(On going)
【BI/DI】LLM Using in BI Testing Scenario (On going)
【Nvidia】How to Activate a Camera on Nvidia Platform in Details
【RAS-PI】树莓派驱动开发
【行业咨询阅读】关注实时咨询和分析
【mobileye】2024 Driving AI
【mobileye】SDS_Safety_Architecture
【yolo】yolov8测试
【nvidia】Triton server实践
【alibaba】MNN(on updating)
【OpenAI】Triton(on updating)
【CAIS】关于Compound AI Systems的思考
【Nvidia】关于Cuda+Cudnn+TensorRT推理环境
【BEV】BEVDet在各个平台上的执行效率及优化(On Updating)
【Chip】AI在芯片设计和电路设计中的应用
【Chip】ChiPFormer
【Chip】关于布线的学习
【Chip】MaskPlace论文精读与工程复现优化
【gynasium】强化学习初体验
【Cadence】X AI
【transformer】MinGPT开源工程学习
【中间件】针对apollo 10.0中关于cyberRT性能优化的深度解读和思考
【Robotics】调研了解当前机器人开发者套件(on updating)
【Robotics】ROS CON China 2024 文档技术整理与感想总结(上2024.12.7,中2024.12.8,下场外产品)
【algorithm】关于模型、数据与标注规范的平衡问题
【nvidia】DLA的学习了解与使用
【nvidia】构建nvidia嵌入式平台的交叉编译环境(其他环境平台可借鉴)
【2025AI生成式大会】2025大会个人总结
【Robotics】 Create Quadruped Robot RL FootStep Training Environment In IsaacLab
【Robotics】如何一个人较为完整的完成一个机器人系统软件算法层面的设计与开发
【VLM】读懂多模态大模型评价指标
【VLM】大模型部署的端侧部署性能与精度评估方法与分析
【Nvidia】Jetson Orin 平台VLM部署方法与指标评测
【Database】向量数据库
【SoC】性能与功耗评估
【MCP】MCP探索
【InnoFrance】一个“关于声音”的有趣项目
【Robotics】写给那些想要快速了解机器人或者具身智能的工程师们
【Robotics】open X Embodiment RT-X 数据集下载与使用和分析
文档发布于【Feng's Docs】
-
+
首页
【algorithm】关于模型、数据与标注规范的平衡问题
# 0. Introduction 随着整体CV向transformer base发展越来越多,包含利用position embedding等技术,慢慢的大家不再关注特征提取本身,更多的是关注数据。但是实际上,关于模型、数据标注和数据分布本身质检其实也存在这相关平衡。模型既不是愈大越好,标注规范数据标注本身也与数据分布和模型选择有着更加深层次的联系,当遇到模型推理效果不好时并不一定就是数据量不够的原因。本文就是想针对我在实际事件中遇到的一些有意思的问题来探究一下,到底我们应该如何选择模型,以及模型与标注规范和数据本身之间的平衡,帮助我们在之后遇到cv问题时,能从一个更全面的视角去找到合适的解决方案。 # 1. Description ## 1.1. 什么是感受野 **感受野(Receptive Field)**是指在深度神经网络(尤其是卷积神经网络)中,一个特定神经元或特定特征图位置在输入图像(或特征图)上所能“看到”或“受影响”的区域范围。简单来说,感受野描述了网络中的某个输出单元是由输入图像上的哪一块区域的像素信息所决定的。随着网络层数加深,通过多层卷积、池化操作,一个高层特征单元的感受野会越来越大,即它能够汇总更大范围的输入信息。 假设我们有一张输入图像,然后经过数层卷积和池化,一个高层单元对应输入图像上某个子区域的所有信息整合。感受野描述的就是这个对应关系:哪个输入像素区域会影响到该单元的输出。 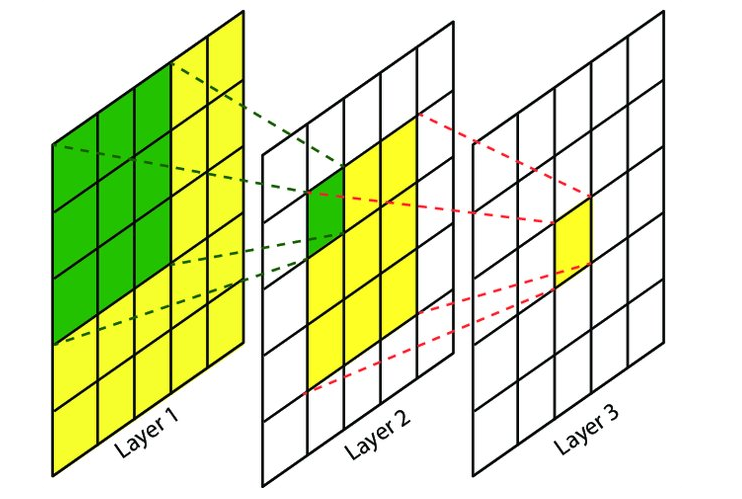 下图为简化的示意图,展示了如何通过多层卷积和池化,感受野由小变大。假设我们有两层卷积,每层卷积核大小为 3x3,不考虑填充(padding)和步幅(stride)简化处理。 ``` 输入图像(较大区域) ┌─────────────────────────┐ │ │ │ ... │ │ [ ] ← 感受野RF │ │ ... │ │ │ └─────────────────────────┘ 第一层卷积特征图 (中间特征图) ┌─────────────────┐ │ │ │ [ ] │ <- 第一层中的单个神经元 │ │ └─────────────────┘ ↑ 该单元的感受野可能是输入图像中 3x3 的区域 第二层卷积特征图 (更高层特征图) ┌───────┐ │ x │ <- 第二层单元 └───────┘ ↑ 由于第二层的该单元连接的是第一层的特征图中的3x3区域 而第一层的每个单元对应输入图像的3x3区域 所以第二层这个单元的感受野将是输入中更大的范围: 实际上是 3x3(第二层卷积核) * 3x3(上一层单元感受野) = 9x9 的输入区域范围(简化举例) 总结: 输入图像 ┌───────────────────────────┐ │ │ │ ... ┌─────────┐ │ │ [感受野] │ .. │ │ │ ... └─────────┘ │ │ │ └───────────────────────────┘ ↑ 二层后的特定单元最终可以看到比原来单层时更大的原图区域, 这就是感受野随层数加深而扩大的直观效果。 ``` 通过这种多层堆叠,深层神经元的感受野会越来越大,有助于模型从局部特征逐渐获取全局信息。 ## 1.2. 感受野的作用 感受野的大小直接决定了我们对于物体特征提取的质量。以下图为例,不同颜色的矩形框示意图分别表示不同网络的最大感受野范围。如果我们希望对猫头的五官进行检测,那绿色框可能会因为感受野不够大而无法区分眼睛和鼻子的区别。而红色的矩形框可能会因为过大而导致将特征由低维特征变化为高维特征后,淹没眼睛区域的特征表达。 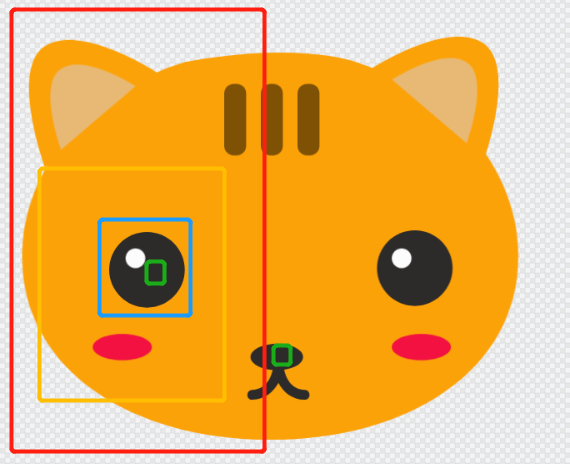 上图值得注意的是,假设上图的尺寸为1920*1080,显然各种矩形标记出的感受野并不是通过一个卷积实现的,虽然较大的卷积核能够增大感受野,但是由于计算量的增大使得运算效率下降,在工程化时我们通常不会这么做。所以增大感受野的方式,除了增大卷积核,我们也会使用更深的网络配合小卷积核、池化、空洞等方法,在更多的下采样倍率获得的高维特征上去做运算。所以在评估感受野时,我们通常会在最大感受野画幅上去对比。 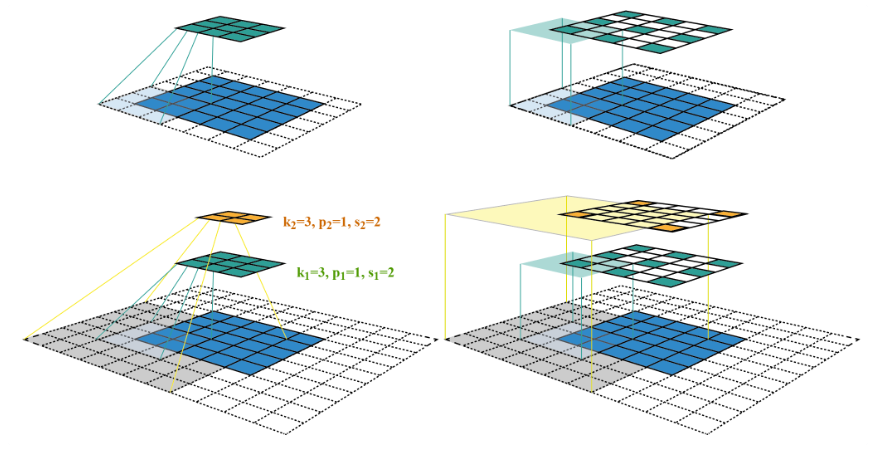 ## 1.3. 标注规范 标注规范(Annotation Guidelines)是针对数据标注(如图像、文本、音频或视频数据标记)工作制定的统一标准和规则的集合。它明确了数据在标注过程中的一致性、准确性和可重复性要求,用于指导标注人员如何对数据进行标准化的标记。例如,对于一个图像分类任务,标注规范会详细说明应当如何对某类目标进行标注、哪些特征必须标记、哪些特征可忽略、标注工具的使用方法以及标注格式等。 标注规范可以: * 统一标注标准——使不同标注人员对同一类型的数据特征有一致的理解和标记方式,减少个人理解偏差所带来的不一致性。 * 提高数据质量——晰的规则使得标注人员能够更加精确地识别和区分类别与属性,从而提高数据集的标注质量,进而提升后续模型训练和验证的可靠性。 * 可维护性和可扩展性——有了清晰的标注规范,当数据量增大或标注团队人员增多时,也能够更好地保持标注结果的一致性和可追溯性。 * 节省沟通成本——在标注团队中有了统一的文档化规范,可以减少因为理解不一致带来的沟通成本和返工成本。 标注规范通常情况下是能反映出技术方案,根据场景和模型的变化,标注规范也并不是一成不变的。对于同一种类型做什么样的标注,需要依赖于算法工程师对于场景的理解和经验。 ## 1.4 以实际场景忠遇到的问题举例 * 针对下图中的实际场景,如果我们想要针对车道线虚线的掩膜进行标注,既可以按照图1的方法进行分段标注,也可以按照图2的方法进行整体标注,并没有哪一种标注方法一定是对的,或者一定是错的。   * 但是针对上述场景我们再进一步做出分析,显然上图是一个整体图像的长宽比偏大的场景,且根据透视变换越远处,物理世界中等长的车道线在图像中的范围越小,  而隔壁车道的车道线则会因为透视关系横向变得很长。  对于实线情况,显然不需要很大的感受野我们就能轻松的分辨出导线跟路面的纹理变化而准确的识别出边界。 * 但是对于虚线场景问题就会变得复杂一些,如果采用整体标注的形式,近处的车道线之间多大的空白区域会对虚线的区域产生较大的歧义。将近图像1/2的高度所在的区域(图中红色框)被标记为了虚线,但是实际原图的纹理中并没有真实的车道线的油漆。模型即使是假设模型对原图进行了16倍下采样,320个像素变成20,在20的尺度上同样需要kernel size height超过5(区域占据1/2图像画幅)才能区分出纵向维度上的分割线,这对于模型对于小物体的识别能力也会产生影响。  而对于如下图的拐弯场景,面对画幅下横向跨度如此大的情况和地面纹理的复杂变化,一体化标注会带来更大的歧义。  所以从以上分析可以看出如果按照整体贯通的标注方式执行,会对模型的选择和能力有着更高的要求,该要求也会带来计算量的上升。 * 以下是按照上面的标注方式使用SegNeXT这样非对称卷积核(用1*7,7*1的两个卷积代替7*7的卷积)的网络,按照整体标注(左侧)得到的推理结果(右侧)。其中最后一幅图还有标注规范不一致的情况,可以看到模型在场景理解上产生了很大歧义。     * 如果按照分段方式标注呢,以上问题可以消除,但是引入的新问题是,部分透视比较大的场景原本的虚线会在最终检测中给出实线的类别判断,这是因为模型性能选择上的问题。我们可以通过多尺度等方法消除这一情况。 # Conclusion 通过以上案例可以看出,充分理解场景定义标注规范,合理选择模型,有助于避免使用数据采用大力出奇迹而导致模型泛化能力差的问题。在transformer base的方案中对于感受野的概念有所弱化,因为position embedding + multihead selfattention可以实现对全局信息的融合,不过image feature encoder仍然存在低维特征到高维特征的转化,了解以上信息仍然对我们理解深度学习模型核cv算法,从而解决实际问题有很大帮助。
dingfeng
2024年12月19日 16:11
1593
0 条评论
转发文档
收藏文档
上一篇
下一篇
评论
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码