Public Docs
【模型量化】深度学习模型量化 & 量化理论 & 各平台的量化过程 & 硬件加速
【TVM】TI关于TVM的使用测试与分析
【LLM&LVM】大模型开源工程思维导图
SmartSip
【北航卓越工程师】《汽车前沿技术导论:智能驾驶》讲义
【工具链】Yocto使用介绍——使用Yocto创建一个树莓派的系统镜像
【工具链】使用ssh+dialog指令设定服务器指定用户仅容器访问
【推理引擎】一篇关于模型推理的详细对比与学习
【推理引擎】关于TVM中的Schedule优化详解(On going)
【LLM微调】使用litgpt进行私有数据集模型微调的测试总结
【TVM】在TVM Relay中创建一个自定义操作符
【STT+LLM+TTS】如何使用语音转文字模型+大预言模型+语音生成模型完成一个类人的语音交互机器人
【RAG】 通过RAG构建垂直领域的LLM Agent的方法探索
【RAG】GraphRAG精读与测试(On going)
【AI Agent】MetaGPT精读与学习
【AI Base】Ilya Sutskever 27篇必读论文分享清单
【Nvidia】Jetson AGX Orin/ Jetson Orin nano 硬件测试调试内容(On going)
【BI/DI】LLM Using in BI Testing Scenario (On going)
【Nvidia】How to Activate a Camera on Nvidia Platform in Details
【RAS-PI】树莓派驱动开发
【行业咨询阅读】关注实时咨询和分析
【mobileye】2024 Driving AI
【mobileye】SDS_Safety_Architecture
【yolo】yolov8测试
【nvidia】Triton server实践
【alibaba】MNN(on updating)
【OpenAI】Triton(on updating)
【CAIS】关于Compound AI Systems的思考
【Nvidia】关于Cuda+Cudnn+TensorRT推理环境
【BEV】BEVDet在各个平台上的执行效率及优化(On Updating)
【Chip】AI在芯片设计和电路设计中的应用
【Chip】ChiPFormer
【Chip】关于布线的学习
【Chip】MaskPlace论文精读与工程复现优化
【gynasium】强化学习初体验
【Cadence】X AI
【transformer】MinGPT开源工程学习
【中间件】针对apollo 10.0中关于cyberRT性能优化的深度解读和思考
【Robotics】调研了解当前机器人开发者套件(on updating)
【Robotics】ROS CON China 2024 文档技术整理与感想总结(上2024.12.7,中2024.12.8,下场外产品)
【algorithm】关于模型、数据与标注规范的平衡问题
【nvidia】DLA的学习了解与使用
【nvidia】构建nvidia嵌入式平台的交叉编译环境(其他环境平台可借鉴)
【2025AI生成式大会】2025大会个人总结
【Robotics】 Create Quadruped Robot RL FootStep Training Environment In IsaacLab
【Robotics】如何一个人较为完整的完成一个机器人系统软件算法层面的设计与开发
【VLM】读懂多模态大模型评价指标
【VLM】大模型部署的端侧部署性能与精度评估方法与分析
【Nvidia】Jetson Orin 平台VLM部署方法与指标评测
【Database】向量数据库
【SoC】性能与功耗评估
【MCP】MCP探索
【InnoFrance】一个“关于声音”的有趣项目
【Robotics】写给那些想要快速了解机器人或者具身智能的工程师们
【Robotics】open X Embodiment RT-X 数据集下载与使用和分析
文档发布于【Feng's Docs】
-
+
首页
【Chip】MaskPlace论文精读与工程复现优化
# 0. Brief maskplace是基于DeepPlace等google系列基于强化学习解决元器件placement问题的进一步优化。是香港大学来耀等人在这个领域的一系列公开成果的第一个。从开源的工程到论文中的详细细节可以说整体的总结是非常清晰和详细的。当然也有一些并不完善的地方,作为一个了解相关工作的入口可以说很合适。 # 1. 论文精读 1. 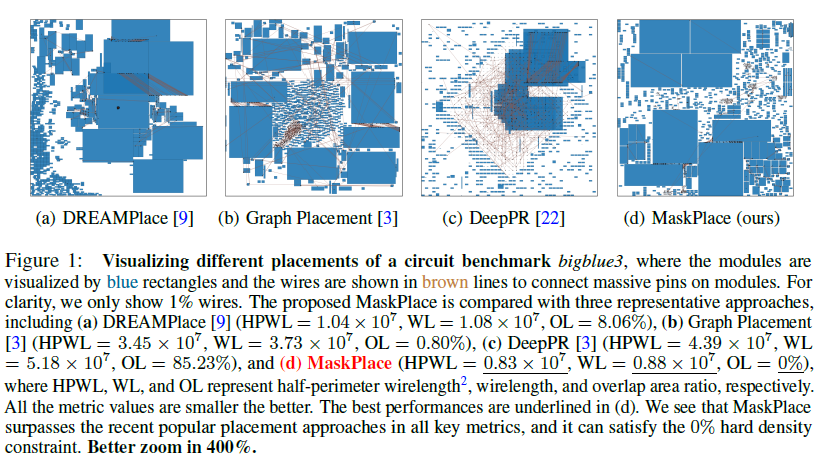 从原理图到layout,是一个非常重要需要经验的过程。通常HPWL,congestion和overlap是三个非常重要的客观指标。maskplace在ispd2005dp的数据集上,对比之前的方法,最重要的目标就是在保证没有overlap的情况下,减少HPWL。整体的结论是减少60-90%的HPWL长度。 2. 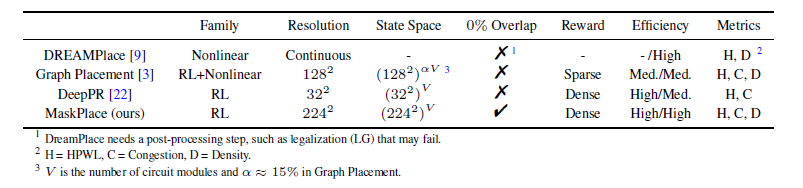 maskplace整体的放置操作完全使用强化学习(从源码中可以看到是采用openai的gym框架),分辨率相较于之前的方法有了很大提升224*224,主要是为了保证placement能在一个真实物理单位环境下进行。强约束时0% overlap。以Dense的方式作为奖励机制,目前从其他论文中可以看到强化学习使用sparse奖励的方法还是有很多的挑战。整体的元器件数量在大几十到几百个。方法从源码中可以看到,只对Macros Module进行了筛选和测试。 3. 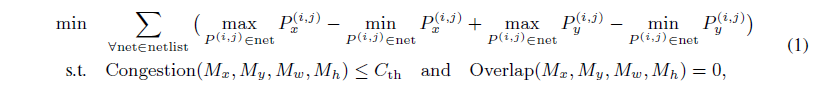 整体的约束也很直接,就是在保证Congestion满足阈值Overlap为0的情况下,HWPL最小。 4. 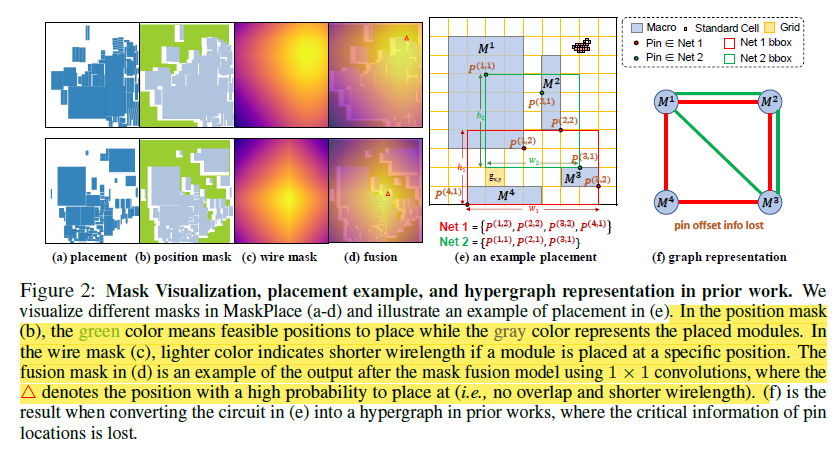 重点说一下训练过程的输入数据。 图中可以看出,作者使用了3种mask作为输入,将3种mask通过卷积进行融合后,在融合的图上预测下一步放置的最高概率位置(d)。 placement(a)也就是view mask元器件放置的位置。position mask(b)是在元器件放置后 绿色是仍可放置的位置,灰色为已经被占用的位置;wire mask(c)是基于RUDY公式统计计算得到的congestion的一个状态分布。 5. 整个使用马尔可夫过程进行建模,也就是通过T-1来预测T,而不考虑T-1之前时刻的情况。即通过逐一操作完成整个placement的过程。maskplace相比较之前方法只考虑node之间的关系的情况,也考虑到了模块pin帧位置。这个大量的网络图和pin配置就是由position mask图来表达的。  可以看到针对每一个Module种的各个pin的位置来计算得到Position Mask。Position Mask就是为了确保无overlap的出现,并且通过学习得到placement和线长的关系。由于方法需要在一个NxN (N=224in the paper)的画布上进行,这对于当N更大时,O(n²)的复杂度来说是没法接受的,所以作者又在A.3 的Appendix中详细介绍了他们将复杂度优化为O(N)的过程。 6. 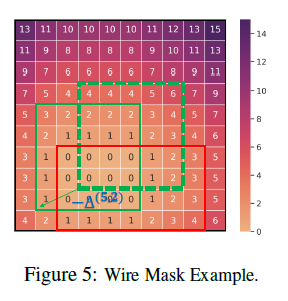 在NxN的画布上,M元器件可以摆在画布的任何位置,通过将M放置在每个位置就能得到所在位置的HPWL增加量。Wire mask精确到每个pin帧,如果在2D画布上进行计算,整体的复杂度是O(N²P)P是pin帧的总数。通过对每个pin帧在所在网络的精确曼哈顿距离进行计算。 7. 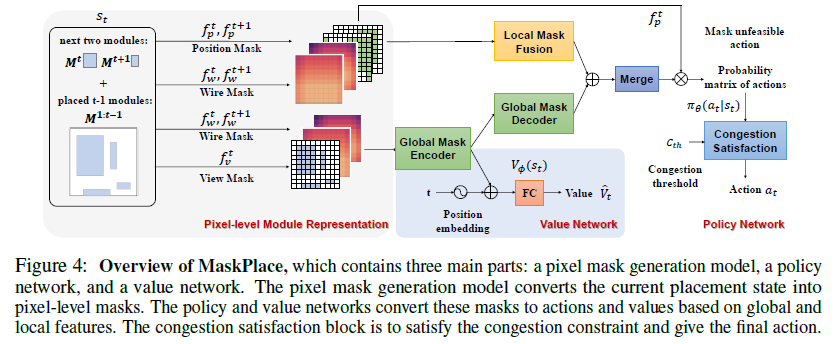 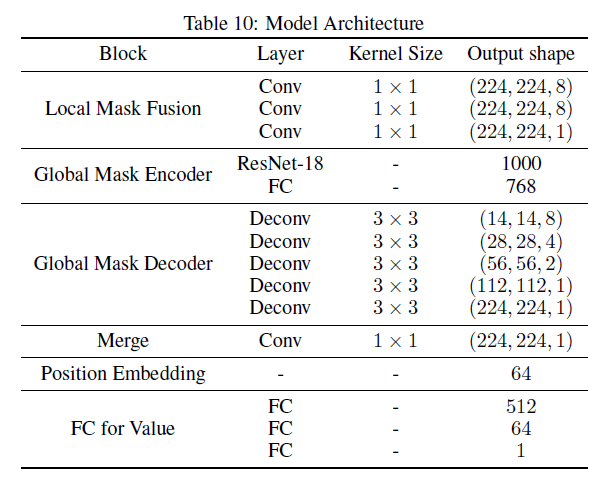 整个方法的表达。localmask是一个3层卷积,用来将信息进行降维融合。global mask是一个Resnet18的网络,用来将视觉上可区分的网格进行特征提取操作。通过反卷积操作再与localmask进行concat融合,用于概率预测。从源码可以看到,整个网络以value_loss, action_loss作为驱动,迭代更新Critic网络和Actor网络。 8.使用Actor-critic algorithms 和PPO进行训练 # 源码解读和调整 * https://github.com/laiyao1/maskplace 原作论文 * https://github.com/FengD/maskplace_custom 自己fork和更新的版本 因为源码中的工程结构不是特别清楚,所以对整体的工程也做了一定的修改。 ``` bash tree -L 1 . ├── adaptec1 (adaptec数据) ├── adaptec2 ├── adaptec3 ├── adaptec4 ├── ariane(netlist定义 protobuf解析等) ├── bigblue1(bigblue 数据) ├── bigblue2 ├── bigblue3 ├── bigblue4 ├── comp_res.py (用于与benchmark比较结果,计算hpwl和cost) ├── config.py (由我添加,用来将所有静态参数统一,避免原作者各种相同参数在不同文件中单独定义,出现不统一的情况) ├── figures(输出结果图片) ├── gg_place_new(输出结果布局) ├── ibm01(ibm数据) ├── ibm02 ├── ibm03 ├── ibm04 ├── ibm05 ├── ibm06 ├── logs(每次训练日志,用来记录一次训练中的iter和hpwl cost) ├── model(预训练的resnet18模型) ├── place_db_proto.py(解析circuit benchmark) ├── place_db.py(解析circuit benchmark) ├── place_env(定义placement的强化学习环境,使用gym) ├── placement_model.py(placement的Actor Critic的模型结构,原作者合并在PPO2.py中) ├── PPO2.py(入口文件) ├── prim.py(计算整个图的cost) ├── save_models(保存模型的结果) ├── tb_log(tensorboard log) └── tools(我自定义的一些工具文件) ``` 核心关注placement_model和PPO2两个文件,如果要修改强化学习策略重点关注place_env模块 源码中其中有几点值得注意: 1. 在PPO入口中,作者自定义了一个PPO过程,不确定过程中是否有出入; 2. 在comp_res中 hpwl中关于max_height的计算,人为* 1.1的系数,这个系数比较草率不确定来由; 3. 模型定义采用的是224 *224的结构,但是后面chipformer用的是84 * 84的结果,这部分的调整和maskplace本身生成数据的性能影响值得商榷和复现; 4. 重点是关于数据反传和模型更新。源码中如果设置is_test得话,只是进行了一步单独的test过程,和train步骤使用同样的布局更新逻辑。 如下所示,这个过程action通过select_action获得,但是select_action中使用Categorical计算action probs后,通过sample函数随机获取action,这个过程在训练时可以加速模型收敛,但是无法稳定复现最优结果。并且在我使用select_action2的方案进行替换时发现,通过actor_net获得的结果仍然不稳定,这说明环境在更新时可能还是存在随机性,我个人理解这数据环境bug,这部分结果直接影响结果正确性。 ``` python done = False while done is False: state_tmp = state.copy() action, action_log_prob = agent.select_action(state) next_state, reward, done, info = env.step(action) # assert next_state.shape == (config.num_state, ) reward_intrinsic = 0 trans = Transition(state_tmp, action, reward / 200.0, action_log_prob, next_state, reward_intrinsic) if agent.store_transition(trans): assert done == True agent.update() score += reward raw_score += info["raw_reward"] state = next_state if i_epoch == 0: running_reward = score running_reward = running_reward * 0.9 + score * 0.1 # print("score = {}, raw_score = {}".format(score, raw_score)) ``` ``` python # def select_action(self, state): # state = torch.from_numpy(state).float().to(device).unsqueeze(0) # with torch.no_grad(): # action_probs, _ = self.actor_net(state) # dist = Categorical(action_probs) # action = dist.sample() # action_log_prob = dist.log_prob(action) # return action.item(), action_log_prob.item() def select_action2(self, state, deterministic=False): """ Select an action based on the current policy. Args: state (numpy.ndarray): The current state. deterministic (bool): If True, select the action with the highest probability. If False, sample from the probability distribution. Returns: action (int): The selected action. action_log_prob (float): The log probability of the selected action. """ state = torch.from_numpy(state).float().to(device).unsqueeze(0) with torch.no_grad(): action_probs, _ = self.actor_net(state) if deterministic: action_probs = torch.clamp(action_probs, 1e-6, 1.0) # Select the action with the highest probability action = torch.argmax(action_probs, dim=-1) action_log_prob = torch.log(action_probs[0, action]) else: # Sample from the probability distribution dist = Categorical(action_probs) action = dist.sample() action_log_prob = dist.log_prob(action) return action.item(), action_log_prob.item() ``` # 2. 适配chipFormer 从论文ChipFormer中可以获得如下信息: 1. maskplace的布局策略为stochastic policy即随机策略(从源代码中的select action部分也可以看到为基于action probability的随机采样),按照迭代策略,经过大几千次的online training能够获得一个最优解,但是无法保证该结果可复现。不过该策略可以给chipformer需要的专家数据的token输入作为结果使用; 2. 原作者的论文和源码中,maskplace的grid为224, 而chipformer的grid使用的是84,所以这里要进行调整和修改。对于线性层等都不受影响,对于resnet也没影响,唯一需要调整的是反卷积部分,这里我的修改逻辑是保留原作者的5层结果,输出通道从16逐层递减收敛到1,将原来14,28,56,112,224改为14,28,84,84,84。完成后即可正常开展训练。 3. 完成数据适配之后,就是将需要的结果导出pkl适配chipformer中的expertdata。通过打印expertdata,的内容可得到如下结果,以及他们对应的维度,然后如果想要驱动chipformer就是把对应的结果从maskplace中保存下来。5120是pkl数据的维度,对应maskplace的buffer_capacity。 * meta_observations 6 * 5120 float * observations 84 * 84 * 5120 bool (view mask) * obs_wire_mask 84 * 84 * 5120 float * obs_pos_mask 84 * 84 * 5120 bool * actions 1 * 5120 int * rewards 1 * 5120 float * raw_rewards 1 * 5120 int(not in pkl) * terminals 1 * 5120 bool * benchmarks 1 * 5120 int(not in pkl) * levels 1 * 5120 int(not in pkl) * lengths 1 * 5120 int
dingfeng
2024年12月9日 17:15
1405
0 条评论
转发文档
收藏文档
上一篇
下一篇
评论
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码